推测的删除锁(Speculative Lock Elision):实现高并发多线程执行
背景
SLE全称Speculative Lock Elision,我称之为推测的删除锁。这是一篇关于SLE的论文翻译,但是因为本人英语功底很差,所以翻译的不通顺而且会有很多错误的地方。之所以把它发出来,是因为个人感觉SLE设计的很巧妙,而且没有搜索很多到关于SLE的文章,这里的目的只是为了让大家了解SLE。有兴趣的同学最好看论文原文。
下面是正式的论文翻译(原作者Ravi Rajwar 和 James R. Goodman)。
摘要
因为临界区导致的线程串行化执行是多线程程序高性能的根本瓶颈。动态执行的时候,这样的串行化可能就不需要,因为临界区可以无锁安全地并发执行。当前的处理器还不能完全开发出这样的并行机制,因为还没有一种机制来动态的检测这样的内部线程依赖错误(多线程同时访问一个数据)。
我们打算做一个推测的删除锁(Speculative Lock Elision, SLE),一个新奇的处理器技术来动态地去除不必要的串行化锁检测并使多线程高并发执行。关键点在于一次正确的执行并不总是需要加锁的。预测出不必要的和可以删除的同步指令。这样就允许多线程并行执行由同一个锁保护的临界区。因为使用现存的缓冲机制造成的线程间数据冲突导致的错误推测(Misspeculation)时,使用回退来恢复。成功推测的删除执行的结果是正确的,不需要使用锁就可以提交的。
SLE可以完全在处理器中实现,不需要指令集支持,也不需要系统级的修改,对程序员是透明的,只要求硬件增加一点点额外的支持。SLE可以为程序员提供一个编写正确的高性能多线程程序的捷径。
1 介绍
不管是多个处理器间共享内存的形式还是硬件多线程架构,多线程软件中硬件的直接支持变得越来越常见。因为这种支持已经实现,所以希望应用程序开发者利用多线程编程开发。服务器程序习惯上用大量的线程级别的并发, 越来越多的证据显示, 如果程序员努力专注于利用这些新兴的架构, 桌面应用程序也可以使用这样的并行性。
在多线程程序中,同步机制—通常是锁—通常用来保证线程访问临界区代码中共享数据的独占性。一个线程加锁,执行临界区代码,然后解锁。其他所有的线程等待锁直到第一个线程完成了临界区的任务,串行的访问临界区,这样使整个临界区原子的执行。
从多个原因考虑,多个线程并发的访问同一个临界区中的共享数据不一定会冲突,这样的话访问也不会串行化。图1展示了两个这样的例子。图1a显示了一个多线程程序ocean。因为访问共享对象的存储指令(行3)出现了,所以需要加锁。然而大部分动态运行过程中的代码并不运行这个存储操作,因此就不需要锁。另外,当得到共享对象的锁时,多个线程可能会更新共享对象的不同字段,通常这些修改都是不冲突的。图1b展示了与更新哈希表相关的例子。这样的例子对SHORE中实现的线程安全的哈希表实现来说很常见,SHORE是一个数据库对象仓库。
图1动态不必要的同步掩盖了潜在并行性的两个例子
在这些例子中,当前乱序执行的处理器不会从这些常见的预测执行并行机制中获取任何提升,因为线程必须先等待一个空闲的锁然后用串行的方式获取锁。
当前没有一种机制能够检测出这种并行性。即使经过调整的多线程程序,它的性能也会受到频繁串行执行的影响,这种性能的退化甚至比当前普通的同步机制还要差。
在开发多线程程序的时候,程序员必须在性能和编码开发时间之间做权衡。尽管多线程程序可以提高吞吐量,但是这需要特定级别的专业技术才能正确处理线程之间的问题。这种技术的要求一般比大多数单线程程序要求高,因为线程间共享数据常常是细微复杂的。程序员在确保正确性时使用常用技术可能会避免大量的复杂性事物。这样可以提供一个更快更容易的方法来做一个正确的程序,但是限制了线程级别的并行性,因为不必要的同步导致的串行化约束了程序的执行:在动态执行时,可能在线程间不存在数据破坏。
理想情况下,程序员希望可以频繁的使用普通同步方法编写明显正确的多线程程序,并且有一个工具可以动态的删除这些普通同步用法。这样的话,即使程序员使用简单的方法编写正确的代码,同步也只会在必要时才执行;并且性能不会因为动态地不必要的同步而降低。
在这篇论文中,我们说明了怎么利用硬件技术从一个指令流中来动态地删除不必要串行化执行,并因此提高执行的并行性。在SLE中,硬件动态地识别同步操作,预测哪些是不必要的,然后删除。通过删除这些操作,程序看起来就像同步不存在一样。当然,这样做会破坏某些需要同步的情况下的正确性。这种情况可以使用先前存在的缓存一致性机制检测并且不需要执行同步操作。这时需要执行恢复操作并且需要明确的加锁。只有在硬件确定为了保证正确性需要串行化时才会执行同步操作。
安全动态的锁移除是通过开发一种锁的特性来实现的,就像临界区的那种普通的实现。如果在加锁和解锁之间的内存操作是原子的,那么加锁和解锁对应的两次写操作就可以忽略,因为第二次写操作(解锁)只是撤销第一次写操作(加锁)。3.3节详细讨论了这种概念。在5.3节中,会讨论关于原子性的访问冲突可以用缓存一致性协议检测处理,这种机制已经在现代大多数处理器中实现了。
- 允许高并发多线程执行:
多个线程可以并发运行由同一个锁保护的临界区。另外,不加锁也可以保证正确性。 - 简单正确的多线程代码开发:
程序员可以使用普通同步方法来写正确的多线程程序而不会有严重的性能影响。如果保证程序正确性不需要同步,那代码执行的时候,就可以像同步不存在一样(就是同步操作被删除了)。 - 可以很容易的实现:
