开发高性能JAVA应用程序基础(集合篇)
集合类在开发中使用非常频繁,使用时合理的选择对提高性能小有帮助。而且大部分面试都会有与集合相关的问题,例如ArrayList和LinkedList的对比。
了解API的集成与操作架构,才能了解何时该采用哪个类,而不会只能抄写范例。本文也尝试用一些现实生活中的物品来描述各个集合类的特性,仅仅是帮助快速理解和记忆,不必太过较真。
首先看类结构图:
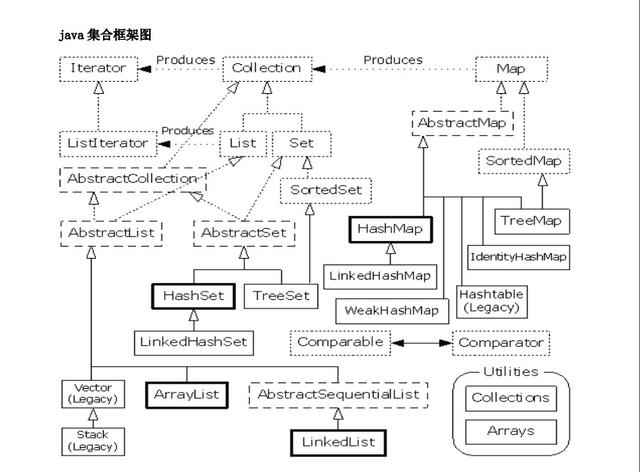
按用途分为可重复收集对象的List、不可重复的Set和键值对应的Map三个顶层接口,对应三个最常用的实现类是ArrayList、HashSet和HashMap,如果没有其他的限制它们应该是默认的选择。
注意Vector、Hashtable和Stack上都有Legacy字样,如果不是为了兼容旧代码,不应再使用这三个类。
一、ArrayList对比LinkedList
很多文章介绍时直接说ArrayList查询快插入慢,LinkedList插入删除快,但是这个是有前提的。
代码为证:
public static void main(String[] args) {
List<Integer> array1 = new ArrayList<>(), array2 = new ArrayList<>();
List<Integer> link1 = new LinkedList<>(), link2 = new LinkedList<>();
for(int i = 0; i < 100000; i++) {
array1.add(i); array2.add(i);
link1.add(i); link2.add(i);
}
System.out.println("从0开始ArrayList消耗:" + getTime(array1, 0));
System.out.println("从0开始LinkedList消耗:" + getTime(link1, 0));
System.out.println("从50000开始ArrayList消耗:" + getTime(array2, 50000));
System.out.println("从50000开始LinkedList消耗:" + getTime(link2, 50000));
}
public static long getTime(List<Integer> list, int index){
long start = System.nanoTime();
for(int i = 0; i< 100000; i++){
list.add(index, i);
}
return TimeUnit.MILLISECONDS.convert(System.nanoTime() - start, TimeUnit.NANOSECONDS);
}
从0开始ArrayList消耗:3701 从0开始LinkedList消耗:17 从50000开始ArrayList消耗:2370 从50000开始LinkedList消耗:13363
来分析:
ArrayList内部使用Object数组来保存收集的对象,数组在内存中是连续的线性空间。可以想象成一排紧紧排列的桌子,因为紧密连接距离较短,随机找到某个位置(索引)的桌子会比较快,但是如果想在中间某个位置插入一个新的桌子,那必须把排在后面的桌子一张一张向后移动,以空出一个位置。同样,如果删除一个桌子(怪异的说法),则需要把后面一张一张向前移动。如果是更换呢,很简单,搬走一张桌子,把新的放在原来的位置(快)。
LinkedList内部是双向链表结构,形象是一个用线串联的珠串,两个珠子之间的线可能非常长。如果想找到某一个位置的珠子,必须从头开始,沿着线一个接一个的向后找(查询慢)。如果想在两个珠子之间插入一个新的,那就很简单了,把中间的线拆开,新珠子两端的线分别接上。删除同样简单。

那么为什么测试结果中LinkedList第二次表现远远落后呢?原因是想插入首先必须先定位到位置,第二次测试选定从索引50000开始,LinkedList每次操作前都需要从0开始寻址到50000,查询消耗大量时间,所以实际执行很慢。
LinkedList可以当作Stack和Queue使用,这是ArrayList不具备的。
二、HashMap和TreeMap
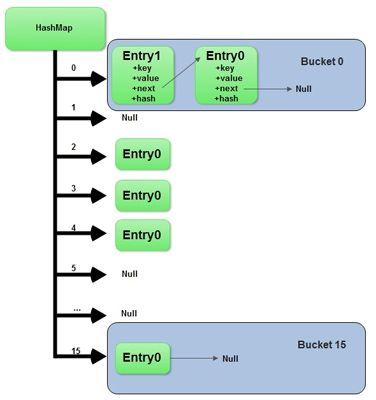
HashMap内部使用一个名为Entry的内部类数组保存key-value对,使用无参构造方法的情况下, 创建一个长度为16(capacity)的数组。其中的16个存储位置通常称为哈希桶。当存储一个Entry对象时,首先通过key的hashCode()获得一个整形的散列码,和数组长度做取模计算获得位置索引。
那么一个明显的问题是,如果两个key经过上面的计算后得到一个相同的位置索引怎么办?这种情况称为哈希冲突,HashMap解决的办法是把新Entry和原来位置的Entry建立起链表,如果再有第三个相同index的key加进来,那么继续加在链表的前部。一个帮助记忆的形象是皇帝冠冕前的多列垂珠。
调用get(key)方法查找时,先通过hashCode()和取模计算获得第几个桶,再对桶上的链表遍历列表并通过key.equals()逐个比较来确定对象。
这样看来如果链表过长,也会影响查询速度,这时候就是负载因子(load factor)出场的时候了。当HashMap中已存入的对象数量超过capacity * load factor时,会对数组扩容,变为原来的两倍。
一些优化提示:
1 如果开发时已经预知HashMap要存入的对象数量,可以直接指定初始容量,避免频繁扩容
2 int和String非常适合当作key
3 如果key使用自己的对象,那么一个好的hashCode()算法非常重要,应该使对象尽可能均匀的分布在各哈希桶,同时应该覆盖equals方法。Effective Java书中对怎样实现一个像样的hashCode()给出了指导。
