Linux文件系统(四)---三大缓冲区之inode缓冲区 (内存inode映像 )
在文件系统中,有三大缓冲为了提升效率:inode缓冲区、dentry缓冲区、块缓冲。
(内核:2.4.37)
一、inode缓冲区
为了加快对索引节点的索引,引入inode缓冲区,下面我们看Linux/fs/inode.c代码。inode缓冲区代码
1、一些数据结构:
之前已经说过,有多个链表用于管理inode节点:
<span style="font-size:14px;">59 static LIST_HEAD(inode_in_use); 60 static LIST_HEAD(inode_unused); 61 static LIST_HEAD(inode_unused_pagecache); 62 static struct list_head *inode_hashtable; 63 static LIST_HEAD(anon_hash_chain); /* for inodes with NULL i_sb */</span>inode_in_use:正在使用的inode,即有效的inode,i_count > 0且i_nlink > 0。
inode_unused:有效的节点,但是还没有使用,处于空闲状态。(数据不在pagecache中)。
inode_unused_pagecache:同上。(数据在pagecache中)。
inode_hashtable:用于inode在hash表中,提高查找效率。
anon_hash_chain:用于超级块是空的的inodes。例如:sock_alloc()函数, 通过调用fs/inode.c中get_empty_inode()创建的套接字是一个匿名索引节点,这个节点就加入到了anon_hash_chain链表。
dirty:用于保存超级块中的所有的已经修改的inodes。
<span style="font-size:14px;"> 76 struct inodes_stat_t inodes_stat; 77 78 static kmem_cache_t * inode_cachep;</span>上面的两个字段:
inodes_stat:记录inodes节点的状态。
inode_cachep:对inodes对象的缓存块。
2、基本初始化:初始化inode哈希表头和slab内存缓存块
索引节点高速缓存的初始化是由inode_init()实现的,现在看看下面代码:
<span style="font-size:14px;">1296 /*
1297 * Initialize the hash tables.
1298 */
1299 void __init inode_init(unsigned long mempages) /* 参数:表示inode缓存使用的物理页面数 */
1300 {
1301 struct list_head *head;
1302 unsigned long order;
1303 unsigned int nr_hash;
1304 int i;
1305 /* 下面的一段操作就是根据PAGE_SHIFT,PAGE_SIZE给hash表分配空间 */
1306 mempages >>= (14 - PAGE_SHIFT);
1307 mempages *= sizeof(struct list_head);
1308 for (order = 0; ((1UL << order) << PAGE_SHIFT) < mempages; order++)
1309 ;
1310
1311 do {
1312 unsigned long tmp;
1313
1314 nr_hash = (1UL << order) * PAGE_SIZE /
1315 sizeof(struct list_head);
1316 i_hash_mask = (nr_hash - 1);
1317
1318 tmp = nr_hash;
1319 i_hash_shift = 0;
1320 while ((tmp >>= 1UL) != 0UL)
1321 i_hash_shift++;
1322 /* inode_hashtable是一个全局变量,用于hash表,上面说过,需要预定order页的内存作为inode-hash表使用 */
1323 inode_hashtable = (struct list_head *)
1324 __get_free_pages(GFP_ATOMIC, order);
1325 } while (inode_hashtable == NULL && --order >= 0);
1326
1327 printk(KERN_INFO "Inode cache hash table entries: %d (order: %ld, %ld bytes)\n",
1328 nr_hash, order, (PAGE_SIZE << order));
1329 /* 如果分配不成功就失败 */
1330 if (!inode_hashtable)
1331 panic("Failed to allocate inode hash table\n");
1332 /* 下面就是初始化每个inde-hash节点 */
1333 head = inode_hashtable;
1334 i = nr_hash;
1335 do {
1336 INIT_LIST_HEAD(head);
1337 head++;
1338 i--;
1339 } while (i);
1340
1341 /* inode slab cache:创建一个inode的slab缓存,以后的inode缓存都从这个slab中进行分配 */
1342 inode_cachep = kmem_cache_create("inode_cache", sizeof(struct inode),
1343 0, SLAB_HWCACHE_ALIGN, init_once,
1344 NULL);
1345 if (!inode_cachep)
1346 panic("cannot create inode slab cache");
1347
1348 unused_inodes_flush_task.routine = try_to_sync_unused_inodes;
1349 }
1350</span>
注意上面的逻辑,说明两个问题:
1). 第一初始化inode_hashtable作为链表的头。
2). 初始化inode的slab缓存,也就是说,如果我需要分配一个inode缓存在内存中,那么都从这个inode_cachep中分配一个inode内存节点。然后统一加入到这个inode_hashtable中进行管理!也就是所谓的创建inode slab分配器缓存。
下面看看具体的缓存的分配过程:
先看init_once函数:
<span style="font-size:14px;">169 static void init_once(void * foo, kmem_cache_t * cachep, unsigned long flags)
170 {
171 struct inode * inode = (struct inode *) foo;
172
173 if ((flags & (SLAB_CTOR_VERIFY|SLAB_CTOR_CONSTRUCTOR)) ==
174 SLAB_CTOR_CONSTRUCTOR)
175 inode_init_once(inode);
176 }</span>
注意:在上面的kmem_cache_create函数中,执行的顺序是:
---> kmem_cache_create(里面重要的一步是cachep->ctor = ctor; cachep->dtor = dtor;)
---> kmem_cache_alloc
---> __kmem_cache_alloc
---> kmem_cache_grow(里面一个重要设置是:ctor_flags = SLAB_CTOR_CONSTRUCTOR;)
---> kmem_cache_init_objs:里面会执行cachep->ctor(objp, cachep, ctor_flags);
这样最终就跳转到上面的init_once函数中了!在init函数中执行的是inode_init_once函数:
<span style="font-size:14px;">141 /*
142 * These are initializations that only need to be done
143 * once, because the fields are idempotent across use
144 * of the inode, so let the slab aware of that.
145 */
146 void inode_init_once(struct inode *inode)
147 {
148 memset(inode, 0, sizeof(*inode));
149 __inode_init_once(inode);
150 }</span>
<span style="font-size:14px;">152 void __inode_init_once(struct inode *inode)
153 {
154 init_waitqueue_head(&inode->i_wait);
155 INIT_LIST_HEAD(&inode->i_hash);
156 INIT_LIST_HEAD(&inode->i_data.clean_pages);
157 INIT_LIST_HEAD(&inode->i_data.dirty_pages);
158 INIT_LIST_HEAD(&inode->i_data.locked_pages);
159 INIT_LIST_HEAD(&inode->i_dentry);
160 INIT_LIST_HEAD(&inode->i_dirty_buffers);
161 INIT_LIST_HEAD(&inode->i_dirty_data_buffers);
162 INIT_LIST_HEAD(&inode->i_devices);
163 sema_init(&inode->i_sem, 1);
164 sema_init(&inode->i_zombie, 1);
165 init_rwsem(&inode->i_alloc_sem);
166 spin_lock_init(&inode->i_data.i_shared_lock);
167 }</span>
3、注意知道现在我们主要说了上面的两个基本的问题(红字部分),但是这只是一个框架而已,对于具体的一个文件系统来说怎么个流程,下面需要看看!
