Buffer Cache 原理
http://blog.csdn.net/robinson1988/article/details/5982996
我们在监控等待事件,查看AWR,ASH报表的时候经常会看到latch: cache buffers chains,有可能还会看到latch: cache buffers lru chain这些等待事件,对于cache buffers chains这个等待事件,相信是大家最为头疼的,如果对Buffer Cache理解不深,那么你就遇到这些等待事件就会束手无策。本文的目的就是通过讲解Buffer Cache原理,使大家得心应手的处理这些latch争用。
Buffer Cache概述
Buffer Cache是SGA的一部分,Oracle利用Buffer Cache来管理data block,Buffer Cache的最终目的就是尽可能的减少磁盘I/O。Buffer Cache中主要有3大结构用来管理Buffer Cache。
Hash Bucket & Hash Chain List :Hash Bucket与Hash Chain List用来实现data block的快速定位。
LRU List :挂载有指向具体的free buffer, pinned buffer以及还没有被移动到 write list的dirty buffer 等信息。所谓的free buffer就是指没有包含任何数据的buffer,所谓的pinned buffer,就是指当前正在被访问的buffer。
Write(Dirty)List :挂载有指向具体的 dirty block的信息。所谓的dirty block,就是指在 buffer cache中被修改过但是还没有被写入到磁盘的block。
Hash Bucket与Hash Chain List
Oracle将buffer cache中所有的buffer通过一个内部的Hash算法运算之后,将这些buffer放到不同的 Hash Bucket中。每一个Hash Bucket中都有一个
Hash Chain List,通过这个list,将这个Bucket中的block串联起来。
下面举个简单的例子来介绍一下Hash 算法,Oracle的Hash 算法肯定没这么简单,具体算法只有Oracle公司知道。
• 一个简单的mod函数 ,我们去mod 4
Ø 1 mod 4 = 1
Ø 2 mod 4 = 2
Ø 3 mod 4 = 3
Ø 4 mod 4 = 0
Ø 5 mod 4 = 1
Ø 6 mod 4 = 2
Ø 7 mod 4 = 3
Ø 8 mod 4 = 0
……………省略…………………..
那么这里就相当于创建了4个Hash Bucket
如果有如下block:
blcok :DBA(1,1) ------> (1+1) mod 4 =2
block :DBA(1,2) ------> (1+2) mod 4 =3
block :DBA(1,3) ------> (1+3) mod 4 =0
block :DBA(1,4) ------> (1+4) mod 4 =1
block :DBA(1,5) ------> (1+5) mod 5 =2
………........省略…………………....
比如我要访问block(1,5),那么我对它进行Hash运算,然后到Hash Bucket为2的这个Bucket里面去寻找,Hash Bucket 为2的这个Bucket 现在有2个block,
这2个block是挂在Hash Chain List上面的
Hash Chain List到底是怎么组成的呢?这里我们就要提到x$bh这个基表了
SQL> desc x$bh
Name Null? Type
----------------------- - ----------------
ADDR RAW(8) ---block在buffer cache中的address
INDX NUMBER
INST_ID NUMBER
HLADDR RAW(8) --latch:cache buffers chains 的address
BLSIZ NUMBER
NXT_HASH RAW(8) ---指向同一个Hash Chain List的下一个block
PRV_HASH RAW(8) ---指向同一个Hash Chain List的上一个block
NXT_REPL RAW(8)---指向LRU list中的下一个block
PRV_REPL RAW(8)---指向LRU list中的上一个block
………………省略…………………………
Hash Chain List就是由x$bh中的NXT_HASH,PRV_HASH 这2个指针构成了一个双向链表,其示意图如下:
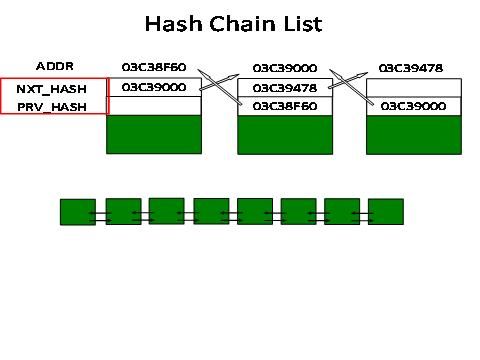
通过NXT_HASH,PRV_HASH这2个指针,那么在同一个Hash Chain List的block就串联起来了。
理解了Hash Bucket 和 Hash Chain List,我们现在来看看
Hash Bucket 与 Hash Chain List管理Buffer Cache 的结构示意图
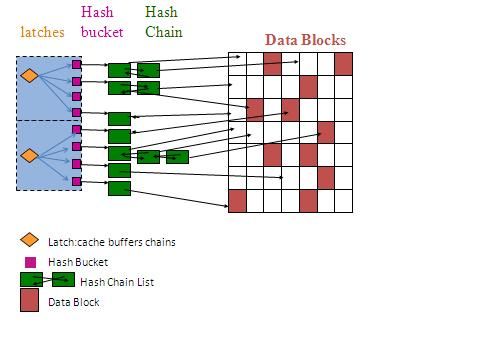
