一个完整的MapReduce程序
最近初学Hadoop,仿照参考书上编写了一个wordcount程序,本文主要解决运行过程中出现的一些问题,下边先看一下这个项目。
项目结构

WordMapper类
package wordcount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}WordReducer类
package wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
WordMain类
package wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordMain {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.out.println("Usage:wordcount<in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordMain.class);
job.setMapperClass(WordMapper.class);
job.setCombinerClass(WordReducer.class);
job.setReducerClass(WordReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
统计单词存放文件
file1.txt
Hello, i love coding
are you ok?
Hello, i love hadoop
are you ok?file2.txt
Hello i love coding
are you ok?
Hello i love hadoop
are you ok?将wordcount打包
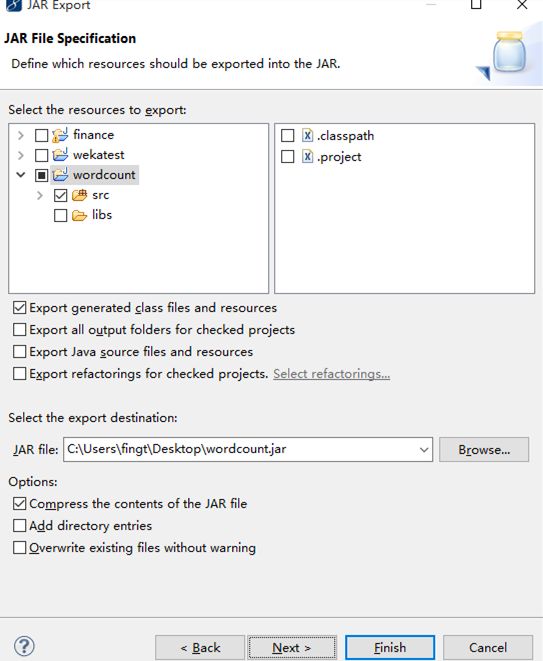
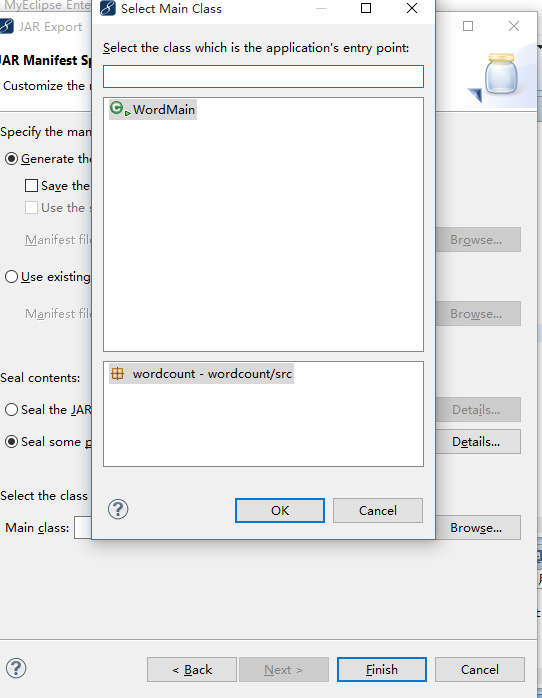
导入相关文件到虚拟机
在linux的opt文件下新建一个file文件,将file1.txt和file2.txt复制进去,同时将wordcount.jar也复制到opt目录中
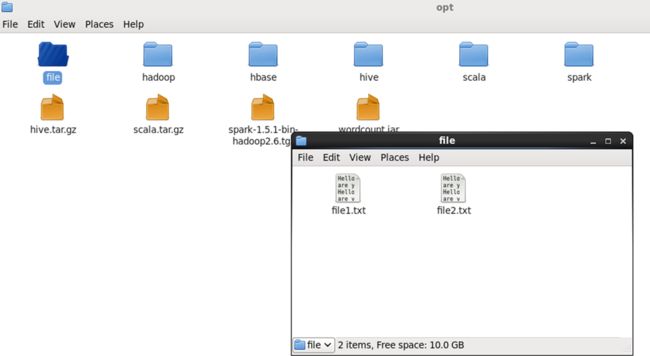
运行程序
进入hadoop的bin目录下,输入以下命令

运行时会出现
Input path does not exist错误
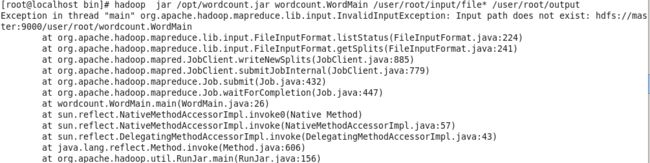
这是因为没有设置路径造成的。
回到WordMain代码中
改进后的WordMain代码:
package wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordMain {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "127.0.0.1:9001");
String[] ars = new String[] { "input", "output" };
String[] otherArgs = new GenericOptionsParser(conf, ars)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordMain.class);
job.setMapperClass(WordMapper.class);
job.setCombinerClass(WordReducer.class);
job.setReducerClass(WordReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
再次运行,没有错误

Hadoop常用的几个配置文件
core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/hadoop/name</value>
</property>
</configuration>mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/hadoop/mapred_system</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/hadoop/mapred_local</value>
</property>
</configuration>hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/hadoop/data</value>
</property>
</configuration>hadoop-env.sh
这个文件中主要是配置Java路径,我的路径为/usr/java/jdk1.7.0_75
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use. Required.
export JAVA_HOME=/usr/java/jdk1.7.0_75
# Extra Java CLASSPATH elements. Optional.
# export HADOOP_CLASSPATH=
# The maximum amount of heap to use, in MB. Default is 1000.
# export HADOOP_HEAPSIZE=2000
# Extra Java runtime options. Empty by default.
# export HADOOP_OPTS=-server
# Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_NAMENODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_SECONDARYNAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_DATANODE_OPTS"
export HADOOP_BALANCER_OPTS="-Dcom.sun.management.jmxremote $HADOOP_BALANCER_OPTS"
export HADOOP_JOBTRACKER_OPTS="-Dcom.sun.management.jmxremote $HADOOP_JOBTRACKER_OPTS"
# export HADOOP_TASKTRACKER_OPTS=
# The following applies to multiple commands (fs, dfs, fsck, distcp etc)
# export HADOOP_CLIENT_OPTS
# Extra ssh options. Empty by default.
# export HADOOP_SSH_OPTS="-o ConnectTimeout=1 -o SendEnv=HADOOP_CONF_DIR"
# Where log files are stored. $HADOOP_HOME/logs by default.
# export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
# File naming remote slave hosts. $HADOOP_HOME/conf/slaves by default.
# export HADOOP_SLAVES=${HADOOP_HOME}/conf/slaves
# host:path where hadoop code should be rsync'd from. Unset by default.
# export HADOOP_MASTER=master:/home/$USER/src/hadoop
# Seconds to sleep between slave commands. Unset by default. This
# can be useful in large clusters, where, e.g., slave rsyncs can
# otherwise arrive faster than the master can service them.
# export HADOOP_SLAVE_SLEEP=0.1
# The directory where pid files are stored. /tmp by default.
# export HADOOP_PID_DIR=/var/hadoop/pids
# A string representing this instance of hadoop. $USER by default.
# export HADOOP_IDENT_STRING=$USER
# The scheduling priority for daemon processes. See 'man nice'.
# export HADOOP_NICENESS=10/etc/hosts配置
输入ifconfig,查看当前虚拟机IP,找到inet addr
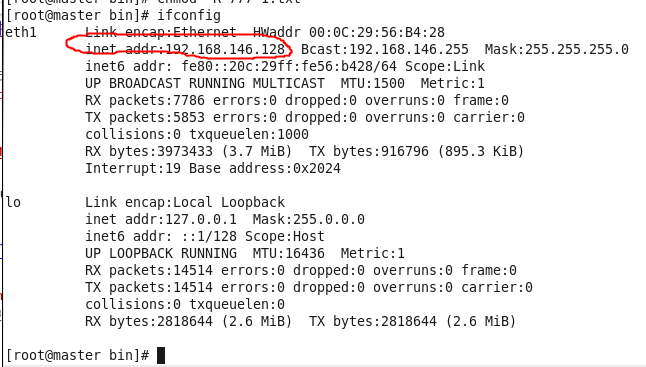
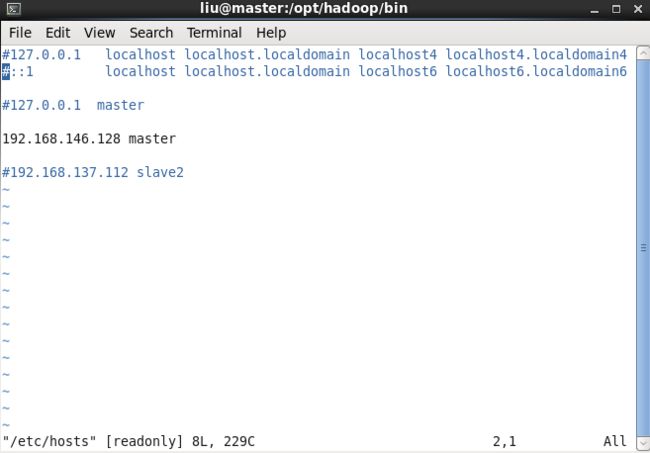
配置hosts,设置master为虚拟机的inet addr
eclipse连接hdfs成功
Eclipse运行Hadoop常见错误及解决办法
Eclipse下搭建Hadoop开发环境
Could not obtain block
Too many fetch-failures
unknown host: hadoop
NameNode is in safe mode
org.apache.hadoop.security.AccessControlException: Permission denied: user=d, access=WRITE, inode=”data”:zxg:supergroup:rwxr-xr-x