TreeMap基于红黑树结构实现,理论上来说各方面性能都比HashMap差,使用它的唯一理由就是排序。在使用keySet对TreeMap遍历时,按照key的compareTo方法排序输出。
三、HashSet、TreeSet、LinkedHashSet、LinkedHashMap
HashSet是最常用的Set类,内部借助HashMap实现,特性可以直接参考HashMap。
TreeSet内部借助于TreeMap实现,同理使用它的理由也是获得排序后的对象列表。
LinkedHashSet 与HashSet类似,区别是使用iterator遍历时,LinkedHashSet按照对象插入的顺序输出。理论上插入时性能比HashSet差。
LinkedHashMap 与HashMap类似,区别是遍历时,按照对象插入的顺序输出。LinkedHashMap有一个三个参数的构造方法:
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)如果第三个参数设置为true,排序方式为按照访问顺序排序,可以借助该功能实现简单的采用"最近最少使用"失效算法(LRU)的缓存。
四、线程安全
上面提到的类中,除了Vector和Hashtable,全部都是线程不安全的。
示例1:
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
Thread t1 = new Thread() {
public void run() {
while(true) {
list.add(1);
}
}
};
Thread t2 = new Thread() {
public void run() {
while(true) {
list.add(2);
}
}
};
t1.start();
t2.start();
}执行结果:
Exception in thread "Thread-1" java.lang.ArrayIndexOutOfBoundsException: 549 at java.util.ArrayList.add(ArrayList.java:444) at Program$2.run(Program.java:28)
分析:ArrayList的add方法演示代码
public void add(Object o) {
if(next == list.length) {
list = Arrays.copyOf(list, list.length * 2);
}
list[next++] = o;
}ArrayList在添加对象时先判断数组是否已满,如果已满则扩容。多线程状态下,当next ==list.length-1时,两个线程轮流切换执行都不符合扩容条件进入下一步,此时第一个线程执行赋值并把next+1,第二个线程执行时next=list.length,出现ArrayIndexOutOfBoundsException。
示例2:
public class ArrayListDemo implements Runnable {
static ArrayList<Integer> list = new ArrayList<>();
static CountDownLatch latch = new CountDownLatch(10000);
public static void main(String[] args) throws InterruptedException {
ExecutorService exec = Executors.newCachedThreadPool();
for(int i = 0; i < 10000; i++) {
exec.execute(new ArrayListDemo());
}
latch.await();
System.out.println("list.size()=" + list.size());
}
@Override
public void run() {
list.add(1);
latch.countDown();
}
}执行结果:
list.size()=9977示例3:
public static void main(String[] args) throws InterruptedException {
HashMap<String, String> map = new HashMap<>();
map.put("a", "a");
Iterator<String> iter = map.keySet().iterator();
ExecutorService exec = Executors.newCachedThreadPool();
exec.execute(new Runnable() {
@Override
public void run() {
map.put("b", "b");
}
});
exec.shutdown();
while(iter.hasNext()) {
System.out.println(iter.next());
}
}执行结果:
Exception in thread "main" java.util.ConcurrentModificationException at java.util.HashMap$HashIterator.nextNode(HashMap.java:1429) at java.util.HashMap$KeyIterator.next(HashMap.java:1453) at ArrayListDemo.main(ArrayListDemo.java:34)
多线程下安全读写集合类有三种常见办法:
1 JDK5以后首选concurrent包下的集合类,包括ConcurrentHashMap、CopyOnWriteArrayList和CopyOnWriteArraySet
2 读写操作时加锁,使用synchronized关键字或者java.util.concurrent.locks下的类
3 使用Collections.synchronizedList、Collections.synchronizedMap等方法获得线程安全集合。