从图中我们可以看到,一个latch:cache buffers chains(x$bh.hladdr) 可以保护多个Hash Bucket,也就是说,如果我要访问某个block,我首先要获得这个latch,一个Hash Bucket对应一个Hash Chain List,而这个
Hash Chain List挂载了一个或者多个Buffer Header。
Hash Bucket的数量受隐含参数_db_block_hash_buckets的影响,
Latch:cache buffers chains的数量受隐含参数_db_block_hash_latches的影响
该隐含参数可以通过如下查询查看:
SQL> select * from v$version;
BANNER
------------------------------------------------------------------
Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 - 64bi
SQL> SELECT x.ksppinm NAME, y.ksppstvl VALUE, x.ksppdesc describ
2 FROM x$ksppi x, x$ksppcv y
3 WHERE x.inst_id = USERENV ('Instance')
4 AND y.inst_id = USERENV ('Instance')
5 AND x.indx = y.indx
6 AND x.ksppinm LIKE '%_db_block_hash%'
7 /
NAME VALUE DESCRIB
------------------------- --------------- --------------------------------------
_db_block_hash_buckets 524288 Number of database block hash buckets
_db_block_hash_latches 16384 Number of database block hash latches
_db_block_hash_buckets 该隐含参数在8i以前 等于db_block_buffers/4的下一个素数
到了8i 该参数等于 db_block_buffers*2 ,
到了9i 以后,该参数取的是小于且最接近 db_block_buffers*2 的一个素数
_db_block_hash_latches 该隐含参数表示的是 cache buffers chains latch的数量,它怎么计算的我们不用深究
可以看到,从8i以后Hash Bucket数量比以前提升了8倍。
可以用下面查询计算cache buffers chains latch的数量
SQL> select count(*) from v$latch_children a,v$latchname b where a.latch#=b.latch# and b.name='cache buffers chains';
COUNT(*)
----------
16384
还可以用下面查询计算cache buffers chains latch的数量
SQL> select count(distinct hladdr) from x$bh ;
COUNT(DISTINCTHLADDR)
---------------------
16384
根据我们的查询,那么一个cache buffers chains latch 平均下来要管理32个Hash Bucket,那么现在我们随意的找一个latch,来验证一下前面提到的结构图。
SQL> select * from (select hladdr,count(*) from x$bh group by hladdr) where rownum<=5;
HLADDR COUNT(*)
---------------- ----------
C000000469F08828 15
C000000469F088F0 14
C000000469F089B8 15
C000000469F08A80 24
C000000469F08B48 17
我们查询latch address 为C000000469F08828 所保护的data block
SQL> select hladdr,obj,dbarfil,dbablk, nxt_hash,prv_hash from x$bh where hladdr='C000000469F08828' order by obj;
HLADDR OBJ DBARFIL DBABLK NXT_HASH PRV_HASH
---------------- ---------- ---------- ---------- ---------------- ----------------
C000000469F08828 2 388 322034 C0000004686ECBD0 C00000017EF8D658
C000000469F08828 2 388 396246 C0000004686ECA60 C0000004686ECA60
C000000469F08828 18 411 674831 C0000004686ECC00 C0000004686ECC00
