大数据协作框架Hue
大数据协作框架Hue
- 大数据协作框架Hue
- 一概述
- 二Hue的安装和部署
- 三hue集成hadoop2x
- 四hue集成hive
- 五hive集成RDBMS
一,概述
1,参考文档
http://gethue.com/ 官网
http://github.com/cloudera/hue 源码
http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-cdh5.3.6/ hue安装指南3,特性:
- free&open source
- be productive
- 100%compatible
- 4dynamic search dashboar with solr(动态的solr集成)
- spark and hadoop notebooks
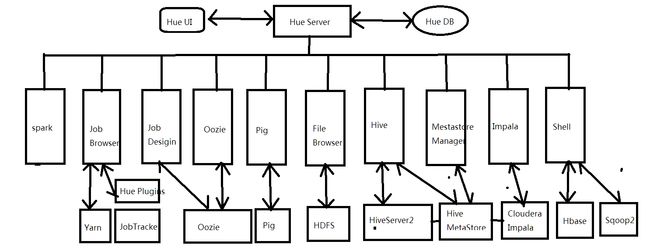
4,结构示意图:
二,Hue的安装和部署
1,下载源码包CDH5.3.6版本:
http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-cdh5.3.6.tar.gz2,虚拟机连接互联网
3,安装hue所以依赖的系统包,针对不同的unix系统,需要root权限
yum install ant asciidoc cyrus-sasl-devel cyrus-sasl-gssapi gcc gcc-c++ krb5-devel libtidy libxml2-devel libxslt-devel openldap-devel python-devel sqlite-devel openssl-devel mysql-devel gmp-devel4,解压hue源码包到指定的目录下
[root@xingyunfei001 app]# tar zxf hue-3.7.0-cdh5.3.6.tar.gz 5,编译源码包
[root@xingyunfei001 app]# cd hue-3.7.0-cdh5.3.6/[root@xingyunfei001 hue-3.7.0-cdh5.3.6]# make apps6,修改配置文件hue.ini
vi /opt/app/hue-3.7.0-cdh5.3.6/desktop/conf/hue.ini # Set this to a random string, the longer the better. # This is used for secure hashing in the session store. secret_key=qpbdxoewsqlkhztybvfidtvwekftusgdlofbcfghaswuicmqp # Webserver listens on this address and port http_host=xingyunfei001.comcn http_port=8888 # Time zone name time_zone=Asia/Shanghai7,启动hue
[hadoop001@xingyunfei001 hue-3.7.0-cdh5.3.6]$ build/env/bin/supervisor8,浏览器查看
http://xingyunfei001.com.cn:8888/accounts/login/?next=/
三,hue集成hadoop2.x
1,修改hadoop的hdfs-site.xml配置文件:
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>2,修改hadoop的core-site.xml配置文件
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>3,修改hue的hue.ini配置文件
[hadoop]
# Configuration for HDFS NameNode
# ------------------------------------------------------------------------
[[hdfs_clusters]]
# HA support by using HttpFs
[[[default]]]
# Enter the filesystem uri
fs_defaultfs=hdfs://xingyunfei001.com.cn:8020
# NameNode logical name.
## logical_name=
# Use WebHdfs/HttpFs as the communication mechanism.
# Domain should be the NameNode or HttpFs host.
# Default port is 14000 for HttpFs.
webhdfs_url=http://xingyunfei001.com.cn:50070/webhdfs/v1
# Change this if your HDFS cluster is Kerberos-secured
## security_enabled=false
# Default umask for file and directory creation, specified in an octal value.
## umask=022
# Directory of the Hadoop configuration
hadoop_hdfs_home=/opt/app/hadoop_2.5.0_cdh
hadoop_bin=/opt/app/hadoop_2.5.0_cdh/bin
hadoop_conf_dir=/opt/app/hadoop_2.5.0_cdh/etc/hadoop
[[yarn_clusters]]
[[[default]]]
# Enter the host on which you are running the ResourceManager
resourcemanager_host=xingyunfei001.com.cn
# The port where the ResourceManager IPC listens on
resourcemanager_port=8032
# Whether to submit jobs to this cluster
submit_to=True
# Resource Manager logical name (required for HA)
## logical_name=
# Change this if your YARN cluster is Kerberos-secured
## security_enabled=false
# URL of the ResourceManager API
resourcemanager_api_url=http://xingyunfei001.com.cn:8088
# URL of the ProxyServer API
proxy_api_url=http://xingyunfei001.com.cn:8088
# URL of the HistoryServer API
history_server_api_url=http://xingyunfei001.com.cn:19888
# In secure mode (HTTPS), if SSL certificates from Resource Manager's
# Rest Server have to be verified against certificate authority
## ssl_cert_ca_verify=False
# HA support by specifying multiple clusters
# e.g.
# [[[ha]]]
# Resource Manager logical name (required for HA)
## logical_name=my-rm-name
4,重新启动hdfs
[hadoop001@xingyunfei001 hadoop_2.5.0_cdh]$ sbin/start-all.sh
[hadoop001@xingyunfei001 hadoop_2.5.0_cdh]$ sbin/mr-jobhistory-daemon.sh start historyserver5,重新启动hue服务器
[hadoop001@xingyunfei001 hue-3.7.0-cdh5.3.6]$ build/env/bin/supervisor6,查看测试结果
四,hue集成hive
1,配置hue.ini配置文件
[beeswax]
# Host where HiveServer2 is running.
# If Kerberos security is enabled, use fully-qualified domain name (FQDN).
hive_server_host=xingyunfei001.com.cn
# Port where HiveServer2 Thrift server runs on.
hive_server_port=10000
# Hive configuration directory, where hive-site.xml is located
hive_conf_dir=/opt/app/hive_0.13.1_cdh/conf
# Timeout in seconds for thrift calls to Hive service
server_conn_timeout=120
# Choose whether Hue uses the GetLog() thrift call to retrieve Hive logs. # If false, Hue will use the FetchResults() thrift call instead. ## use_get_log_api=true # Set a LIMIT clause when browsing a partitioned table. # A positive value will be set as the LIMIT. If 0 or negative, do not set any limit. ## browse_partitioned_table_limit=250 # A limit to the number of rows that can be downloaded from a query. # A value of -1 means there will be no limit. # A maximum of 65,000 is applied to XLS downloads. ## download_row_limit=1000000 # Hue will try to close the Hive query when the user leaves the editor page. # This will free all the query resources in HiveServer2, but also make its results inaccessible. ## close_queries=false # Thrift version to use when communicating with HiveServer2 ## thrift_version=52,修改hive的hive-site.xml文件配置metastore server
<property>
<name>hive.metastore.uris</name>
<value>thrift://xingyunfei001.com.cn:9083</value>
</property>3,启动metastore server(先启动)和hiveserver2
nohup bin/hive --service metastore &[hadoop001@xingyunfei001 hive_0.13.1_cdh]$ bin/hiveserver24,修改hdfs文件系统的/tmp权限
[hadoop001@xingyunfei001 hadoop_2.5.0_cdh]$ bin/hdfs dfs -chmod -R o+x /tmp5,查看配置是否生效
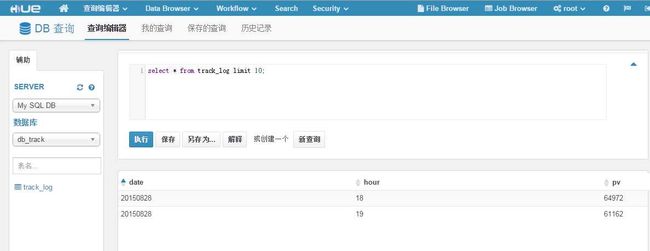
select id,url,referer from track_log limit 10;
五,hive集成RDBMS
1,修改hue.ini配置文件
[[databases]]
# sqlite configuration.
[[[sqlite]]]
# Name to show in the UI. nice_name=SQLite # For SQLite, name defines the path to the database. name=/opt/app/hue-3.7.0-cdh5.3.6/desktop/desktop.db # Database backend to use. engine=sqlite # Database options to send to the server when connecting. # https://docs.djangoproject.com/en/1.4/ref/databases/ ## options={} # mysql, oracle, or postgresql configuration. [[[mysql]]] # Name to show in the UI. nice_name="My SQL DB" # For MySQL and PostgreSQL, name is the name of the database. # For Oracle, Name is instance of the Oracle server. For express edition # this is 'xe' by default. ## name=mysqldb # Database backend to use. This can be: # 1. mysql # 2. postgresql # 3. oracle engine=mysql # IP or hostname of the database to connect to. host=xingyunfei001.com.cn # Port the database server is listening to. Defaults are: # 1. MySQL: 3306 # 2. PostgreSQL: 5432 # 3. Oracle Express Edition: 1521 port=3306 # Username to authenticate with when connecting to the database. user=root # Password matching the username to authenticate with when # connecting to the database. password=root # Database options to send to the server when connecting. # https://docs.djangoproject.com/en/1.4/ref/databases/ ## options={}2,重新启动hue
build/env/bin/supervisor3,查看配置是否生效