Hive--HiveQL:查询
4 查询
4.1 select...from语句
4.1.1 基本操作
select是SQL的射影算子,from子句标识了从哪个表、视图或嵌套查询中选择记录。回顾之前创建的employees表:
hive (mydb)> create table employees (
> name string,
> salary float,
> subordinates array<string>,
> deductions map<string,float>,
> address struct<street:string, city:string, state:string, zip:int>)
> partitioned by (country string, state string)
> row format delimited
> fields terminated by '\t'
> collection items terminated by ','
> map keys terminated by ':';
装载数据:
hive (mydb)> load data local inpath '${env:HOME}/employees.txt' overwrite into
> table employees
> partition (country='US', state='IL');
执行select语句:
hive (mydb)> select name, salary from employees;
hive (mydb)> select name, subordinates from employees;
hive (mydb)> select name, deductions from employees;

hive (mydb)> select name, address from employees;
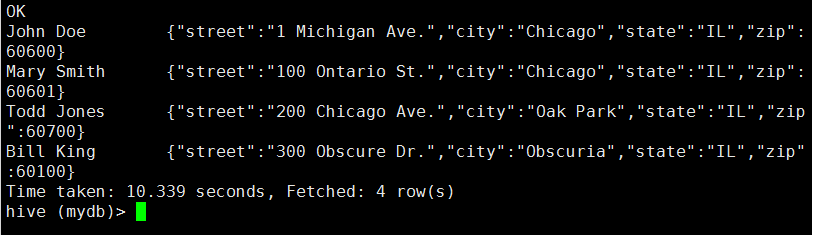
那么如何引用集合数据类型中的元素呢?
1 引用array中的元素
数组索引是基于0的,所以查询subordinates数组中的第一个元素用subordinates[0];
hive (mydb)> select name, subordinates[0] from employees;

注意:引用一个不存在的元素会返回NULL。
2 引用map中的元素
引用map中的元素时,可以使用类似于引用数组中元素的做法,但是使用的是键值而不是整数索引。
hive (mydb)> select name, deductions["State Taxes"] from employees;

3 引用struct中的元素
引用struct中的元素时,可以通过“点”符号。
hive (mydb)> select name, address.city from employees;

4.1.2 使用正则表达式来指定列
使用正则表达式可以指定我们想要的列,例如,在employees表中,指定所有以s开头的列:
hive (mydb)> select `s.*` from employees;

4.1.3 使用列值进行计算
可以使用算数表达式和函数调用来操作列值。可以通过select语句查询得到大写的雇员姓名,雇员对应薪水需要交纳的联邦税收比例以及扣除税收后再进行取整所得的税后薪水。
hive (mydb)> select upper(name), salary, deductions["Federal Taxes"],
> round(salary*(1-deductions["Federal Taxes"])) from employees;
1.算术运算符
Hive支持所有典型的算术运算符。

算术运算符可以接受所有的数值类型,如果数据类型不一样,那么两种类型中值范围较小的那个数据类型将转换为其他范围更广的数据类型。
2 函数
1)数学函数
数学函数可以处理单个列的数据。
2)聚合函数
聚合函数可以处理多个列的数据,然后返回一个结果值。以count和avg为例,函数count可以计算有多少行数据(或者某列有多少值),而函数avg可以计算指定列的平均值。
hive (mydb)> select count(*), avg(salary) from employees;

常用的聚合函数:
3)表生成函数
表生成函数可以将单列扩展成多列或者多行。以explode(ARRAY array)为例,返回0到多行结果,每行都对应输入的array数组的一个元素。
hive (mydb)> select explode(subordinates) from employees;

4.1.4 limit语句
limit语句会限制返回的行数。
hive (mydb)> select upper(name) from employees limit 2;

4.1.5 列别名
前面的查询语句可以认为是返回一个由新列组成的新的关系,有时候需要给这些新列起个名称,也就是说别名。
hive (mydb)> select upper(name), salary, deductions["Federal Taxes"] as fed_taxes,
> round(salary*(1-deductions["Federal Taxes"])) as salary_minus_fed_taxes
> from employees limit 2;
4.1.6 嵌套select语句
4.1.7 case...when...then句式
case...when...then语句和if条件语句类似,用于处理单个列的查询结果。
hive (mydb)> select name, salary,
> case
> when salary<50000.0 then 'low'
> when salary>=50000.0 and salary<70000.0 then 'middle'
> when salary>=70000.0 then 'high'
> else 'very high'
> end as bracket from employees;

4.2 where语句
select用于选取字段,where语句用于过滤条件。
修改之前的对的对于联邦税收的查询,保留减去联邦税后工资大于70000的查询结果。
hive (mydb)> select e.* from
> (select upper(name), salary, deductions["Federal Taxes"] as fed_taxes,
> round(salary*(1-deductions["Federal Taxes"])) as salary_minus_fed_taxes
> from employees) e
> where round(e.salary_minus_fed_taxes)>70000;
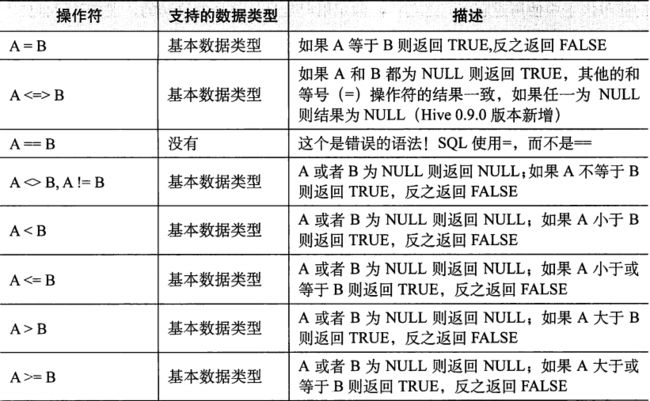
4.2.1 谓语操作符
谓语操作符可用于where、join...on和having语句中。

4.2.2 关于浮点数的比较
先看一个SQL语句
hive (mydb)> select name, salary, deductions['Federal Taxes']
> from employees where deductions['Federal Taxes']>0.15;
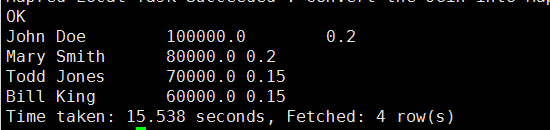
为什么deductions['Federal Taxes']=0.15的记录也被输出了呢?由于Hive中,数字0.15不能使用float或double进行精确的表示,在这个例子中,0.15的最近似精确值应略大于0.15。为了简化一点,我们可以认为0.15对于float类型是0.15000001,对于double类型是0.1500000000001。我们定义deductions这个map的值的类型是float类型的,这意味着Hive会将该值转成double类型后再比较,当表中deductions的float类型的值转成double类型时,其产生的结果是
0.15000001,比实际的0.1500000000001值大。
解决办法:将0.15转换成float类型。
hive (mydb)> select name, salary, deductions['Federal Taxes']
> from employees where deductions['Federal Taxes']>cast(0.15 as float);

4.3 group by语句
group by语句通常会和聚合函数一起使用,按照一个或多个列对结果进行分组,然后对每个组执行聚合操作。
例如:
select col1[,col2],count(1)
from table
where condition
group by col1[,col2]
[having];
注意:select后面的非聚合列必须出现在group by中
4.4 join语句
Hive支持SQL JOIN语句,但是只支持等值连接。
首先查看下z0、z1和z2各个表中的内容:

inner join
只有进行连接的两个表中都存在与连接标准相匹配的数据才会保留下来。
hive (mydb)> select * from z0 join z1 on z0.uid=z1.uid;
on子句指定了两表进行相连的条件
Hive不支持对连接关键字进行非等值的操作。例如:
hive (mydb)> select * from z0 join z1 on z0.uid<>z1.uid;
left outer join
左外连接通过关键字left outer进行标记
hive (mydb)> select * from z0 left outer join z1 on z0.uid=z1.uid;

在这种join操作中,join操作符左边表中的所有满足查询条件的列都会被返回,右边表中如果没有符合on子句代表的连接条件的记录时,那么从右边表指定选择的列的值都是NULL。
right outer join
右外连接会返回右边表中所有满足查询条件的列,左边表中匹配不上的字段值用NULL替代。
hive (mydb)> select * from z0 right outer join z1 on z0.uid=z1.uid;
full outer join
完全外链接会返回左右两边表中的所有满足查询条件的记录,如果任一表中的指定字段没有符合条件的值的话,就是用NULL替代。
hive (mydb)> select * from z0 full outer join z1 on z0.uid=z1.uid;
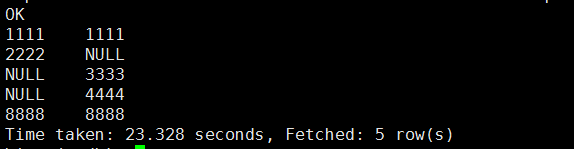
left semi join
左半开连接会返回左边表的记录,前提是其记录对于右边表满足on子句中的判定条件
hive (mydb)> select * from z0 left semi join z1 on z0.uid=z1.uid;

join的小结:
1)hive中join支持多表连接(2个或2个以上),例如:
SELECT a.val,b.val, c.val FROM a JOIN b ON (a.key =b.key1) JOIN c ON (c.key = b.key2)
如果join中多个表的join key 是同一个,则 join 会被转化为单个map/reduce 任务,例如:
hive (mydb)> SELECT a.val,b.val, c.val FROM a JOIN b
> ON (a.key =b.key1) JOIN c
> ON (c.key =b.key1);
这个SQL语句被转化为单个 map/reduce 任务,因为 join 中只使用了 b.key1 作为 join key。
hive (mydb)> SELECT a.val, b.val, c.val FROM a JOIN b
> ON (a.key =b.key1) JOIN c
> ON (c.key =b.key2);
而这个SQL会被转化为2 个 map/reduce 任务。因为 b.key1 用于第一次 join 条件,而 b.key2 用于第二次 join。
2)执行join语句是的mapreduce逻辑
reducer 会缓存 join 序列中除了最后一个表的所有表的记录,再通过最后一个表将结果序列化到文件系统。这一实现有助于在 reduce 端减少内存的使用量。实践中,应该把最大的那个表写在最后(否则会因为缓存浪费大量内存)。例如:
hive (mydb)> SELECT a.val, b.val, c.val FROM a
> JOIN b ON (a.key = b.key1)JOIN c ON (c.key = b.key1);
所有表都使用同一个 join key(使用 1 次map/reduce 任务计算)。Reduce 端会缓存 a 表和 b 表的记录,然后每次取得一个 c 表的记录就计算一次 join 结果,类似的还有:
hive (mydb)> SELECT a.val, b.val, c.val FROM a
> JOIN b ON (a.key = b.key1)JOIN c ON (c.key = b.key2);
这里用了 2 次 map/reduce 任务。第一次缓存 a 表,用 b 表序列化[王黎11] ;第二次缓存第一次 map/reduce 任务的结果,然后用 c 表序列化。
Hive中提供了一个“标记”机制来显示的告诉查询优化器哪张是大表,使用方式如下:
hive (mydb)> SELECT /*+STREAMTABLE(a)*/ a.val, b.val, c.val FROM a
> JOIN b ON (a.key = b.key1)JOIN c ON (c.key = b.key2);
4.5 排序
order by、sort by、distribute by和cluster by
order by:
Hive中的order by语句和其他的SQL方言中的定义是一样的,其会对所有的结果执行一个全局排序。也就是说会有一个所有的数据都通过一个reducer处理的过程,但是对于大数据集,这个过程可能需要消耗很多的时间。
如果属性hive.mapred.mode的值是strict(默认值是nonstrict)的话,执行order by语句时必须加有limit语句限制。
sort by:
针对order by,Hive中增加了一个可以选择的方式:sort by。其会在每个reducer端都会做排序,也就是说保证了局部有序(每个reducer出来的数据是有序的,但是不能保证全局所有的数据是有序的,除非只有一个reducer)。
无论是order by还是sort by,都可以指定任意期望进行排序的字段,并可以在这些字段后面加上asc关键字(默认的),表示按照升序排序,或者加上desc关键字,表示按照降序排序。
distribute by和sort by一起使用
distribute by控制map输出在reducer中是如何划分的。默认情况下,MapReduce计算框架会根据map输入的键计算相应的哈希值,然后按照得到的哈希值将键-值对均匀的分发到多个reducer中去,这就意味着当使用sort by时,不同reducer的输出内容会有明显的重叠,至少对于排列顺序是这样的,即使每个reducer的输出数据都是有序的。
假如我们希望具有相同name的数据放到同一个reducer中处理,可以使用distribute by来实现。
cluster by
cluster by的功能就是简单版的distribute by和sort by结合,前提是distribute by和sort by中所涉及的列完全相同,而且采用的是升序(ase)排序。
现在做个练习,创建一张表stores:
hive (mydb)> create table stores (
> name string,
> money float,
> mid string)
> row format delimited
> fields terminated by '\t';
name表示store的名字,money表示这个store的盈利,mid表示这个store所属的商户。
数据源:
[hadoop@H01 ~]$ cat stores.txt "商店1" 18.0 A "商店2" 25.0 B "商店3" 15.0 A "商店4" 20.0 C "商店5" 30.0 C "商店6" 23.0 D
加载数据:
hive (mydb)> load data local inpath '${env:HOME}/stores.txt' overwrite into
> table stores;
查看数据:
hive (mydb)> select * from stores; OK "商店1" 18.0 A "商店2" 25.0 B "商店3" 15.0 A "商店4" 20.0 C "商店5" 30.0 C "商店6" 23.0 D Time taken: 0.093 seconds, Fetched: 6 row(s)
现在想要求出每个商户的各个商店的盈利情况(商户名按照字典顺序,盈利按照降序)
使用order by排序:
hive (mydb)> select s.mid, s.money, s.name from stores s > order by s.mid asc, s.money desc;

使用sort by排序:
hive (mydb)> select s.mid, s.money, s.name from stores s
> sort by s.mid asc, s.money desc;
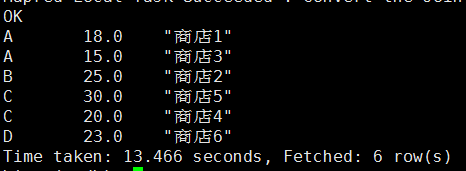
distribute by和sort by结合使用
hive (mydb)> select s.mid, s.money, s.name from stores s
> distribute by s.mid, s.money
> sort by s.mid asc, s.money desc;
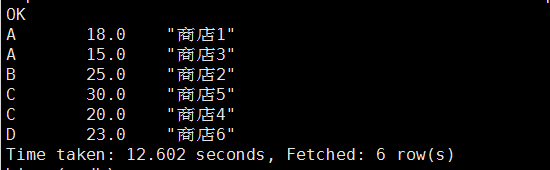
使用cluster by:
hive (mydb)> select s.mid, s.money, s.name from stores s
> cluster by s.mid, s.money;
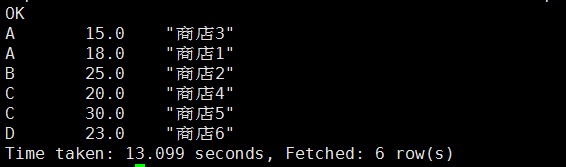
由于处理的数据比较小,所以使用order by和sort by得到的结果是一样的;比较由distribute by、sort by结合使用得到的结果和cluster by得到的结果可以发现cluster by确实是按照升序排序的。