C000000469F08828 216 411 438948 C0000004686ECBB0 C0000004686ECBB0
C000000469F08828 216 220 100217 C0000004686ECAA0 C0000004686ECAA0
C000000469F08828 216 220 60942 C000000151FB5DD8 C0000004686ECBD0
C000000469F08828 569 411 67655 C00000011FF81668 C0000001E8FB7AC0
C000000469F08828 569 280 1294 C0000004686ECB60 C000000177F9F078
C000000469F08828 58744570 210 332639 C000000177F9F078 C0000004686ECB60
C000000469F08828 65178270 254 408901 C0000004686ECBF0 C0000004686ECBF0
C000000469F08828 65347592 84 615093 C0000004686ECB90 C0000004686ECB90
C000000469F08828 65349200 765 1259399 C0000004686ECA70 C0000004686ECA70
请观察DBA(388,396246),它的NXT_HASH与PRV_HASH相同,也就是说DBA(388,396246)挂载在只包含有1个data block的 Hash Chain上。
另外也请注意,我通过count(*)计算出来的时候有15个block,但是查询之后就变成了12个block,那说明有3个block被刷到磁盘上了。
当一个用户进程想要访问Block(569,411):
l 对该Block运用Hash算法,得到Hash值。
l 获得cache buffers chains latch
l 到相应的Hash Bucket中搜寻相应Buffer Header
l 如果找到相应的Buffer Header,然后判断该Buffer的状态,看是否需要构造CR Block,或者Buffer处于pin的状态,最后读取。
l 如果找不到,就从磁盘读入到Buffer Cache中。
在Oracle9i以前,如果其它用户进程已经获得了这个latch,那么新的进程就必须等待,直到该用户进程搜索完毕(搜索完毕之后就会释放该latch)。从Oracle9i开始 cache buffers chains latch可以只读共享,也就是说用户进程A以只读(select)的方式访问Block(84,615093),这个时候获得了该latch,同时用户进程B也以只读的方式访问Block(765,1259399),那么这个时候由于是只读的访问,用户进程B也可以获得该latch。但是,如果用户进程B要以独占的方式访问Block(765,1259399),那么用户进程B就会等待用户进程A释放该latch,这个时候Oracle就会对用户进程B标记一个latch:cache buffers chains的等待事件。
我们遇到了latch:cache buffers chains该怎么办?
l 不够优化的SQL。大量逻辑读的SQL语句就有可能产生非常严重的latch:cache buffers chains等待,因为每次要访问一个block,就需要获得该latch,由于有大量的逻辑读,那么就增加了latch:cache buffers chains争用的机率。
Ø 对于正在运行的SQL语句,产生非常严重的latch:cache buffers chains争用,可以利用下面SQL查看执行计划,并设法优化SQL语句。
select * from table(dbms_xplan.display_cursor('sql_id',sql_child_number));
Ø 如果SQL已经运行完毕,我们就看AWR报表里面的SQL Statistics->SQL ordered by Gets->Gets per Exec,试图优化这些SQL。
l 热点块争用。
Ø 下面查询查出Top 5 的争用的latch address。
select * from( select CHILD#,ADDR,GETS ,MISSES,SLEEPS from v$latch_children where name = 'cache buffers chains' and misses>0 and sleeps>0 order by 5 desc, 1, 2, 3) where rownum<6;
Ø 然后利用下面查询找出Hot block。
select /*+ RULE */e.owner ||'.'|| e.segment_name segment_name,e.extent_id extent#,x.dbablk - e.block_id + 1 block#,x.tch, /* sometimes tch=0,we need to see tim */
x.tim ,l.child#fromv$latch_children l,x$bh x,dba_extents ewherex.hladdr = '&ADDR' ande.file_id = x.file# andx.hladdr = l.addr andx.dbablk between e.block_id and e.block_id + e.blocks -1order by x.tch desc ;