SLE可以在处理器中完全实现,不需要指令集支持也不需要系统级的修改(例如,不需要一致性协议改变),对程序员也是透明的。当前的同步指令被动态识别。程序员不需要学习新的编程方法并且可以继续使用这些很好的理解(well understood)同步函数。这种技术可以合并到现代的处理器设计中,独立于系统和缓存一致性协议。据我们了解,从一个动态的执行过程中动态的删除不必要的普通的同步操作,不需要执行加锁解锁操作,也不需要请求锁变量的独占权力,这是第一次提出来的。在第3章和第4章,讨论了SLE的想法并在第5章提供了策略上的实现。很多需要的额外功能已经在现在的微体系结构或包含在了了解技术开发的微体系架构的优化中。
2背景
这一章,将会提供以锁为背景的多线程编程在性能和复杂性之间权衡,从SLE中获益的例子。
2.1 多线程编程中性能/复杂性之间的权衡
普通锁。任何的编程工作中,编程复杂性是考虑的重要问题,并要求保证线程间正确的同步与交互。没有合适的同步会导致错误的结果。为了保证正确性,程序员需要依赖于传统的锁,这些锁通常会导致性能损失。
锁粒度。一个深思熟虑的程序设计必须选择一个合适的锁的级别,在性能和确保程序正确性的简易性之间的权衡达到最优。早期的并行程序典型的设计包含很少的锁,并且程序员不需要考虑太多的正确性,因为所有内存都用锁来保护了。随着并行性的增加和锁频率的加大,性能开始下降,也开始使用细粒度的锁。细粒度的锁可以提升性能但是会增加编程的复杂性并且使管理程序变得困难。
遗留的线程不安全的链接库。一些场景中串行化的重要源头就是遗留的不可重入的二进制包。如果一个线程调用一个不准备处理多线程的链接库,就需要一个锁机制来避免冲突,这样就会串行化访问进而导致性能下降。
2.2 互斥的微处理器
互斥通常使用原子的读-改-写原语实现,比如SWAP,COMPARE&SWAP,LOAD-LOCKED/STORE-CONDITIONAL(LL/SC)和EXCHANGE。这些指令允许处理利器(有些情况下)原子的交换一个寄存器中的值和内存中的值。
这种简单的互斥就是TEST&SET锁。TEST&SET可以原子的执行内存中的交换指令。TEST&TEST&SET,是TEST&SET的扩展,在TEST&SET操作前执行一个锁的读操作来测试。图2展示了TEST&TEST&SET序列的实现示例。硬件和软件上很多锁结构已经提出了简单可移植的TEST&TEST&SET锁,这让他们变得很受欢迎。硬件架构手册中建议并且数据库厂商也被建议考虑使用这些简单的锁作为可移植的锁机制(当然有些情况也会使他们使用一些其它的软件原语)。POSIX线程标准建议库中实现同步比如pthread_mutex_lock(),这些调用实现TEST&SET或TEST&TEST&SET锁。

图2 使用Alpha ISA加锁解锁的典型代码(这是一个TEST&TEST&SET锁的构造,1-7是加锁,6是解锁
3 允许并发的临界区
这一章讨论SLE的概念。为了能够简单的说明,我们使用图2中的代码序列和LL/SC;这种想法可以很容易的应用到其它的同步原语中。先讨论锁执行失败依赖(lock-enforced false dependences)。在3.2节和3.3节中会展示怎么克服这些依赖并在3.4节展示一个例子。
3.1 锁如何利用虚假依赖
锁是一个控制变量来决定线程是否可以执行临界区—它会强制控制线程间的依赖关系但不会提供任何有用的结果。另外,锁形成了单线程中的数据依赖—锁的值确定了线程的控制流程。锁执行控制依赖已经证明是一个数据依赖,因为这是一个线程检查和操作内存区域。这种依赖与一个指令等待逻辑上处在前面指令的数据的依赖是类似的,它也可能它的依赖执行完成。
原子的意思是一个临界区中所有的改变都会立即执行。瞬时改变的表现是关键。通过获取一个锁,一个线程可以阻止其它线程获取临界区中任何内存的更新。但是传统的解决方法只能很一般的保护临界区更新的原子性,它只有一种方法保证原子性。
如果可以通过其它方法保证临界区中的所有内存操作都是原子的,锁就可以删除,临界区也可以并发的执行。为了保证原子性,临界区必须满足下面的条件:
- 在一个可预测执行的临界区中读取数据不会在可预测临界区结束前被其它线程修改。
- 一个可预测临界区写入数据没有在完成前被其它线程访问(读或写)。通过确保一个线程在临界区中部分更新时没有被其它线程检测到,一个处理器可以提供临界区中不需要锁的原子性内存操作的方法。整个临界区看起来就是原子执行的,程序的语义也没有改变。
硬件是否可以提供一种在临界区中所有内存操作都是原子的方法,是保证正确执行而不总是需要加锁的关键。如果发生了数据冲突,例如两个线程同时竞争同一个数据而不是读取,就不能保证原子性而且需要加锁。使用当前存在的缓存协议实现可以检测到线程之间的数据冲突,这个在第5章中证明了。不在任何不满足上述两个条件的架构上的未被撤回(not retired)执行,就可以保证正确性(Any execution not meeting the above two conditions is not retired architecturally, thus guaranteeing correctness)。
从算法上讲,这个序列就是:
