Studying note of GCC-3.4.6 source (82)
5.9. Tentative parser
5.9.1. Overview
Current GCC works out a tentative parser, as C++ isn’t a strict context independent syntax, the parser may need several attempts for parsing successfully. Thus what the parse needs is the ability to peek and it can re-parse if current try fails. This ability is provided by cp_lexer_peek_token.
643 static cp_token *
644 cp_lexer_peek_token (cp_lexer * lexer) in parser.c
645 {
646 cp_token *token;
647
648 /* If there are no tokens, read one now. */
649 if (!lexer->next_token)
650 cp_lexer_read_token (lexer);
651
652 /* Provide debugging output. */
653 if (cp_lexer_debugging_p (lexer))
654 {
655 fprintf (cp_lexer_debug_stream, "cp_lexer: peeking at token: ");
656 cp_lexer_print_token (cp_lexer_debug_stream, lexer->next_token);
657 fprintf (cp_lexer_debug_stream, "/n");
658 }
659
660 token = lexer->next_token;
661 cp_lexer_set_source_position_from_token (lexer, token);
662 return token;
663 }
Here see that unlike traditional LL(1) parser, the parser is LL(n). cp_lexer_peek_nth_token provides more powerful function to peek nth token ahead..
702 static cp_token *
703 cp_lexer_peek_nth_token (cp_lexer* lexer, size_t n) in parser.c
704 {
705 cp_token *token;
706
707 /* N is 1-based, not zero-based. */
708 my_friendly_assert (n > 0, 20000224);
709
710 /* Skip ahead from NEXT_TOKEN, reading more tokens as necessary. */
711 token = lexer->next_token;
712 /* If there are no tokens in the buffer, get one now. */
713 if (!token)
714 {
715 cp_lexer_read_token (lexer);
716 token = lexer->next_token;
717 }
718
719 /* Now, read tokens until we have enough. */
720 while (--n > 0)
721 {
722 /* Advance to the next token. */
723 token = cp_lexer_next_token (lexer, token);
724 /* If that's all the tokens we have, read a new one. */
725 if (token == lexer->last_token)
726 token = cp_lexer_read_token (lexer);
727 }
728
729 return token;
730 }
Function cp_lexer_peek_token, cp_lexer_peek_nth_token and cp_lexer_read_token never move first_token. When we recognize a token’s meaning definitely (e.g., keywords), the token shouldn’t participate in next try, which indicates the token has been consumed. The function consume tokens is cp_lexer_consume_token.
737 static cp_token *
738 cp_lexer_consume_token (cp_lexer* lexer) n parser.c
739 {
740 cp_token *token;
741
742 /* If there are no tokens, read one now. */
743 if (!lexer->next_token)
744 cp_lexer_read_token (lexer);
745
746 /* Remember the token we'll be returning. */
747 token = lexer->next_token;
748
749 /* Increment NEXT_TOKEN. */
750 lexer->next_token = cp_lexer_next_token (lexer,
751 lexer->next_token);
752 /* Check to see if we're all out of tokens. */
753 if (lexer->next_token == lexer->last_token)
754 lexer->next_token = NULL;
755
756 /* If we're not saving tokens, then move FIRST_TOKEN too. */
757 if (!cp_lexer_saving_tokens (lexer))
758 {
759 /* If there are no tokens available, set FIRST_TOKEN to NULL. */
760 if (!lexer->next_token)
761 lexer->first_token = NULL;
762 else
763 lexer->first_token = lexer->next_token;
764 }
765
766 /* Provide debugging output. */
767 if (cp_lexer_debugging_p (lexer))
768 {
769 fprintf (cp_lexer_debug_stream, "cp_lexer: consuming token: ");
770 cp_lexer_print_token (cp_lexer_debug_stream, token);
771 fprintf (cp_lexer_debug_stream, "/n");
772 }
773
774 return token;
775 }
Field next_token in cp_lexer always refers to the first token that being consumed, so at line 750 it advances the token pointed by the field by one. As field last_token is the end marker for cached tokens, when next_token reaches that point, next_token is set to NULL to indicate no token left.
Also at line 757, cp_lexer_saving_tokens checks whether array saved_tokens in cp_lexer is empty. If not empty, it means the token should be kept as requested by parser (triggers by cp_lexer_save_tokens); otherwise, advances field first_token to free the space of the token.
Tentative parsing is triggered by cp_parser_parse_tentatively. First of all is preparing a context for the parse. Then in later operation, at seeing this context, the compiler knows is doing tentative parse. Via this context stack, mulitiple nested tentative parses can be taken.