l Hash Bucket太少,需要更改_db_block_hash_buckets隐含参数。其实在Oracle9i之后,我们基本上不会遇到这个问题了,除非遇到Bug。所以这个是不推荐的,记住,在对Oracle的隐含参数做修改之前一定要咨询Oracle Support。
LRU List与LRU Write List
前面已经提到过了,如果一个用户进程发现某个block不在Buffer Cache中,那么用户进程就会从磁盘上将这个block读入Buffer Cache。在将block读入到Buffer Cache之前,首先要在LRU list上寻找Free的buffer,在寻找过程中,如果发现了Dirty Buffer就将其移动到 LRU Write List上。如果Dirty Queue超过了阀值25%(如下面查询所示),那么DBWn就会将Dirty Buffer写入到磁盘中。
SQL> select kvittag,kvitval,kvitdsc from x$kvit where kvittag in('kcbldq','kcbfsp');
KVITTAG KVITVAL KVITDSC
-------------------- ---------- -------------------------------------------------------
kcbldq 25 large dirty queue if kcbclw reaches this
kcbfsp 40 Max percentage of LRU list foreground can scan for free
根据上面的查询我们还知道,当某个用户进程扫描LRU list超过40%都还没找到Free Buffer,那么这个时候用户进程将停止扫描LRU list,同时通知DBWn将Dirty Buffer写入磁盘,用户进程也将记录一个free buffer wait等待事件。如果我们经常看到free buffer wait等待事件,那么我们就应该考虑加大Buffer Cache了。
从Oracle8i开始,LRU List和Dirty List都增加了辅助List,Oracle将LRU List和LRU Write List统称为Working Set(WS)。每个WS中都包含了几个功能不同的List,每个WS都会有一个Cache Buffers LRU chain Latch的保护(知识来源于DSI405)。如果数据库设置了多个DBWR,数据库会存在多个WS,如果Buffer Cache中启用了多缓存池(default,keep,recycle)时,每个独立的缓冲池都会有自己的WS。那么下面我们来查询一下,以验证上述理论:
SQL> SELECT x.ksppinm NAME, y.ksppstvl VALUE, x.ksppdesc describ
2 FROM x$ksppi x, x$ksppcv y
3 WHERE x.inst_id = USERENV ('Instance')
4 AND y.inst_id = USERENV ('Instance')
5 AND x.indx = y.indx
6 AND x.ksppinm LIKE '%db_block_lru_latches%'
7 /
NAME VALUE DESCRIB
------------------------------ ---------- -----------------------------
_db_block_lru_latches 32 number of lru latches
SQL> show parameter db_writer
NAME TYPE VALUE
----------------------------- -------------- ------
db_writer_processes inte 2
SQL> show parameter cpu_count
NAME TYPE VALUE
------------------------------------ -------------------- ------------
cpu_count integer 8
我们查到有32个Cache Buffers LRU chain Latch,从Oracle9i开始,_db_block_lru_latches是CPU_COUNT的4倍,如果DB_WITER_PROCESS小于4,置于DB_WITER_PROCESS大于四这个不知道,另外也没见过哪个数据库参数的DB_WITER_PROCESS大于4那我们来查询一下有多少个Working Set:
SQL> select count(*) from x$kcbwds;
COUNT(*)
----------
32
我们查询到有32个WS,并不代表数据库就一定使用了这32个WS,有些WS 是数据库预分配的,这样在我们启用Keep pool, recycle pool的时候就不用重启数据库了。
那么我们这里就只是用了4个WS。
SQL> select count(*) from x$kcbwds where CNUM_REPL>0;