我们以最常见的ext2作为说明:
现在一个ext2类型的文件系统想要创建一个inode,那么执行:ext2_new_inode函数
<span style="font-size:14px;">314 struct inode * ext2_new_inode (const struct inode * dir, int mode)
315 {
316 struct super_block * sb;
317 struct buffer_head * bh;
318 struct buffer_head * bh2;
319 int group, i;
320 ino_t ino;
321 struct inode * inode;
322 struct ext2_group_desc * desc;
323 struct ext2_super_block * es;
324 int err;
325
326 sb = dir->i_sb;
327 inode = new_inode(sb); /* 创建一个inode节点,这个函数就是在fs/inode.c中的new_inode函数 */
328 if (!inode)
329 return ERR_PTR(-ENOMEM);
330
331 lock_super (sb);
332 es = sb->u.ext2_sb.s_es;
333 repeat:
334 if (S_ISDIR(mode))
335 group = find_group_dir(sb, dir->u.ext2_i.i_block_group);
336 else
337 group = find_group_other(sb, dir->u.ext2_i.i_block_group);
338
339 err = -ENOSPC;
340 if (group == -1)
341 goto fail;
342
343 err = -EIO;
344 bh = load_inode_bitmap (sb, group);
345 if (IS_ERR(bh))
346 goto fail2;
347
348 i = ext2_find_first_zero_bit ((unsigned long *) bh->b_data,
349 EXT2_INODES_PER_GROUP(sb));
350 if (i >= EXT2_INODES_PER_GROUP(sb))
351 goto bad_count;
352 ext2_set_bit (i, bh->b_data);
353
354 mark_buffer_dirty(bh);
355 if (sb->s_flags & MS_SYNCHRONOUS) {
356 ll_rw_block (WRITE, 1, &bh);
357 wait_on_buffer (bh);
358 }
359
360 ino = group * EXT2_INODES_PER_GROUP(sb) + i + 1;
361 if (ino < EXT2_FIRST_INO(sb) || ino > le32_to_cpu(es->s_inodes_count)) {
362 ext2_error (sb, "ext2_new_inode",
363 "reserved inode or inode > inodes count - "
364 "block_group = %d,inode=%ld", group, ino);
365 err = -EIO;
366 goto fail2;
367 }
368
369 es->s_free_inodes_count =
370 cpu_to_le32(le32_to_cpu(es->s_free_inodes_count) - 1);
371 mark_buffer_dirty(sb->u.ext2_sb.s_sbh);
372 sb->s_dirt = 1;
373 inode->i_uid = current->fsuid;
374 if (test_opt (sb, GRPID))
375 inode->i_gid = dir->i_gid;
376 else if (dir->i_mode & S_ISGID) {
377 inode->i_gid = dir->i_gid;
378 if (S_ISDIR(mode))
379 mode |= S_ISGID;
380 } else
381 inode->i_gid = current->fsgid;
382 inode->i_mode = mode;
383
384 inode->i_ino = ino;
385 inode->i_blksize = PAGE_SIZE; /* This is the optimal IO size (for stat), not the fs block size */
386 inode->i_blocks = 0;
387 inode->i_mtime = inode->i_atime = inode->i_ctime = CURRENT_TIME;
388 inode->u.ext2_i.i_state = EXT2_STATE_NEW;
389 inode->u.ext2_i.i_flags = dir->u.ext2_i.i_flags & ~EXT2_BTREE_FL;
390 if (S_ISLNK(mode))
391 inode->u.ext2_i.i_flags &= ~(EXT2_IMMUTABLE_FL|EXT2_APPEND_FL);
392 inode->u.ext2_i.i_block_group = group;
393 ext2_set_inode_flags(inode);
394 insert_inode_hash(inode); /* 将这个新的inode内存节点挂在hashtable中,这个函数在fs/inode.c中的insert_inode_hash函数 */
395 inode->i_generation = event++;
396 mark_inode_dirty(inode);
397
398 unlock_super (sb);
399 if(DQUOT_ALLOC_INODE(inode)) {
400 DQUOT_DROP(inode);
401 inode->i_flags |= S_NOQUOTA;
402 inode->i_nlink = 0;
403 iput(inode);
404 return ERR_PTR(-EDQUOT);
405 }
406 ext2_debug ("allocating inode %lu\n", inode->i_ino);
407 return inode;
408
409 fail2:
410 desc = ext2_get_group_desc (sb, group, &bh2);
411 desc->bg_free_inodes_count =
412 cpu_to_le16(le16_to_cpu(desc->bg_free_inodes_count) + 1);
413 if (S_ISDIR(mode))
414 desc->bg_used_dirs_count =
415 cpu_to_le16(le16_to_cpu(desc->bg_used_dirs_count) - 1);
416 mark_buffer_dirty(bh2);
417 fail:
418 unlock_super(sb);
419 make_bad_inode(inode);
420 iput(inode);
421 return ERR_PTR(err);
422
423 bad_count:
424 ext2_error (sb, "ext2_new_inode",
425 "Free inodes count corrupted in group %d",
426 group);
427 /* Is it really ENOSPC? */
428 err = -ENOSPC;
429 if (sb->s_flags & MS_RDONLY)
430 goto fail;
431
432 desc = ext2_get_group_desc (sb, group, &bh2);
433 desc->bg_free_inodes_count = 0;
434 mark_buffer_dirty(bh2);
435 goto repeat;
436 }</span>
这个函数比较复杂,但是我们主要看327行和394行,就是创建一个inode内存节点,然后将这个inode插入inode_hashtable中!