- 当看到一个加锁的操作,处理器预测临界区中的内存操作将会原子的出现并删除加锁操作。
- 执行临界区预测和缓存区结果。
- 如果硬件不能提供原子性,触发错误预测,恢复并明确的要求加锁。
如果遇到了解锁,这样就没有破坏原子性(否则原先会触发一个错误预测)。删除解锁操作,提交预测的状态,退出预测临界区。
删除锁要求在FREE状态时退出锁,允许其它线程应用同样的算法也可以预测的进入临界区。即使这个锁没有修改,不管在加锁还是解锁的时间,临界区的语义都没有改变。在第3步,处理器可以在加锁之前选择性的尝试有限次数的执行这个算法。这个次数称为重新开始阀值(restart threshold)。在达到重新开始阀值后,就会明确的加锁,后面运行的代码就会保证安全。
上面的算法要求处理器能够识别加锁和解锁操作。按照2.2节描述,加锁是使用低层同步指令来实现的。但是这些指令不一定总是用来做加锁。另外,解锁是使用普通的存储操作(store)实现的。因此处理器不能精确地识别一个操作是加锁还是解锁,只能是检测一系列加载、存储和低层的同步原语并预测加锁操作。下一节会讨论为什么没有精确语义信息的预测的加锁解锁指令也可以删除。
3.3 通过静默(silent)存储对(store-pairs)删除加锁解锁
加锁和解锁包含存储操作。如果锁是FREE状态,加锁操作就将其标记为HELD状态。解锁将其标记为FREE状态。图3第三列显示了SLE如何引用内存。已经将指令按照程序顺序编号。第一列从程序员的视角展示,第二列展示了处理器的执行的操作,第三列展示了不同线程中_lock_位置上的值。

图3 Silent store-pair删除。如果i16恢复_lock_值的是在指令i6前面的值(比如i3返回的值),并且i8到i15是原子执行的,i6和i16就可以删除。尽管预测的线程删除了i6,它自己还会监控HELD值(因为程序的顺序要求在单个线程中),而其它的线程监控FREE值。
如果i3返回FREE,i6就将_lock_改为HELD。i16将锁标记为FREE来解锁。解锁后(i16),_lock_的值应该与加锁开始的值是一样的(例如在i6前) —i16恢复_lock_的值,是在指令i6前面的那个值。开发这样的同步操作属性来删除加解锁。如果临界区中的内存操作是原子的,那么就将i6和i16看作是一个silent pair。这个结构被i6修改再由i16还原。当成对执行时,这个存储就是silent;单独执行,就不是。_lock_的位置不一定会被其它线程修改,或者i6和i16不能成为一个silent pair。注意其它的线程可以从_lock_读取内存。
上面的这个检测意味着SLE算法不需要依赖程序的语义信息,不管这个操作是加锁还是解锁。通过简单的检测加载/存储序列和读取写入值就可以做到忽略锁。如果任何指令序列匹配图3中第2列和第3列的模式,没有其它线程修改lock位置,并且临界区中的内存操作是原子执行的,与i6和i16相关的存储操作就可以忽略。lock位置从来没有修改,其它线程也可以在lock值的基础上也不串行化执行。
因此,3.2节算法中增加了一个额外的预测。一旦预测到了一个加锁操作,处理器就会预测这个改变很快会被另一个存储操作还原,并且没有其它线程修改这个位置的问题。如果是这样的话,因为整个序列被检测到是原子性的,那么这两个存储指令就会被删除。使用一个过滤器来确定待选的加载/存储对。例如,在我们的实现中,只考虑ldl_l和stl_c(通常成对出现)指令。Stl_c存储指令就会被删除,并且会识别出匹配到了图3中存储模式。
完整的SLE算法是这样的:
- 如果待选的加载(ldl_l)指令操作一个地址紧接着就是存储指令(加锁的stl_c指令)操作同样的地址,预测另一个存储指令(解锁)也会很快出现,就恢复存储指令(加锁指令stl_c)前这个内存位置的值。
- 预测临界区的内存操作是原子性的并删除加锁操作。
- 执行临界区预测和缓存区结果。
- 如果硬件不能提供原子性,触发错误推测事件(misspeculation),恢复并明确的加锁。
- 如果遇到了第一步中的第二次存储操作(解锁),原子性就没有破坏(否则早就会触发一个错误预测事件)。删除解锁的存储操作,提交状态,退出预测执行的临界区。
注意,在上面的修正算法中,硬件不需要知道内存访问是否是关于锁变量的语义信息。硬件只是跟踪值的变化并监测从其它线程的请求。如果第5步存储操作与第1步要求的值不符,那么仅仅是执行操作。当存储操作完成时,如果还在保持原子性,就可以安全的退出临界区。
3.4 SLE算法示例
图4是一个早期示例图1的SLE的应用。右边是修改控制流程:第6和16个指令被删除了。所有线程都没有串行化执行。指令1和3将lock放到一个共享状态的缓存中。指令6被删除了,修改控制流程也按照预测执行。lock位置被其它线程修改的话会被监测。所有处理器的加载操作都会被记录。所有的存储执行会暂时缓存起来。如果到了指令16仍然没有破坏原子性,SLE就成功了。

图4 SLE算法示例。通常,第11个分支会执行而跳过恢复指令,图中右边灰色的部分不会执行。6和16被删除,i1和i8之间的指令没有分支。
如果线程不能标明两个存储之间的访问,或者硬件不能提供原子性,就会触发一个错误预测,并且重新从指令6开始执行。在重新开始时,如果达到了重新开始次数的阀值,就开始不推测的(普通模式)并且开始加锁执行。
4 为什么SLE是正确的?