15388 static void
15389 cp_parser_parse_tentatively (cp_parser* parser) in parser.c
15390 {
15391 /* Enter a new parsing context. */
15392 parser->context = cp_parser_context_new (parser->context);
15393 /* Begin saving tokens. */
15394 cp_lexer_save_tokens (parser->lexer);
15395 /* In order to avoid repetitive access control error messages,
15396 access checks are queued up until we are no longer parsing
15397 tentatively. */
15398 push_deferring_access_checks (dk_deferred);
15399 }
Next at line 15398, a new access control item is pushed into deferred_access_stack. It is a deferred-checking, because the parser has on idea what coming tokens stand for, but attempts to recognize them for all possiblilty. And attemption may be taken several times; it needs not take access checking during the try. The access control will be checked at time of exiting tentative parse, at which point, the parser would have known what is the tokens for.
As we have seen, in cp_lexer, slot first_token points to the first peeked token, and last_token refers to the position of last cached token, then next_token points out the token will be peeked next. Thus tokens between first_token and next_token have been peeked, and tokens between next_token and last_token are being peeked (if first_token isn’t equal to next_token, it means we are in nested tentative parse). See that during this time parse, first_token won’t be changed too, so if we need to reparse, just restoring next_token is enough. recorded. That is why cp_lexer_save_tokens only records the difference between first_token and next_token (gotten by cp_lexer_token_difference).
844 static void
845 cp_lexer_save_tokens (cp_lexer* lexer) in parser.c
846 {
847 /* Provide debugging output. */
848 if (cp_lexer_debugging_p (lexer))
849 fprintf (cp_lexer_debug_stream, "cp_lexer: saving tokens/n");
850
851 /* Make sure that LEXER->NEXT_TOKEN is non-NULL so that we can
852 restore the tokens if required. */
853 if (!lexer->next_token)
854 cp_lexer_read_token (lexer);
855
856 VARRAY_PUSH_INT (lexer->saved_tokens,
857 cp_lexer_token_difference (lexer,
858 lexer->first_token,
859 lexer->next_token));
860 }
After cp_lexer_save_tokens is invoked, saved_tokens slot is not empty. Then look back into cp_lexer_consume_token, with non-empty save_tokens, no token will be consumed as result (first_token won’t be advanced as normal).
By chaining tentative parse, we can separate a big tentative parse into several small tentative parses. For example, we are going to parse a statement with 3 grammatical parts, assuming the conbimation of these 3 parts is shown as below figure.
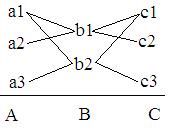
Now we can decompose this big parse into 3 independent small parses: A, B, and C. If the input is a1b1c2, the tentative parse A first successes, next so do parse B and C, then the big parse formed by A, B, C successes. Next by cp_parser_commit_to_tentative_parse, we commit these parses. And if the input is a1b1c3, then parse C returns incompatible c3, and the parse fails. The context of parse C will be put in CP_PARSER_STATUS_KIND_ERROR status.
15403 static void
15404 cp_parser_commit_to_tentative_parse (cp_parser* parser) in parser.c
15405 {
15406 cp_parser_context *context;
15407 cp_lexer *lexer;
15408
15409 /* Mark all of the levels as committed. */
15410 lexer = parser->lexer;
15411 for (context = parser->context; context->next; context = context->next)
15412 {
15413 if (context->status == CP_PARSER_STATUS_KIND_COMMITTED)
15414 break;
15415 context->status = CP_PARSER_STATUS_KIND_COMMITTED;
15416 while (!cp_lexer_saving_tokens (lexer))
15417 lexer = lexer->next;
15418 cp_lexer_commit_tokens (lexer);
15419 }
15420 }
See that cp_lexer_commit_tokens will pop one item out of save_tokens, and FOR loop at line 15411 would sweep all uncommitted contexts, so in next invocation of cp_lexer_consume_token can update first_token to next_token. And if tentative parse is not started, the FOR loop will exit immediately without executing, as the main context always has a null next slot.
864 static void
865 cp_lexer_commit_tokens (cp_lexer* lexer) in parser.c
866 {
867 /* Provide debugging output. */
868 if (cp_lexer_debugging_p (lexer))
869 fprintf (cp_lexer_debug_stream, "cp_lexer: committing tokens/n");
870
871 VARRAY_POP (lexer->saved_tokens);
872 }
Notice that though committing tentative parses, their contexts are not released. Only exitting their contexts, the parses are regarded as finished. Besides, if error occurs during the parse, we sould stop this parse and rollback to the start point for next scheme. To stop the tentative parse and exit from the context, we need invoke cp_parser_parse_definitely. And also see that if the parse has been committed, it is almost a zombie.