这个函数具体的解释不再看了,现在主要从这两个函数入手:
1). fs/inode.c中的new_inode函数,创建一个inode内存节点:
<span style="font-size:14px;">964 struct inode * new_inode(struct super_block *sb)
965 {
966 static unsigned long last_ino;
967 struct inode * inode;
968
969 spin_lock_prefetch(&inode_lock);
970
971 inode = alloc_inode(sb);/* 这个是主要的分配函数 */
972 if (inode) {
973 spin_lock(&inode_lock);
974 inodes_stat.nr_inodes++; /* inode_stat是一个所有节点状态字段,这里表明增加了一个新的inode */
975 list_add(&inode->i_list, &inode_in_use); /* 将这个inode加入到正在使用的链表中:inode_use链表 */
976 inode->i_ino = ++last_ino; /* 给这个inode分配一个inode号! */
977 inode->i_state = 0;
978 spin_unlock(&inode_lock);
979 }
980 return inode;
981 }</span>
看看这个alloc_inode函数:
<span style="font-size:14px;"> 80 static struct inode *alloc_inode(struct super_block *sb)
81 {
82 static struct address_space_operations empty_aops;
83 static struct inode_operations empty_iops;
84 static struct file_operations empty_fops;
85 struct inode *inode;
86
87 if (sb->s_op->alloc_inode) /* 如果提供了自己的分配函数,那么这个文件系统自己分配去~~~,具体不多说 */
88 inode = sb->s_op->alloc_inode(sb);
89 else {
90 inode = (struct inode *) kmem_cache_alloc(inode_cachep, SLAB_KERNEL);/* 这个就是通用的分配函数,从我们初始化好的inode_cache中分配 */
91 /* will die */
92 if (inode)
93 memset(&inode->u, 0, sizeof(inode->u));
94 }
95 /* 下面初始化的东西就不多说了 */
96 if (inode) {
97 struct address_space * const mapping = &inode->i_data;
98
99 inode->i_sb = sb;
100 inode->i_dev = sb->s_dev;
101 inode->i_blkbits = sb->s_blocksize_bits;
102 inode->i_flags = 0;
103 atomic_set(&inode->i_count, 1);
104 inode->i_sock = 0;
105 inode->i_op = &empty_iops;
106 inode->i_fop = &empty_fops;
107 inode->i_nlink = 1;
108 atomic_set(&inode->i_writecount, 0);
109 inode->i_size = 0;
110 inode->i_blocks = 0;
111 inode->i_bytes = 0;
112 inode->i_generation = 0;
113 memset(&inode->i_dquot, 0, sizeof(inode->i_dquot));
114 inode->i_pipe = NULL;
115 inode->i_bdev = NULL;
116 inode->i_cdev = NULL;
117
118 mapping->a_ops = &empty_aops;
119 mapping->host = inode;
120 mapping->gfp_mask = GFP_HIGHUSER;
121 inode->i_mapping = mapping;
122 }
123 return inode;
124 }</span>
我们主要看87行和90行!看了注释也就明白了!第一种是文件系统也就是这个超级快提供了分配函数,那么就这个文件系统按照自己的意愿去分配,如果没有,那么就是要用这个通用的分配函数inode = (struct inode *) kmem_cache_alloc(inode_cachep, SLAB_KERNEL);这个函数其实很简单,其实就是在我们已经初始化好的这个inode_cache中分配一个inode内存块出来。
2). fs/inode.c中的insert_inode_hash函数,将新的分配的inode插入到inode_hashtable中:
<span style="font-size:14px;">1166 void insert_inode_hash(struct inode *inode)
1167 {
1168 struct list_head *head = &anon_hash_chain; /* anon_hash_chain是代表没有超级块的inode链表(有些临时的inode无需超级块) */
1169 if (inode->i_sb)
1170 head = inode_hashtable + hash(inode->i_sb, inode->i_ino); /* 这个是正常的插入 */
1171 spin_lock(&inode_lock);
1172 list_add(&inode->i_hash, head);
1173 spin_unlock(&inode_lock);
1174 }</span>
注意这个hash表其实就可以看做是一个数组链表组合体,如图所示:
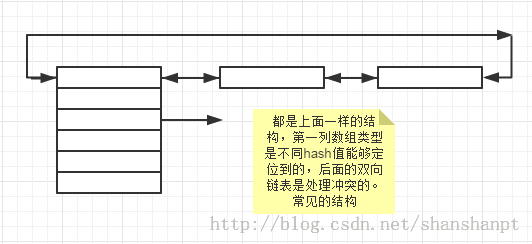
head = inode_hashtable + hash(inode->i_sb, inode->i_ino);这一行就是通过这个hash函数算出hash值,找到这个inode应该放在哪一列。譬如定位到第三列,那么第三列中的都是hash值相同的inode。然后所有的这列inode都是构成双向链表的。注意inode中的i_hash字段就做这个事的!!list_add(&inode->i_hash, head);函数就是将hash值相同的inode构成双向链表。
看一下这个具体的hash函数(inode.c中):
<span style="font-size:14px;">1043 static inline unsigned long hash(struct super_block *sb, unsigned long i_ino)
1044 {
1045 unsigned long tmp = i_ino + ((unsigned long) sb / L1_CACHE_BYTES);
1046 tmp = tmp + (tmp >> I_HASHBITS);
1047 return tmp & I_HASHMASK;
1048 }</span>
OK,上面的具体的inode创建和加入的流程基本清楚了。具体创建的过程是涉及到内存这一块的,不多说了。
4. 下面看看给一个怎么去找到一个inode,涉及ilookup函数:
<span style="font-size:14px;">1102 struct inode *ilookup(struct super_block *sb, unsigned long ino)
1103 {
1104 struct list_head * head = inode_hashtable + hash(sb,ino);/* 获得hash值 */
1105 struct inode * inode;
1106
1107 spin_lock(&inode_lock);
1108 inode = find_inode(sb, ino, head, NULL, NULL); /* 寻找inode */
1109 if (inode) {
1110 __iget(inode);
1111 spin_unlock(&inode_lock);
1112 wait_on_inode(inode);
1113 return inode;
1114 }
1115 spin_unlock(&inode_lock);
1116
1117 return inode;
1118 }</span>
这个函数其实比较简单了,首先还是获得这个inode的hash值定位,然后开始finde_inode:
<span style="font-size:14px;">929 static struct inode * find_inode(struct super_block * sb, unsigned long ino, struct list_head *head, find_inode_t find_actor, void *opaque)
930 {
931 struct list_head *tmp;
932 struct inode * inode;
933
934 repeat:
935 tmp = head;
936 for (;;) {
937 tmp = tmp->next;
938 inode = NULL;
939 if (tmp == head) /*双向循环链表结束条件*/
940 break;
941 inode = list_entry(tmp, struct inode, i_hash); /*获得链表中一个inode*/
942 if (inode->i_ino != ino) /*是否找到*/
943 continue;
944 if (inode->i_sb != sb) /*是否合理:是不是我需要的super_block中的inode*/
945 continue;
946 if (find_actor && !find_actor(inode, ino, opaque)) /*这个是一个查找函数指针,用户定义的一些规则是否满足*/
947 continue;
948 if (inode->i_state & (I_FREEING|I_CLEAR)) { /*注意inode节点的状态如果是free或者clear,那么等free之后再重新找*/
949 __wait_on_freeing_inode(inode);
950 goto repeat;
951 }
952 break;
953 }
954 return inode; /*返回找到的inode节点*/
955 }</span>
上面函数最核心的本质不就是双向链表的查找么,OK。
最后:关于inode怎么工作的,将会在后面的分析ext2代码中在详细研究。