现在开始讨论为什么SLE可以保证一个程序正确的执行,尽管缺乏关于软件、独立的嵌套层和内存顺序的精确信息。就像前面提到的,SLE包含了两个预测:
- 在执行一个存储操作时,预测另一个加载操作会很快执行并且还原这次的改变。这个预测决定不需要执行存储操作而是要求监测那个内存(执行存储指令的)。如果这个预测是正确的,这两个存储指令就被删除了。
- 预测在两个删除的存储指令之间的所有内存操作都会原子的执行。这个预测是通过利用5.3节描述的缓存一致性机制检查3.2节所述的条件来判定的。
上面的预测不依赖于程序的语义(锁预测是使用识别加载/存储指令作为预测1的候选指令,但这不是全部,软件可以选择性的提供这些线索)。另外,对其它线程来说不能有部分更新的情况。这样做就可以保证临界区的语义。因为结构的状态保持不变,所以可以删除存储指令。不管有没有SLE,这个结构在删除的第二条存储指令的最后状态是一样的。
如果另一个线程通过改写它来明确的加锁,就会触发一个错误预测事件,因为所有探测执行的线程会自动监控到这个写入操作。这个小细节保证了即使当一个线程正在推测执行而另一个线程在加锁时的正确性。
内嵌锁。尽管可以将省略算法(就是上面的SLE算法)应用于多个嵌套锁,也只是使用一个层级(可以是任意一层而不是一定是最外层),在这个层级中的任何锁操作被视为可探测的内存操作。
内存一致性。因为基于SLE的可推测的内存操作是原子的,所以不会有内存顺序问题。不管内存一致性模型,对于一个线程来说,在整体内存操作命令中插入一个原子性的内存操作集合总是正确的。
5 实现SLE
已经说明了SLE怎么用来动态的删除不必要的同步操作,现在开始说明如何利用容易理解的并且常用的技术来实现SLE。SLE与分支预测和其它的探测执行技术很相似。删除加锁可以当做分支预测,删除解锁操作类似于分支决策。然而,SLE不要求处理器支持乱序执行,而只是简单的能够推测撤销指令(speculatively retire instructions). 换句话说,不需要维护内部指令的依赖信息。
5.1 初始化推测(Initiating speculation)
有一个过滤器用来检测推测候选指令(例如ldl_l/stl_c指令对)并使用程序计数器来检索。另外,一个值得信赖的评判方法是分配到每个指令对中。如果处理器预测拿到了一个锁,就会假设另一个处理器必须加锁,因为它不能删除这个锁操作。这种情况下,处理器就不会发起推测操作。这是一个传统的解决方法,但是可以防止异常(pathological)情况下性能下降。更好的评估方法是未来研究的一个重要领域。
5.2 缓存推测状态
为了可以从SLE错误推测中恢复,必须缓存寄存器和内存状态,直到SLE成功执行。
推测寄存器状态。两个处理寄存器状态的简单技术:
- 重新规划缓冲区(ROB, Reorder Buffer):使用重新规划缓冲区可以利用已经用于分支错误预测的恢复机制的优势。然而,ROB的大小限制了临界区的大小(根据动态指令决定)。
- 寄存器检查点(Register checkpoint):这可能是依赖映射(可能在如何释放物理寄存器上有特定限制)或体系架构寄存器本身的状态。一旦遇到错误推测,就会恢复检查点。使用检查点解除临界区大小限制:因为一个正确规划的检查点就是为了一旦发生错误推测用来恢复的,所以指令可以安全的更新寄存器文件,推测的收回(speculatively retire)并从ROB中删除(意思是执行一部分,把前面的删除,再接着执行后面的)。有一个重点:只需要一个这样的检查点并且是在SLE序列开始时处理的。
推测的内存状态。尽管现代大部分处理器都支持推测加载执行,但是它们不会推测地撤销(retire)存储指令(例如:推测地写入内存系统)。为了支持SLE,将现存处理器的写缓冲区(在处理器和L1缓存之间)增加到推测内存更新缓存上去。一旦发生错误推测,整个写缓冲区的推测都是不正确的。
在SLE下,有一个额外的好处,推测的写入现在可以合并到写缓冲区了,并且独立于内存一致性模型。对于成功的推测是可能的,因为所有内存访问都保证是完全原子的。写缓冲区的大小只是限制临界区修改的特定缓存行的个数,不会限制临界区中执行的存储指令的动态数量。
5.3 错误推测条件和检测
错误推测的两个原因:1)原子性破坏和2)因资源限制破坏
原子性破坏。原子性破坏(3.2节)可以使用现存的缓存一致性机制检测。缓存一致性是一种将内存更新广播到其它缓存并且让其它缓存可以知道内存操作的机制。基于失效的一致性协议保证了当执行存储操作时本地缓存复制内存块是排它的。现代大部分处理器已经实现了一些形式的基于失效的一致性作为本地缓存层次结构的一部分。因此在不同的处理器之间检测内存操作冲突的基本机制已经存在了。现在需要一个记录临界区内存读取和写入地址的机制。
在一些处理器中,比如MPIS R10K和Intel奔腾4,缓存通过监控加载/存储(LSQ)来接收所有外部失效事件来实现积极内存一致性。如果SLE使用了ROB,推测读取的这块内存就不需要额外的机制来跟踪外部的内存写入了—已经跟踪了LSQ。
如果使用寄存器检查点的方法,单单是LSQ不能作为SLE的加载冲突检测机制,因为加载可能推测的撤回(speculatively retire)并且离开ROB。这种情况下,可以为每个缓存块用一个access位来标记。每个内存访问都在SLE标记响应块的访问位期间执行。外部请求到达时,这个标记和缓存标签并行的检查。所有的访问位设置过的失效块,或通过访问位设置独占状态块的外部请求,就会触发一个错误推测事件。这个位可以放在标签(每个缓存块都有一个标签tag)中,上面也没有一个位用来比较,因为为了保持一致性,标签的查询已经由探查缓存来执行。
这个方案是与缓存层个数无关的,因为所有缓存都会保持一致并且任何更新都会使用现存协议自动广播到所有一致性缓存。
在错误推测和提交时,缓存中的所有块的访问位都没有设置;这可以用像闪存失效的技术来实现。对于强制指令乱序的处理器,当解码一个候选的存储指令(对于加锁省略)时,所有后续处理器发起的加载指令会标记适当的访问位。加载指令实际上不一定是临界区的一部分,但是谨慎的将它标记下总是正确的。管道(pipe)中允许存在多个候选存储指令(预测加锁),并且在核心中只要有一个候选的存储指令,加载指令就会标记访问位。
资源限制导致的冲突。如果没有足够的缓冲区空间存储推测更新或者不能监控访问的数据来提供原子性保障,那么资源限制可能会强制发起一个错误推测。错误推测的4个条件:
- 有限的缓存大小。如果使用寄存器检查点,缓存可能不够跟踪所有的内存访问。
- 有限的写缓冲区大小。修改的特定缓存行的数量超过了写缓冲区大小。
- 有限的ROB大小。如果使用检查点这个方法,ROB的大小就不是问题了。
- 没有缓存的访问或事件(例如一些系统调用),处理器无法跟踪请求。
对于条件1,2和3来说并不总是需要重新开始。处理器可能简单的将锁标记为需要加锁。当这个操作完成时,如果仍然保持原子性,就可以提交这个推测,并且处理器可以不用重新开始继续执行。
5.4 提交推测的内存状态
已经讨论了恢复和提交架构的寄存器状态,缓冲推测的写缓存中的存储状态并使用现存的缓存一致性协议检测错误推测条件。提交内存状态要求确保推测的缓存的写入已经提交了并且对内存系统来说是立即可见的(为了提供原子性)。
缓存包含两个方面:1)状态,2)数据。缓存一致性协议决定了缓存块状态的转换。重要的是,只要数据按照推测的没有改变,这些状态就可以按照推测的产生。这就是现代处理器提出的可以猜测的加载和排它(exclusive)预取(在排它状态下将数据放入缓存的操作)。使用这两个方面执行原子的提交内存,不能做任何与缓存一致性协议相关的修改。
当一个推测的存储指令添加到写缓冲区时,会向内存系统发出一个独占请求。这个请求会初始化一致性协议中先前存在(pre-existing)的状态转换并在排它状态下将缓存块放到本地缓存。注意缓存块的数据是不可推测的—可以推测的数据都在写缓存中缓存起来了。当临界区到达结尾时,所有写缓冲区中可推测的条目在缓存中都会有一个相应的排它状态的块,否则早就会触发一个错误推测事件。从这点上看,写缓冲区就会标记为最新的架构状态。
写缓冲区要求一个额外的功能,就是可以从其它线程请求源数据。这不是在临界区中并且写缓冲区可以延迟刷新到缓存。立即提交是可能的,因为标记写缓冲区为最新状态的过程只是包含设置一个位而已—所有可推测的更新和缓存块已经获取了独占权限。
图5说明了两个设计点:(a)使用ROB存储推测的状态,(b)使用额外的寄存器检查点并访问缓存标签中的位。

图5 SLE的两个设计点。这个方框是处理器。修改和额外的数据路径用斜体和灰色线表示。
6 评估方法
一个多线程程序可以有不同的控制流程,这依赖于底层的一致性机制,并且性能的提升很大程度上依赖于底层协议的实现。为了解决这个问题,我们评估了多种配置。表1展示了三种多处理器系统的参数:a) 芯片的多处理器(CMP),b) 更常见的总线系统(SMP),c) 目录服务系统(DSM, directory system)。总线协议基于Sun Gigaplane,目录服务协议基于SGI Origin 2000。处理器将Total Store Ordering(TSO)作为内存一致性模型来实现。完成的存储按照程序的顺序写到写缓冲区中,使之在总体架构上可见。发生一致性事件时,所有正在执行的加载操作都会被探查到,如果需要的话会再次执行。使用一个单独的寄存器检查点用来做SLE寄存器恢复,还有序计数器索引的一个32条目的锁预测器。
| 处理器 L1缓存 | 1G Hz(1 ns时钟),128个重新规划缓冲区,64个加载/存储序列,16个执行读取队列,3周期分支错误预测重定向处罚,每周期8个乱序发起/提交,发起会尽可能早的加载,8K个综合性的预测器,8K个4路BTB(分支目标缓冲器,Branch Target Buffer)。64个返回地址栈。流水线功能单元,8个逻辑单元,4个浮点数单元,3个内存接口。写缓冲区:64个(每个64B大小)指令缓存:64KB,2路,访问时间1周期,未命中延迟16个周期。数据缓存:128KB。4路关联,回写,访问时间1周期,未命中延迟16个周期。一行64字节。L1和L2之间最少占用1个周期来请求/响应。 |
|---|---|
| CMP | L1之间的Sun Gigaplane-type MOESI协议,分离事务。地址总线:广播网络,20周期的监控延迟,120个未提交的事务。L2缓存,完美,访问时间12周期。数据网络:点对点,流水线,传输延迟:20周期 |
| SMP | L2之间的Sun Gigaplane-type MOESI协议,分离事务。地址总线:广播网络,监控延迟30周期,120个未提交的事务。L2缓存,标准化,4MB,4路,访问时间12周期,未命中延迟16个周期。数据网络:点对点,流水线,70周期传输延迟。内存访问:64字节70周期。 |
| DSM | L2之间的SGI Origin-2000-type MESI协议。L2缓存:标准化,4MB,4路,访问时间12周期,命中失败16周期延迟。目录:全映射,访问时间70周期(与内存访问重叠)。网络延迟:处理器到本地目录(70ns),目录和远端路由(50ns)。一些未统计的延迟:读丢失到本地内存:约130ns,读丢失到远端内存:约230ns,读丢失到远端脏缓存:约360ns。 |
表1 模拟的机器参数
6.1 模拟环境
我们使用SimpleMP(一个执行驱动模拟器)来运行多线程程序。这个模拟器是继承自Simplescalar工具集。为了精确地模拟乱序的处理器和多处理器配置中复杂的内存层级,我们重写了模拟器。为了精确地模拟联接和内存一致性事件,处理器在缓存和写缓冲区中操作(读和写)数据。这些想法都包含在了内存系统中。为了确保模拟是正确的,在详细的定时模拟器后会运行一个功能检查模拟器,只是为了检查正确性。这个功能模拟器有自己的内存和寄存器空间,并且可以验证TSO的实现。
6.2 标准检查程序
使用一个简单的微标准检查程序和六个程序(表2)来评估我们的方案。这个微标准检查程序包含N个线程,每个增加一个唯一的计数器(216)/N次,这N个计数器使用一个锁来保护。这是普通锁最差的表现,但是这清晰的证明了我们方案的可能性。这六个程序,从SPLASH系列和radiosity中使用mp3d, barnes和cholesky,从SPLASH2系列中使用ocean。
| 程序 | 模拟器类型 | 输入 | 临界区类型 |
|---|---|---|---|
| Barnes Cholesky Mp3D Radiosity Water-nsq Ocean-cont | N-Body Matrix factoring Rarefied field flow 3-D rendering Water molecules Hydrodynamics | 4K bodies tk14.O 24000 mols, 25 iter. -room, batch mode 512 mols, 3 iter. x130 | cell locks, nested task queues, col. locks cell locks task queues, nested global structure conditional updates |
表2 标准检查程序
选择这些程序的原因是他们会有多种变化的锁行为、内存访问方式和临界区表现。这些基准已经做了一些适当的补充以减少分享失败的概率。使用加锁版本的Mp3d是为了研究SLE在加强锁标准上的影响。这个版本的Mp3d做了很多大范围的频繁的非竞争锁同步,并且这些锁的访问不能使用一个大的重新规划的缓冲区隐藏起来。Cholesky和radiosity有一个访问频繁的工作队列。Ocean-cont有条件更新代码序列。Barnes有高级别的锁,而且锁竞争很严重,然而water-nsq的锁竞争很小。
这些测试程序都已经对共享做过了优化,因此大部分情况下都不会有太多通讯。我们对决定鲁棒性和方案的潜能有兴趣,即使是已经调整好的标准检查程序。
7 结果
7.1 微标准检查程序结果
图6在y轴上画出了标准检查程序的执行时间(对CMP配置来说),x轴上是多种处理器数量。跟预期一样,普通锁因为竞争激烈导致性能快速下降。即使计时器更新没有冲突,乱序处理器也不能做到这一点,因为加锁序列标记了并行性但是加锁限制了性能。然而使用SLE的话硬件就会自动检测锁不需要加并且将其删除。达到了完美的伸缩性,因为SLE没有要求加锁(通过写入数据)来验证推测。
图6 CMP标准检查程序的结果
7.2 标准检查程序结果
SLE有一个参数是可变的,就是重新开始阀值(restart threshold)。这决定了一个处理器为了执行临界区需要明确加锁前会允许有多少次错误推测。我们使用多种阀值来做这个实验,并且描述了阀值为1的结果—处理器在SLE模式下原子性破坏后重新开始一次,并尝试再次删除锁。注意如果某个处理器拿到了一个锁,其他处理器不会再尝试SLE,而是会循环(spin)判断(或等待)这个锁(在尝试SLE前等待解锁),这由程序原来的控制流程序列决定。这样做可以保证拿到锁的处理器不会被其它处理器监控临界区数据访问受到干扰。
删除锁。图7显示了重新开始阀值为1的动态删除的加锁/解锁对的百分比。很大一部分动态加锁都删除了。这个减少并不总是会带来更好的性能,因为这些操作不一定在程序的临界区上,但是这证明了这个技术的效果。阀值为0(第一次错误推测重新开始)会导致删除加锁的概率降低了10-30%。在barnes中,对保护的数据竞争很激烈,重复的重新开始会导致冲突。因此对barnes来说,锁删除的个数很少。

图7 动态加锁解锁删除的比率
性能。图8显示了8个处理器和16个处理器规整后执行的时间。Y轴是规整后运行时间(SLE并行运行周期/没有SLE的并行运行时间)。1下面的数字是提升的速度。对每个条状图来说,上面的那部分对应着访问锁变量的消耗(LOCK-PORTION),下面那部分对应着休眠(rest)时间(NON-LOCK-PORTION)。条状对顶端那部分是对SLE情况来说规整后的执行时间。
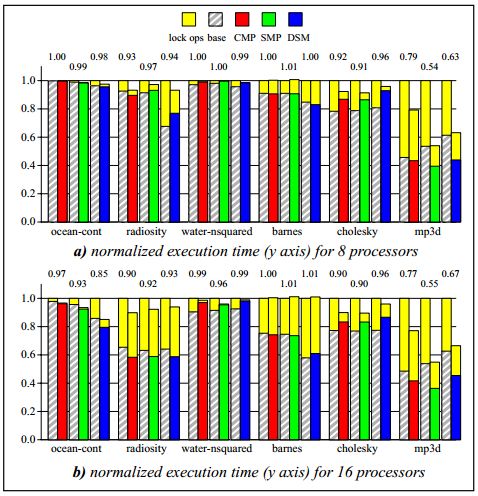
图8 标准化的执行时间(8线程/16线程,CMP/SMP/DSM)
对某些配置来说,优化场景下的NON-LOCK-PORTION比相应的基本场景NONLOCK-PORTION要大。这是因为有时删除锁会在临界区上放置一些内存操作。原先被加锁操作覆盖的临界区中数据推测的加载现在被重新暴露出来,而且还会拖慢处理器。
从观测来看,获取性能提升有三个主要推论:1) 并行执行临界区,2) 减少监测内存的等待时间,3) 减少内存操作。
并行执行临界区。在oceancont、radiosity和cholesky中,尽管会竞争锁,但是临界区有时不加锁也可以正确的运行,并且线程的运行没有因为锁而串行化。这个效率会随着更大的内存等待时间而增长,因为加锁延迟导致序列化的延迟时间增大。
减少监测内存等待时间。通常,加锁会导致缓存未命中,而且会向内存系统发起一个写入请求,这个延迟不能完全覆盖掉临界区中的未命中的延迟时间。SLE允许锁可以以共享的状态保留在本地缓存(每个CPU都有自己的缓存,称为本地缓存,local cache)中,这样处理器就不用监控加锁失败了。几乎所有的标准测试程序都会从中获益。Waternsq不会获益太多,因为在删除锁后,覆盖的那部分(是因为加锁导致的延迟访问时间对应的时间覆盖)临界区丢失又暴露出来了。
减少内存操作。如果一个锁锁住了并且以独占的状态保留在某个处理器缓存中,其它的处理器加锁时会向总线/网络发起请求消息(一个读取锁信息另一个设置)。因此对于频繁同步操作的标准检查程序来说,由于内存操作会减少,因此删除锁请求会有所帮助。由于不需要加锁,这个锁就以局部共享状态放在多个处理器,这样就消除了未命中增加的操作。获益最多的标准检查程序是mp3d,因为它省略了频繁的同步操作。一些锁的访问还是存在的,因为一些锁经过缓存未命中延迟时不能与之重叠。SMP和DSM版本在这方面比CMP有更多提升,因为它们的大缓存可以保存工作集,这样读取锁信息时就会有更少的读取未命中(还有内存操作)。对CMP来说,缺少大缓存会造成很大伤害,这样会有更多的未加锁状态(clean state)被抛弃,因为L1缓存有太多的冲突与未命中(capacity misses)。
错误推测的影响。按照我们的经验,因为容量和缓存冲突(因为综合性的限制)导致的错误推测占所有场景的概率不到0.5%。
依赖于重新开始阀值(restart threshold)。重新开始阀值为0的用例比阀值为1的用例速度小了25%。对某些标准检查程序来说,增加阀值会有更高的效率。然而对于有16个处理器的barnes来说,阀值为5的用例性能下降达到了10%。这是因为错误推测(misspeculating)的处理器会引入缓存一致性协议的冲突,进而增加临界区数据的监测延迟。选择一个低阀值(0或1)可以使降低最小化,因为这是在冲突的错误推测时发生的。对于这些标准检查程序,阀值为设置为1,性能很少会降低(减少1%)。即使可以删除更多的锁操作,增加阀值有时候可能会导致性能稍微下降,这是临界区中数据访问冲突导致的。动态选择重新开始阀值的预测是未来工作的一个领域。
8 相关研究
Lamport引进了无锁同步,并且给出了一个允许多线程不需要锁而操作同一个数据结构的算法。操作无锁(lock-free)的数据结构支持并行更新并且不要求彼此排斥。无锁数据结构已经被广泛的研究。实验性的研究表明实现无锁数据结构的软件没有对应的基于锁的表现好,主要是因为过多的引入数据复制在必要时会导致需要回滚。
事务性内存操作和Oklahoma更新协议是硬件支持实现无锁数据结构最初的提议。两种都为程序员提供了特殊的内存指令来访问这些数据结构。尽管概念上很强大,但是这个提议要求指令集的支持和程序员的参与。程序员必须学习新指令正确用法而且这个提议要求扩展一致性协议。另外,当前已经存在的软件并不能从中获益。这个提议依赖于软件支持来保证取得进展。这两个提议都是直接从LOAD-LINKED和STORE-CONDITIONAL指令扩展开来的,最开始是Jensen et a.提议的。
与上面的提议对比,我们的提议不要求修改指令集,扩展一致性协议或者程序员的支持。结果是,大部分情况下执行完临界区没有冲突时,我们在可以将不做修改的程序以无锁的方式运行。我们不需要为了发展而提供特殊的支持,因为当产生冲突时,我们只是简单地回退到原始的代码序列,再用普通的加锁解锁方式。
数据库在并发控制上已经做了大量的研究,Thomasian提供了一个很好的总结和更进一步的参考。Kung和Robinson提出了乐观并行控制(OCC,Optimistic Concurrency Control),在数据库管理系统中作为可选的锁。OCC在对象访问的地方引入了一个读取阶段(可能对这些对象的私有拷贝会做更新),接着是一个串行化的验证阶段来检查数据冲突(与其它事务的读/写冲突)。如果验证成功,接下来是写阶段。不管那个大量的研究,OCC并不是数据库系统中一般的并发控制机制。Mohan提出了一个很出色的关于使用OCC方法的探讨,但是它的缺点使它吸引不到高性能数据库系统。数据库系统的特殊需求和保障使OCC很难用于高性能。为了提供这些保障,软件中必须存放大量的状态信息,这就需要大量的开销。另外,使用OCC时验证阶段是串行化的。
我们的提议跟数据库OCC提议差别很大。我们不提供一个可选的基于锁的同步:我们检测动态实例,当这些同步操作不需要时就会删除它。强加给临界区的要求远没有数据库系统那么严格。因为我们不需要明确的加锁来确定成功,因此也没有一个串行化的验证阶段。
处理器中优先要支持推测的引退(retirement)和缓存推测的数据。我们的工作可以利用这些技术并与之并存。然而,先前没有一个技术动态的从动态指令流中删除普通同步操作。之前已经提出过预测加锁和解锁,我们使用了类似的技术。
我们的slient pair删除方案是Lepak和Lipasti提出的静默存储(slient store)提议的扩展。然而他们只是将单独的静默存储操作处理掉(squash),而我们是删除一对存储操作,因为单独的存储操作不是静默的(slient)而成对的运行就是静默的(slient)。
9 结束语
我们曾经提议过一个处理器技术来删除动态指令流中不必要的串行化。关键点是锁不一定要加而只是需要被监控。通过我们的技术,锁操作的控制依赖转换成了多个并行临界区间真正的数据依赖。结果是,可能被标记为动态的不必要的并行性和由程序员静态分析的普通锁现在由硬件动态分析。
这个技术不要求一致性协议的任何改变。另外,不需要程序员或者编译器的支持,也不需要指令集的改变。内存操作原子性的关键点使这个技术可以包含到任何的处理器,而不需要关注内存一致性,因为保证正确性不依赖于内存顺序。
我们将我们的提议看做是多线程程序高性能上前进的一步。随着多重处理变得更加普遍,就需要为程序员开发功能和性能上支持多重处理(multiprocessing)的特性。SLE可以让程序员很容易的编写正确的多线程代码,频繁使用普通的同步机制;我们的技术自动动态的删除不必要的同步。同步只是在为了正确性时才会执行;这样的同步出现时也不会降低性能。因为SLE是一个纯粹的处理器技术,因此可以加入到任何系统而不依赖于一致性协议和系统设计。
鸣谢
We would like to thank Mark Hill, Mikko Lipasti, and David Wood for valuable discussions regarding the ideas in the paper. We thank Brian Fields, Adam Butts, Trey Cain, Timothy Heil, Mark Hill, Herbert Hum, Milo Martin, Paramjit Oberoi, Manoj Plakal, Eric Rotenberg, Dan Sorin, Vijayaraghavan Soundararajan, David Wood, and Craig Zilles for comments on drafts of this paper. Jeffrey Naughton and C. Mohan provided us with information regarding OCC in database systems.