15438 static bool
15439 cp_parser_parse_definitely (cp_parser* parser) in parser.c
15440 {
15441 bool error_occurred;
15442 cp_parser_context *context;
15443
15444 /* Remember whether or not an error occurred, since we are about to
15445 destroy that information. */
15446 error_occurred = cp_parser_error_occurred (parser);
15447 /* Remove the topmost context from the stack. */
15448 context = parser->context;
15449 parser->context = context->next;
15450 /* If no parse errors occurred, commit to the tentative parse. */
15451 if (!error_occurred)
15452 {
15453 /* Commit to the tokens read tentatively, unless that was
15454 already done. */
15455 if (context->status != CP_PARSER_STATUS_KIND_COMMITTED)
15456 cp_lexer_commit_tokens (parser->lexer);
15457
15458 pop_to_parent_deferring_access_checks ();
15459 }
15460 /* Otherwise, if errors occurred, roll back our state so that things
15461 are just as they were before we began the tentative parse. */
15462 else
15463 {
15464 cp_lexer_rollback_tokens (parser->lexer);
15465 pop_deferring_access_checks ();
15466 }
15467 /* Add the context to the front of the free list. */
15468 context->next = cp_parser_context_free_list;
15469 cp_parser_context_free_list = context;
15470
15471 return !error_occurred;
15472 }
In cp_parser_parse_tentatively, at starting the tentative parse, we postpone the access control checking. Now at stopping this parse, if it successes, it is time to perform the deferred checking, if it fails, it still needs to remove the deferred checking and lets next try to put its one in.
216 void
217 pop_to_parent_deferring_access_checks (void) in semantics.c
218 {
219 tree deferred_check = get_deferred_access_checks ();
220 deferred_access *d1 = deferred_access_stack;
221 deferred_access *d2 = deferred_access_stack->next;
222 deferred_access *d3 = deferred_access_stack->next->next;
223
224 /* Temporary swap the order of the top two states, just to make
225 sure the garbage collector will not reclaim the memory during
226 processing below. */
227 deferred_access_stack = d2;
228 d2->next = d1;
229 d1->next = d3;
230
231 for ( ; deferred_check; deferred_check = TREE_CHAIN (deferred_check))
232 /* Perform deferred check if required. */
233 perform_or_defer_access_check (TREE_PURPOSE (deferred_check),
234 TREE_VALUE (deferred_check));
235
236 deferred_access_stack = d1;
237 d1->next = d2;
238 d2->next = d3;
239 pop_deferring_access_checks ();
240 }
We have seen that deferred_access_stack is a stack of deferred_access. Every node in the stack stands for specific scope with deferred checking applied, in which field deferred_access_checks records the deferred checkings required. Function get_deferred_access_checks returns deferred checkings for current scope.
206 tree
207 get_deferred_access_checks (void) in semantics.c
208 {
209 return deferred_access_stack->deferred_access_checks;
210 }
We will come back to perform_or_defer_access_check in next section. After performing the deferred checkings, it pops out these checkings from the stack.
187 void
188 pop_deferring_access_checks (void) in semantics.c
189 {
190 deferred_access *d = deferred_access_stack;
191 deferred_access_stack = d->next;
192
193 /* Remove references to access checks TREE_LIST. */
194 d->deferred_access_checks = NULL_TREE;
195
196 /* Store in free list for later use. */
197 d->next = deferred_access_free_list;
198 deferred_access_free_list = d;
199 }
Rollback to the start point in case of error is done by cp_lexer_rollback_tokens.
877 static void
878 cp_lexer_rollback_tokens (cp_lexer* lexer) in parser.c
879 {
880 size_t delta;
881
882 /* Provide debugging output. */
883 if (cp_lexer_debugging_p (lexer))
884 fprintf (cp_lexer_debug_stream, "cp_lexer: restoring tokens/n");
885
886 /* Find the token that was the NEXT_TOKEN when we started saving
887 tokens. */
888 delta = VARRAY_TOP_INT(lexer->saved_tokens);
889 /* Make it the next token again now. */
890 lexer->next_token = cp_lexer_advance_token (lexer,
891 lexer->first_token,
892 delta);
893 /* It might be the case that there were no tokens when we started
894 saving tokens, but that there are some tokens now. */
895 if (!lexer->next_token && lexer->first_token)
896 lexer->next_token = lexer->first_token;
897
898 /* Stop saving tokens. */
899 VARRAY_POP (lexer->saved_tokens);
900 }
As no token is really consumed during tentative parse, first_token is always the same, gets next_token at start poin is simple and straight-forward.
449 static cp_token *
450 cp_lexer_advance_token (cp_lexer *lexer, cp_token *token, ptrdiff_t n) in parser.c
451 {
452 token += n;
453 if (token >= lexer->buffer_end)
454 token = lexer->buffer + (token - lexer->buffer_end);
455 return token;
456 }
Here it is very obviously that the calling of cp_parser_parse_tentatively must be matched by that of cp_parser_parse_definitely to keep deferred checking stack in shape.