JavaEE_Web文件下载_lesson2_ JavaEE下载文件,中文乱码解决方法(Content-Disposition)
上一节我们讲解了Java web下载的知识 传送门( ),
如果下载的文件名含有中文的情况,经常会被显示为乱码,解决办法有多种,如下:
第一种: 设置 response.setHeader("Content-Disposition", "attachment; filename=" + java.net.URLEncoder.encode(fileName, "UTF-8"));这里将文件名编码成UTF-8的格式,就不会出现URL出错了。
IE6下注意中文文字不能超过超过17个。(这是IE的bug,参见微软的知识库文章 KB816868 。可能是IE在处理 Response Header 的时候,对header的长度限制在150字节左右。而一个汉字编码成UTF-8是9个字节,那么17个字便是153个字节,所以会报错。而且不跟后缀也不对.)
第二种:设置response.setHeader( "Content-Disposition", "attachment;filename=" + new String( fileName.getBytes("gb2312"), "ISO8859-1" ) );将中文名编码为ISO8859-1的方式。不过该编码只支持简体中文.
在确保附件文件名都是简 体中文字的情况下,那么这个办法确实是最有效的,不用让客户逐个的升级IE。如果台湾同胞用,把gb2312改成big5就行。但现在的系统通常都加入了 国际化的支持,普遍使用UTF-8。如果文件名中又有简体中文字,又有繁体中文,还有日文。那么乱码便产生了。另外,在上Firefox (v1.0-en)下载也是乱码。
改进版一: 结合 方法一,方法二
fileName = URLEncoder.encode(fileNameSrc,"UTF-8");
if(fileName.length()>150)//解决IE 6.0 bug
fileName=new String(fileNameSrc.getBytes("GBK"),"ISO-8859-1");
response.setHeader( "Content-Disposition", "attachment;filename=" + fileName);
改进版二(最优化版):
response.setHeader("Content-disposition","attachment; filename="filename);
filename= new String(fileNameSrc.getBytes("utf-8"), "ISO_8859_1");
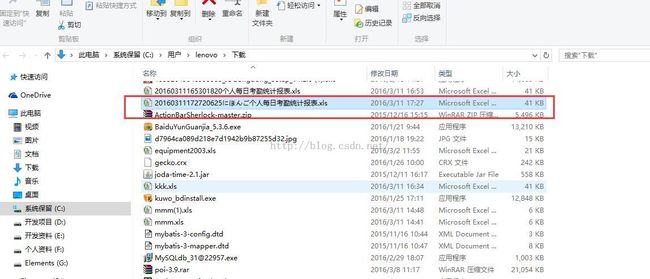
最优化版测试结果:
WEB端后台:
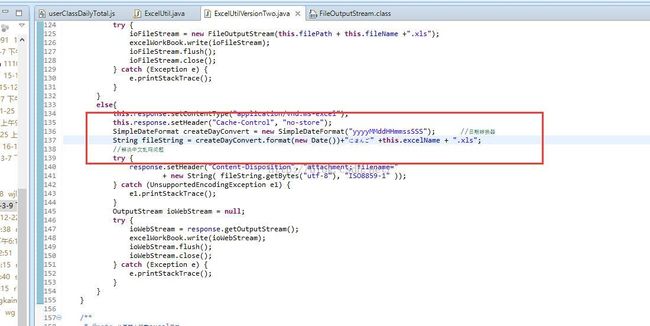
点击下载后生成的文件名: