Android逆向之旅---解析编译之后的classes.dex文件格式
一、前言
新的一年又开始了,大家是否还记得去年年末的时候,我们还有一件事没有做,那就是解析Android中编译之后的classes.dex文件格式,我们在去年的时候已经介绍了:
如何解析编译之后的xml文件格式:
http://blog.csdn.net/jiangwei0910410003/article/details/50568487
如何解析编译之后的resource.arsc文件格式:
http://blog.csdn.net/jiangwei0910410003/article/details/50628894
那么我们还剩下一个文件格式就是classes.dex了,那么今天我们就来看看最后一个文件格式解析,关于Android中的dex文件的相关知识这里就不做太多的解释了,网上有很多资料可以参考,而且,我们在之前介绍的一篇加固apk的那篇文章中也介绍了一点dex的格式知识点:http://blog.csdn.net/jiangwei0910410003/article/details/48415225,我们按照之前的解析思路来,首先还是来一张神图:
有了这张神图,那么接下来我们就可以来介绍dex的文件结构了,首先还是来看一张大体的结构图:
二、准备工作
我们在讲解数据结构之前,我们需要先创建一个简单的例子来帮助我们来解析,我们需要得到一个简单的dex文件,这里我们不借助任何的IDE工具,就可以构造一个dex文件出来。借助的工具很简单:javac,dx命令即可。
创建 java 源文件 ,内容如下
代码:
public class Hello
{
public static void main(String[] argc)
{
System.out.println("Hello, Android!\n");
}
}
在当前工作路径下 , 编译方法如下 :
(1) 编译成 java class 文件
执行命令 : javac Hello.java
编译完成后 ,目录下生成 Hello.class 文件 。可以使用命令 java Hello 来测试下 ,会输出代码中的 “Hello, Android!” 的字符串 。
(2) 编译成 dex 文件
编译工具在 Android SDK 的路径如下 ,其中 19.0.1 是Android SDK build_tools 的版本 ,请按照在本地安装的 build_tools 版本来 。建议该路径加载到 PATH 路径下 ,否则引用 dx 工具时需要使用绝对路径 :./build-tools/19.0.1/dx
执行命令 :dx --dex --output=Hello.dex Hello.class
编译正常会生成 Hello.dex 文件 。
3. 使用 ADB 运行测试
测试命令和输出结果如下 :
$ adb root
$ adb push Hello.dex /sdcard/
$ adb shell
root@maguro:/ # dalvikvm -cp /sdcard/Hello.dex Hello
Hello, Android!
4. 重要说明
(1) 测试环境使用真机和 Android 虚拟机都可以的 。核心的命令是
dalvikvm -cp /sdcard/Hello.dex Hello
-cp 是 class path 的缩写 ,后面的 Hello 是要运行的 Class 的名称 。网上有描述说输入 dalvikvm --help
可以看到 dalvikvm 的帮助文档 ,但是在 Android4.4 的官方模拟器和自己的手机上测试都提示找不到
Class 路径 ,在Android 老的版本 ( 4.3 ) 上测试还是有输出的 。
(2) 因为命令在执行时 , dalvikvm 会在 /data/dalvik-cache/ 目录下创建 .dex 文件 ,因此要求 ADB 的
执行 Shell 对目录 /data/dalvik-cache/ 有读、写和执行的权限 ,否则无法达到预期效果 。
三、讲解数据结构
下面我们按照这张大体的思路图来一一讲解各个数据结构
第一、头部信息Header结构
dex文件里的header。除了描述.dex文件的文件信息外,还有文件里其它各个区域的索引。header对应成结构体类型,逻辑上的描述我用结构体header_item来理解它。先给出结构体里面用到的数据类型ubyte和uint的解释,然后再是结构体的描述,后面对各种结构描述的时候也是用的这种方法。
代码定义:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
|
package
com.wjdiankong.parsedex.struct;
import
com.wjdiankong.parsedex.Utils;
public
class
HeaderType {
/**
* struct header_item
{
ubyte[8] magic;
unit checksum;
ubyte[20] siganature;
uint file_size;
uint header_size;
unit endian_tag;
uint link_size;
uint link_off;
uint map_off;
uint string_ids_size;
uint string_ids_off;
uint type_ids_size;
uint type_ids_off;
