Python爬虫框架--pyspider初体验
之前接触scrapy本来是想也许scrapy能够让我的爬虫更快,但是也许是我没有掌握scrapy的要领,所以爬虫运行起来并没有我想象的那么快,看这篇文章就是之前使用scrapy的写得爬虫。然后昨天我又看到了pyspider,说实话本来只是想看看,但是没想到一看就让我喜欢上了pyspider。
先给大家看一下pyspider的后台截图:
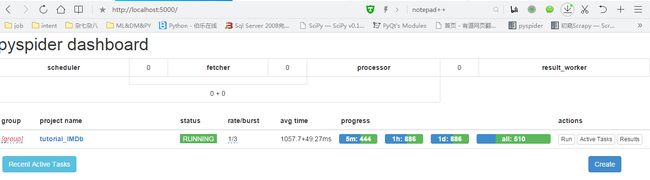
pyspider是国人写的一款开源爬虫框架,个人觉得这个框架用起来很方便,至于如何方便可以继续看下去。
作者博客:http://blog.binux.me/
这篇文章是我照着作者的这篇文章所做,爬取得是豆瓣电影,我也照着爬豆瓣电影,但是原文章有些地方不再适用,这里我会有些改正,以适应网页所发生的变化。
安装pyspider
安装pyspider:pip install pyspider
目测pyspider只支持32位系统,因为安装pyspider前需要先安装一个依赖库:pycurl,而pycurl只支持32位系统,虽然我也在csdn找到别人重新编译过的pycurl,能够在64位安装,然后pyspider也确实安装上去了,但是并不完美!!这里说一下,不完美处就是无法进行调试!!调试很重要吧?
抱着对pyspider的喜爱,我就果断的重装系统了!
如果你是32位系统,就这样安装:
pip install pycurl
pip install pyspider如果你是64位系统,且不是强迫症,能够接受不完美的事物,就这样安装:
下载重新编译过的pycurl,然后安装。
然后cmd输入:pip install pyspider
第一个pyspider爬虫
- 打开cmd,输入pyspider,然后打开浏览器输入:http://localhost:5000, 然后就可以进入pyspider的后台了。
 第一次打开后台是一片空白的。(点开浏览器后cmd不要关了!)
第一次打开后台是一片空白的。(点开浏览器后cmd不要关了!) - 点击Create,随便输入一个名字(当然名字还是不要乱取)。

- 点击确定之后就进入一个脚本编辑器了创建项目的时候也自动创建了一个脚本,这里我们只需要改动脚本OK。我们要爬豆瓣的所有电影,选择http://movie.douban.com/tag/为起始点,也就是从这里开始爬。
- 首先是改动
on_start
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://movie.douban.com/tag/', callback=self.index_page)这里没什么讲的,改个网址而已,callback就是调用下一个函数开始这个起始网页。
5. 改动index_page函数
我们先来看一下启示网页张怎样?
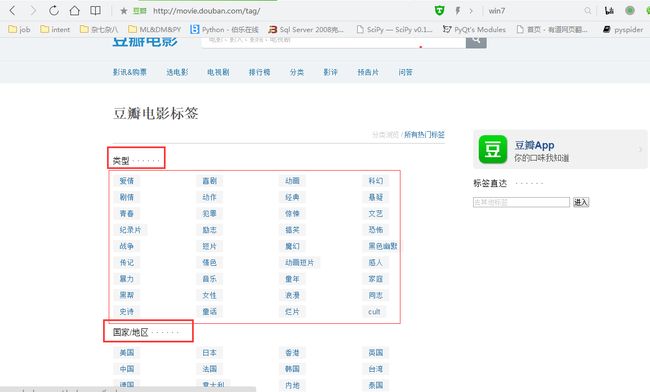
有按类型分类,也有按国家/地区分类,还有按年代分类。我们可以选择按国家/地区分类,也可以选择按年代分类,最好不选择按类型分类,因为同一部电影既可能是爱情片、又可能是动作片(感觉怪怪的)。我这里选择按年代分类。
先看一下index_page我是怎么改的。
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('#content>div>div.article> table:nth-child(9)>tbody>tr>td>a').items():
a=each.attr.href.replace('www','movie')
self.crawl(a,callback=self.list_page)可以看到我们是从response.doc之中选择tag的,然后
#content>div>div.article> table:nth-child(9)>tbody>tr>td>a
熟悉css selector的朋友可能会很熟悉这种东西,然而我是第一次接触,所以讲不出个所以然来。其实css selector跟正则表达式、xpath一样,也是一种内容选择的方法,然后也很好理解这是什么意思。
这是分隔符,熟悉css selector的朋友可以不用看下面的部分
我们先看一下
http://movie.douban.com/tag/
我们要选择的是2013、2012到1989这部分内容,那么我们右键选择2013然后审查元素
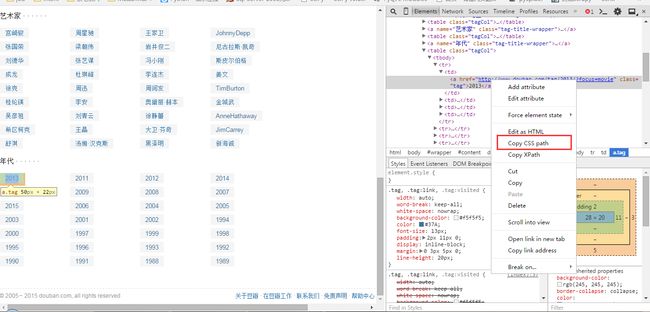
然后在链接中右键选择copy css path得到一个然后复制到文本中,我们选多几个tag的css path,查看一下规律
 可以看到选中的几个tag的css path不同点就在我红线标出的地方,那么我们把他们的不同之处去掉,只留下相同的部分,也就是最下面的一行,把他复制下来,放到
可以看到选中的几个tag的css path不同点就在我红线标出的地方,那么我们把他们的不同之处去掉,只留下相同的部分,也就是最下面的一行,把他复制下来,放到
for each in response.doc('#content>div>div.article> table:nth-child(9)>tbody>tr>td>a').items()括号里面,告诉爬虫,我们要爬的部分在这个path下!
这就是一个得到css path的方法,就连我这个第一次接触css selector的人都可以找到
下面回归
接着是
a=each.attr.href.replace('www','movie')
self.crawl(a,callback=self.list_page)我们先把符合上面css path规则的部分进行了替换,把www替换为了movie。为什么这样做呢?我们分别打开
http://www.douban.com/tag/2013/?focus=movie
和
http://movie.douban.com/tag/2013/?focus=movie
来看。
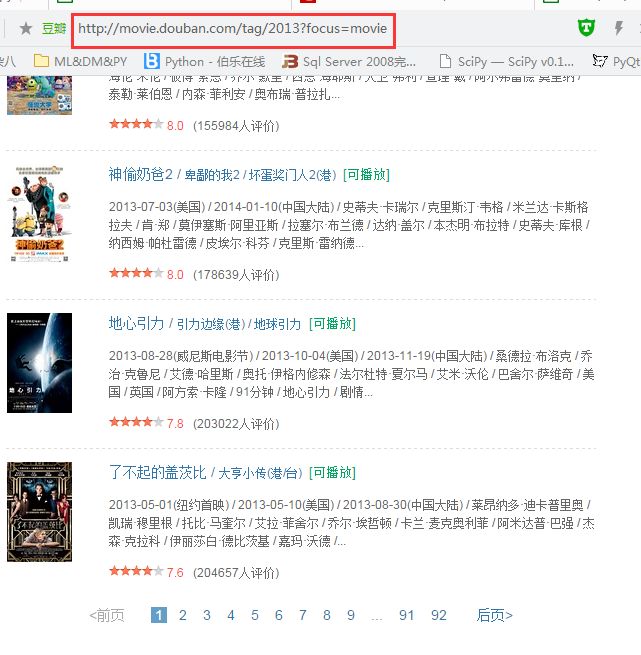
可以看到www的是没有翻页的!!!而movie的是有翻页的!!!我们要遍历所有电影,当然要有翻页了!!!所以这就是替换的原因所在!
self.crawl(a,callback=self.list_page)这段代码就是把得到的类似http://movie.douban.com/tag/2013?focus=movie的网页交给了下一个函数去解析了!
- 改动list_page函数
@config(age=10*24*60*60)
def list_page(self,response):
#获得电影详细内容链接并交给下一个函数处理
for each in response.doc('td > .pl2 > a').items():
self.crawl(each.attr.href,callback=self.detail_page)
#翻页,然后继续由list_page函数处理
for each in response.doc('.next > a').items():
self.crawl(each.attr.href,callback=self.list_page)这里的css path我是有pyspider自带的css selector helper得到的。说到这里就再讲一下pyspider自带的css selector helper怎么用(当然这不是万能的,要不然上面我也不会用浏览器的审查元素进行获取css path)
我们先点击脚本编辑器的中间上方的run
选择follows,看到这样的
点击箭头继续。
顺便说一下,如果点击箭头follows就没有链接了,那么说明你上一个函数的css path没有选对!回去修改!!
到这里再选一个链接的箭头继续。回到web下。
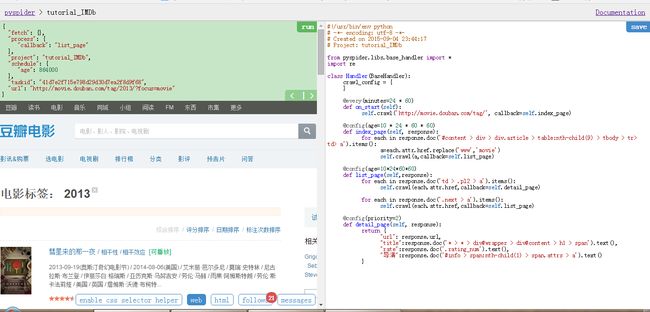
我们改动list_page的任务有两个,一个是选择一个电影的详细内容的链接交给下一个函数处理,还有一个就是翻页继续由list_page函数处理。
选择enable css selector path然后点击一个电影链接,就会发现所有的电影链接都被红框框给框起来了!
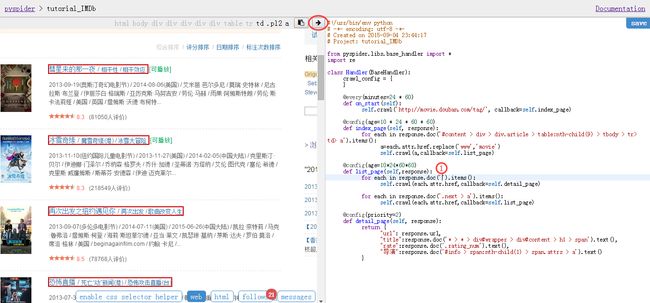
我们把鼠标选择到图中一处,然后点击网页中间上方的箭头,也就是图中标出的地方,然后就把网页详细内容链接的css path添加进来了!
同理可以把翻页的css path得到。
8.改动detail_page函数
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title":response.doc('* > * > div#wrapper > div#content > h1 > span').text(),
"rate":response.doc('.rating_num').text(),
"导演":response.doc('#info > span:nth-child(1) > span.attrs > a').text()
}这个就简单了,已经到了电影详细内容网页,就看你要什么内容,然后利用css selector helper进行选择就可以了!我这里只返回了url、电影标题、评分和导演四项!
到这里,爬虫基本上写完了,点击save,返回dashboard,把爬虫的状态改成Running或者debug,然后再点击右方的run,爬虫就启动了!!
另外这里还有很多的demo哦!http://demo.pyspider.org/
初体验完毕!本人语文不好,讲述得不好!只能利用大量图片进行讲述,如有不懂之处可以评论。