COUNT(*)
----------
4
上面查询了多次X$KCBWDS基表,现在我们来看看这个基表的主要字段
ADDR RAW(4) ------address
INDX NUMBER
INST_ID NUMBER --------instance number
SET_ID NUMBER --------work set id
DBWR_NUM NUMBER ------DBWR编号
BLK_SIZE NUMBER ----------WORKSET的BLOCK SIZE
PROC_GROUP NUMBER
CNUM_SET NUMBER
FLAG NUMBER
CKPT_LATCH RAW(4) CHECKPOINT LATCH
CKPT_LATCH1 RAW(4)
SET_LATCH RAW(4) NEXT REPLACEMENT CHAIN
NXT_REPL RAW(4) PRV REPLACEMENT CHAIN
PRV_REPL RAW(4) REPLACEMENT AUX CHAIN
NXT_REPLAX RAW(4)
PRV_REPLAX RAW(4)
CNUM_REPL NUMBER REPLACEMENT CHIAN上的BLOCK数
ANUM_REPL NUMBER AUX CHAIN上的BLOCK 数
COLD_HD RAW(4) COLD HEAD的地址
HBMAX NUMBER HOT端的最大BUFFER数量
HBUFS NUMBER HOT端的当前BUFFER数量
NXT_WRITE RAW(4) LRU-W链
PRV_WRITE RAW(4) LRU-W链
NXT_WRITEAX RAW(4) LRU-W AUX链
PRV_WRITEAX RAW(4) LRU-W AUX链
CNUM_WRITE NUMBER LRU-W的BUFFER数
ANUM_WRITE NUMBER LRU-W AUX的BUFFER数
NXT_XOBJ RAW(4) REUSE OBJ链(当TRUNCATE,DROP等操作时使用)
PRV_XOBJ RAW(4) REUSE OBJ链
NXT_XOBJAX RAW(4) REUSE OBJ AUX链
PRV_XOBJAX RAW(4)
CNUM_XOBJ NUMBER
ANUM_XOBJ NUMBER
NXT_XRNG RAW(4) reuse range链(TABLESPACE OFFLINE等操作的时候使用)
PRV_XRNG RAW(4)
NXT_XRNGAX RAW(4) REUSE RANGE AUX链
PRV_XRNGAX RAW(4)
请注意红色字段,正是由于红色字段,以及前面提到过的x$bh中的NXT_REPL,PRV_REPL 字段形成了LRU List 以及LRU Write List。
下图就是LRU List的结构示意图
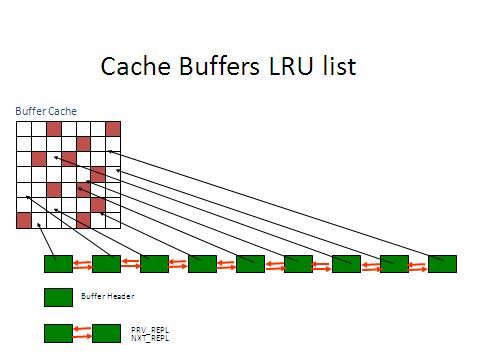
那增加这些AUX List究竟是干嘛的呢?在数据库启动之后,Buffer首先被存放在LRU AUX List上,用户进程搜索Free Buffer就会从LRU AUX List 的末/冷端进行。当这些块被修改后或者是用户进程要构造CR块的时候(要构造CR块也就表明这个块不满足读一致性,是Dirty的),在LRU AUX List上的Buffer就会被移动到LRU Main List的中间,记住是中间不是头部也不是末尾,那么DBWR来搜索Dirty Buffer就可以从LRU Main List开始(注意:DBWR 来搜索LRU Main List 是由于增量检查点导致的),DBWR在搜索LRU Main List的时候如果发现冷的可以被重复使用的Buffer,就会将其移动到LRU AUX List上,这样搜索LRU Main List上的Buffer基本都是Dirty Buffer,提高了搜索效率。DBWR将搜索到的Dirty Buffer移动到LRUW Main List,当需要将这个Dirty Buffer写出的时候,就把这个Dirty Buffer移动到LRUW AUX List,这样,当DBWR要执行写出可以从LRUW AUX List写出,这其实是一个异步的写出机制。(知识来源Metalink: 157868.1)
根据上面的讲解,当用户进程要将Block从磁盘读入到Buffer Cache中需要获得Cache Buffers LRU chain Latch,或者是DBWR扫描LRU Main List的时候要获得Cache Buffers LRU chain Latch。
所以,当我们发现AWR报表上面Cache Buffers LRU chain Latch排名很靠前,那么我们可以采取如下方法:
l 加大Buffer Cache,过小的Buffer Cache导致大量的磁盘I/O,必然引发
Cache Buffers LRU chain Latch竞争。
l 优化具有大量全表扫描,高磁盘I/O的SQL。如果SQL效率很低,大量的全表扫描,或者扫描没有选择性的索引就会引发这个问题。
l 使用多缓冲池技术,把Hot Segments Keep起来,Hot Segments的信息可以从AWR 报表中的Segments Statistics中得到。
关于Buffer Cache就只能到这里了,不能再深入了,资料实在太少太凌乱。