uint proto_ids_size;
uint proto_ids_off;
uint method_ids_size;
uint method_ids_off;
uint class_defs_size;
uint class_defs_off;
uint data_size;
uint data_off;
}
*/
public
byte
[] magic =
new
byte
[
8
];
public
int
checksum;
public
byte
[] siganature =
new
byte
[
20
];
public
int
file_size;
public
int
header_size;
public
int
endian_tag;
public
int
link_size;
public
int
link_off;
public
int
map_off;
public
int
string_ids_size;
public
int
string_ids_off;
public
int
type_ids_size;
public
int
type_ids_off;
public
int
proto_ids_size;
public
int
proto_ids_off;
public
int
field_ids_size;
public
int
field_ids_off;
public
int
method_ids_size;
public
int
method_ids_off;
public
int
class_defs_size;
public
int
class_defs_off;
public
int
data_size;
public
int
data_off;
@Override
public
String toString(){
return
"magic:"
+Utils.bytesToHexString(magic)+
"\n"
+
"checksum:"
+checksum +
"\n"
+
"siganature:"
+Utils.bytesToHexString(siganature) +
"\n"
+
"file_size:"
+file_size +
"\n"
+
"header_size:"
+header_size +
"\n"
+
"endian_tag:"
+endian_tag +
"\n"
+
"link_size:"
+link_size +
"\n"
+
"link_off:"
+Utils.bytesToHexString(Utils.int2Byte(link_off)) +
"\n"
+
"map_off:"
+Utils.bytesToHexString(Utils.int2Byte(map_off)) +
"\n"
+
"string_ids_size:"
+string_ids_size +
"\n"
+
"string_ids_off:"
+Utils.bytesToHexString(Utils.int2Byte(string_ids_off)) +
"\n"
+
"type_ids_size:"
+type_ids_size +
"\n"
+
"type_ids_off:"
+Utils.bytesToHexString(Utils.int2Byte(type_ids_off)) +
"\n"
+
"proto_ids_size:"
+proto_ids_size +
"\n"
+
"proto_ids_off:"
+Utils.bytesToHexString(Utils.int2Byte(proto_ids_off)) +
"\n"
+
"field_ids_size:"
+field_ids_size +
"\n"
+
"field_ids_off:"
+Utils.bytesToHexString(Utils.int2Byte(field_ids_off)) +
"\n"
+
"method_ids_size:"
+method_ids_size +
"\n"
+
"method_ids_off:"
+Utils.bytesToHexString(Utils.int2Byte(method_ids_off)) +
"\n"
+
"class_defs_size:"
+class_defs_size +
"\n"
+
"class_defs_off:"
+Utils.bytesToHexString(Utils.int2Byte(class_defs_off)) +
"\n"
+
"data_size:"
+data_size +
"\n"
+
"data_off:"
+Utils.bytesToHexString(Utils.int2Byte(data_off));
}
}
|
查看Hex如下:

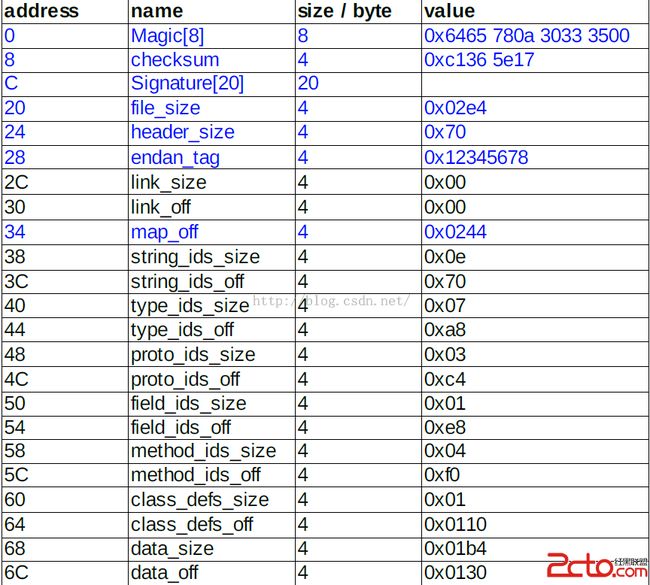
里面一对一对以_size和_off为后缀的描述:data_size是以Byte为单位描述data区的大小,其余的
_size都是描述该区里元素的个数;_off描述相对与文件起始位置的偏移量。其余的6个是描述.dex文件信
息的,各项说明如下:
(1) magic value
这 8 个 字节一般是常量 ,为了使 .dex 文件能够被识别出来 ,它必须出现在 .dex 文件的最开头的
位置 。数组的值可以转换为一个字符串如下 :
{ 0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00 }= "dex\n035\0"
中间是一个 ‘\n' 符号 ,后面 035 是 Dex 文件格式的版本 。
(2) checksum 和 signature
文件校验码 ,使用alder32 算法校验文件除去 maigc ,checksum 外余下的所有文件区域 ,用于检
查文件错误 。
signature , 使用 SHA-1 算法 hash 除去 magic ,checksum 和 signature 外余下的所有文件区域 ,
用于唯一识别本文件 。
(3) file_size
Dex 文件的大小 。
(4) header_size
header 区域的大小 ,单位 Byte ,一般固定为 0x70 常量 。
(5) endian_tag
大小端标签 ,标准 .dex 文件格式为 小端 ,此项一般固定为 0x1234 5678 常量 。
(6) link_size和link_off
这个两个字段是表示链接数据的大小和偏移值
(7) map_off
map item 的偏移地址 ,该 item 属于 data 区里的内容 ,值要大于等于 data_off 的大小 。结构如
map_list 描述 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
package
com.wjdiankong.parsedex.struct;
import
java.util.ArrayList;
import
java.util.List;
public
class
MapList {
/**
* struct maplist
{
uint size;
map_item list [size];
}
*/
public
int
size;
public
List<mapitem> map_item =
new
ArrayList<mapitem>();
}
</mapitem></mapitem>
|
引用位置 :header 区 。
map_list 里先用一个 uint 描述后面有 size 个 map_item , 后续就是对应的 size 个 map_item 描述 。
map_item 结构有 4 个元素 : type 表示该 map_item 的类型 ,本节能用到的描述如下 ,详细Dalvik
Executable Format 里 Type Code 的定义 ;size 表示再细分此 item , 该类型的个数 ;offset 是第一个元
素的针对文件初始位置的偏移量 ; unuse 是用对齐字节的 ,无实际用处 。结构定义如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
package
com.wjdiankong.parsedex.struct;
public
class
MapItem {
/**
* struct map_item
{
ushort type;
ushort unuse;
uint size;
uint offset;
}
*/
public
short
type;
public
short
unuse;
public
int
size;
public
int
offset;
public
static
int
getSize(){
return
2
+
2
+
4
+
4
;
}
@Override
public
String toString(){
return
"type:"
+type+
",unuse:"
+unuse+
",size:"
+size+
",offset:"
+offset;
}
}
|
每个 map_item 描述占用 12 Byte , 整个 map_list 占用 12 * size + 4 个字节 。所以整个 map_list 占用空
间为 12 * 13 + 4 = 160 = 0x00a0 , 占用空间为 0x 0244 ~ 0x 02E3 。从文件内容上看 ,也是从 0x 0244
到文件结束的位置 。

地址 0x0244 的一个 uinit 的值为 0x0000 000d ,map_list - > size = 0x0d = 13 ,说明后续有 13 个
map_item 。根据 map_item 的结构描述在0x0248 ~ 0x02e3 里的值 ,整理出这段二进制所表示的 13 个
map_item 内容 ,汇成表格如下 :
map_list - > map_item 里的内容 ,有部分 item 跟 header 里面相应 item 的 offset 地址描述相同 。但
map_list 描述的更为全面些 ,又包括了 HEADER_ITEM , TYPE_LIST , STRING_DATA_ITEM 等 ,
最后还有它自己 TYPE_MAP_LIST 。
至此 , header 部分描述完毕 ,它包括描述 .dex 文件的信息 ,其余各索引区和 data 区的偏移信息 , 一个
map_list 结构 。map_list 里除了对索引区和数据区的偏移地址又一次描述 ,也有其它诸如 HEAD_ITEM ,
DEBUG_INFO_ITEM 等信息 。
(8) string_ids_size和string_ids_off
这两个字段表示dex中用到的所有的字符串内容的大小和偏移值,我们需要解析完这部分,然后用一个字符串池存起来,后面有其他的数据结构会用索引值来访问字符串,这个池子也是非常重要的。后面会详细介绍string_ids的数据结构
