Hadoop--ZooKeeper
4 ZooKeeper
4.1 概述
Zookeeper 是 Google 的 Chubby一个开源的实现,是 Hadoop 的分布式协调服务。它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。
为什么使用Zookeeper
1)大部分分布式应用需要一个主控、协调器或控制器来管理物理分布的子进程(如资源、任务分配等)
2)目前,大部分应用需要开发私有的协调程序,缺乏一个通用的机制
3)协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器
ZooKeeper可以提供通用的分布式锁服务,用以协调分布式应用。在Hadoop2.x中,使用Zookeeper的事件处理确保整个集群只有一个活跃的NameNode,存储配置信息等。
4.2 安装和配置
4.2.1 解压
4.2.2 配置(现在一台节点上配置)
1.了解并修改zoo.cfg
zookeeper的默认配置文件为zookeeper/conf/zoo_sample.cfg,需要先将其修改为zoo.cfg(mv zoo_sample.cfg zoo.cfg)。现在解释下:
1)tickTime:CS通信心跳时间
Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每隔 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。
tickTime=2000
2)initLimit:LF初始通信时限
集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
initLimit=5
3)syncLimit:LF同步通信时限
集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
syncLimit=2
4)dataDir:数据文件目录
Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。
修改dataDir:
dataDir=/usr/zookeeper/zookeeper-3.4.5/data
5)clientPort:客户端连接端口
客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
clientPort=2181
6)服务器名称与地址:集群信息(服务器编号,服务器地址,LF通信端口,选举端口)
这个配置项的书写格式比较特殊,规则如下:
server.N=YYY:A:B
添加如下信息:
server.1=H01:2888:3888
server.2=H02:2888:3888
server.3=H01:2888:3888
2.在(dataDir=/usr/zookeeper/zookeeper-3.4.5/data)创建一个myid文件,里面内容是server.N中的N,在机器H01上该文件的内容就是1。echo "1" >> myid
3. 将配置好的zk拷贝到其他节点
scp -r /usr/zookeeper/ hadoop@H02:/usr
scp -r /usr/zookeeper/ hadoop@H03:/usr
4.修改其他节点上的myid文件的内容
在H02应该将myid的内容改为2,在H03应该将myid的内容改为3。
4.2.3 测试zookeeper
1.分别启动每台机器上的zookeeper
进入bin目录下,执行./zkServer.sh start
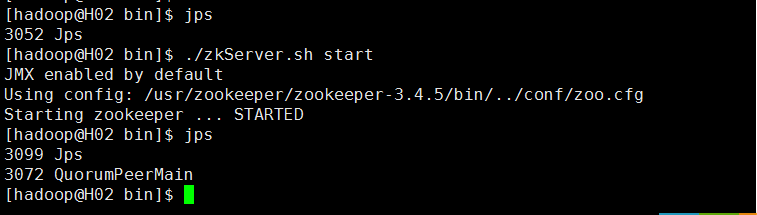
2.查看zookeeper的状态
在每台机器上分别执行./zkServer.sh status


由此可以看出H02机器上的zookeeper属于leader状态,其他两台机器上的zookeeper属于follower状态。
3.启动客户端
在H01机器上执行./zkCli.sh

创建一个新的hadoop123目录,里面内容写入123
create /hadoop123 123
分别启动H02和H03上的客户端,发现在H01上创建的hadoop123目录已经同步到H02和H03机器上了
测试成功。