(9) type_ids_size和type_ids_off
这两个字段表示dex中的类型数据结构的大小和偏移值,比如类类型,基本类型等信息,后面会详细介绍type_ids的数据结构
(10) proto_ids_size和type_ids_off
这两个字段表示dex中的元数据信息数据结构的大小和偏移值,描述方法的元数据信息,比如方法的返回类型,参数类型等信息,后面会详细介绍proto_ids的数据结构
(11) field_ids_size和field_ids_off
这两个字段表示dex中的字段信息数据结构的大小和偏移值,后面会详细介绍field_ids的数据结构
(12) method_ids_size和method_ids_off
这两个字段表示dex中的方法信息数据结构的大小和偏移值,后面会详细介绍method_ids的数据结构
(13) class_defs_size和class_defs_off
这两个字段表示dex中的类信息数据结构的大小和偏移值,这个数据结构是整个dex中最复杂的数据结构,他内部层次很深,包含了很多其他的数据结构,所以解析起来也很麻烦,所以后面会着重讲解这个数据结构
(14) data_size和data_off
这两个字段表示dex中数据区域的结构信息的大小和偏移值,这个结构中存放的是数据区域,比如我们定义的常量值等信息。
到这里我们就看完了dex的头部信息,头部包含的信息还是很多的,主要就两个个部分:
1) 魔数+签名+文件大小等信息
2) 后面的各个数据结构的大小和偏移值,都是成对出现的
下面我们就来开始介绍各个数据结构的信息
第二、string_ids数据结构
string_ids 区索引了 .dex 文件所有的字符串 。 本区里的元素格式为 string_ids_item , 可以使用结
构体如下描述 。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
package
com.wjdiankong.parsedex.struct;
import
com.wjdiankong.parsedex.Utils;
public
class
StringIdsItem {
/**
* struct string_ids_item
{
uint string_data_off;
}
*/
public
int
string_data_off;
public
static
int
getSize(){
return
4
;
}
@Override
public
String toString(){
return
Utils.bytesToHexString(Utils.int2Byte(string_data_off));
}
}
|
string_data_off 只是一个偏移地址 ,它指向的数据结构为 string_data_item
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
package
com.wjdiankong.parsedex.struct;
import
java.util.ArrayList;
import
java.util.List;
public
class
StringDataItem {
/**
* struct string_data_item
{
uleb128 utf16_size;
ubyte data;
}
*/
/**
* 上述描述里提到了 LEB128 ( little endian base 128 ) 格式 ,是基于 1 个 Byte 的一种不定长度的
编码方式 。若第一个 Byte 的最高位为 1 ,则表示还需要下一个 Byte 来描述 ,直至最后一个 Byte 的最高
位为 0 。每个 Byte 的其余 Bit 用来表示数据
*/
public
List<
byte
> utf16_size =
new
ArrayList<
byte
>();
public
byte
data;
}
</
byte
></
byte
>
|
延展
上述描述里提到了 LEB128 ( little endian base 128 ) 格式 ,是基于 1 个 Byte 的一种不定长度的编码方式 。若第一个 Byte 的最高位为 1 ,则表示还需要下一个 Byte 来描述 ,直至最后一个 Byte 的最高位为 0 。每个 Byte 的其余 Bit 用来表示数据 。这里既然介绍了uleb128这种数据类型,就在这里解释一下,因为后面会经常用到这个数据类型,这个数据类型的出现其实就是为了解决一个问题,那就是减少内存的浪费,他就是表示int类型的数值,但是int类型四个字节有时候在使用的时候有点浪费,所以就应运而生了,他的原理也很简单:
图只是指示性的用两个字节表示。编码的每个字节有效部分只有低7bits,每个字节的最高bit用来指示是否是最后一个字节。
非最高字节的bit7为0
最高字节的bit7为1
将leb128编码的数字转换为可读数字的规则是:除去每个字节的bit7,将每个字节剩余的7个bits拼接在一起,即为数字。
比如:
LEB128编码的0x02b0 ---> 转换后的数字0x0130
转换过程:
0x02b0 => 0000 0010 1011 0000 =>去除最高位=> 000 0010 011 0000 =>按4bits重排 => 00 0001 0011 0000 => 0x130
底层代码位于:android/dalvik/libdex/leb128.h
Java中也写了一个工具类: