【03】spring源码解析之配置文件context:component-scan 解析流程
<context:component-scan base-package="com.wtf.demo.spring.beans"/> <context:annotation-config/>
以ClassPathXmlApplicationContext为例,当new一个ClassPathXmlApplicationContext对象,里面传入application.xml配置文件,然后spring会读取这个xml文件的context:component-scan节点和base-package属性,整体的时序图如下:
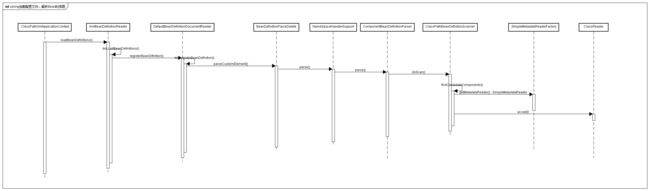
从上图可以看出,第一步是把所有定义的Bean的BeanDefinitions读取出来,需要一下步骤
1、定位资源文件(class)
2、解析xml文件
3、根据xml文件中的配置,找到class文件
4、读取包下面的所有class文件,然后进行调用ClassReader类的accpet方法,分析class文件,过滤出带有spring注解的类(Component,respositr,service,controller等注解是属于Component的注解的子类)
5、重新组装过滤出来的class类,注入相关默认属性,包装为BeanDefinition,返回
本篇文章主要分析第四步中,spring如何根据xml文件中配置的需要扫描的包,扫描受spring注解的Java文件的,更严格的说应该是class文件
@Override
public BeanDefinition parse(Element element, ParserContext parserContext) {
String basePackage = element.getAttribute(BASE_PACKAGE_ATTRIBUTE);
//需要被扫描的包的字符串,这个有可能是多个包,包之间用“;”或者”,”号隔开,然后再被字符串分隔函数进行分隔,分隔为多个包
basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage);
String[] basePackages = StringUtils.tokenizeToStringArray(basePackage,
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
// Actually scan for bean definitions and register them.
ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element);
//根据配置文件中的内容,看是否配置了特殊的过滤器,例如xxx包下面的不扫描什么的,实际上就是includeFilters和excludeFilters,如果没有配置,则为USE_DEFAULT_FILTERS_ATTRIBUTE,
//还有就是解析看有没有用到什么包生成器,以及作用域的代理和类型拦截器(typeFilter)之类的,根据以上配置信息,返回一个scanner,也就是包扫描器,真正的扫描工作就提交给了ClassPathBeanDefinitionScanner类的doScan方法了
Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages);
registerComponents(parserContext.getReaderContext(), beanDefinitions, element);
return null;
}
接下来看包扫描器的扫描方法
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<BeanDefinitionHolder>();
for (String basePackage : basePackages) {
根据包路径,查找此包下候选的所有class,然后返回一个用BeanDefinition描述的set集合,此方法的在下面有所分析
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
//返回此包下面的所有class对象描述的BeanDefinition文件
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
/**
scopeMetadata属性: scopeName=singleton
scopeProxyMode:Name:NO ,ordinal:1
解析文件,
**/
candidate.setScope(scopeMetadata.getScopeName());//设置Bean的作用域
BeanDefinition 本身设置了一些默认属性,例如scope 默认设置为了singleton
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
//返回class的在spring中的bean的名字,根据类名(不包括包),调用Java的Introspector.decapitalize(shortClassName)方法生成bean的名字,生成规则如下:如果是空则直接返回,如果第一个字母是大写,并且第二个字母也是大写,则按照原样返回,否则,把第一个字母更改为小写返回
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
//设置一些默认属性,调用AbstractBeanDefinition类的applyDefaults方法,设置默认属性
/**
setLazyInit(defaults.isLazyInit());
setAutowireMode(defaults.getAutowireMode());
setDependencyCheck(defaults.getDependencyCheck());
setInitMethodName(defaults.getInitMethodName());
setEnforceInitMethod(false);
setDestroyMethodName(defaults.getDestroyMethodName());
setEnforceDestroyMethod(false);
**/
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
//解析一些公共的注解Lazy,Primary,DependOn
}
if (checkCandidate(beanName, candidate)) {
//校验bean的设置是否合法, 校验Bean的兼容性和Bean是否冲突,我们常见的Annotation-specified bean name conflicts with existing异常,就是在这个方法中抛出来的,注意在这个流程中是不有Autowired注解的属性的值进行注入的,注入的流程是在另外的流程中,下一篇文档会专门解析如何注入属性的
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
查找候选组件的方法
1、根据是不是使用了spring的注解
2、是不是在includeFilter过滤器中
3、是不是在excludeFilter过滤器中这些条件
4、@Return 返回符合条件的class
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<BeanDefinition>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + "/" + this.resourcePattern;
//包的classpath路径,例如根据我的xml文件的配置,则packageSearchPath的值是classpath*:com/wtf/demo/spring/beans/**/*.class
Resource[] resources = this.resourcePatternResolver.getResources(packageSearchPath);
//resuources是这个包路径下的所有class,不管class有没有spring的注解,均包含在内
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource);
//返回一个SimpleMetadataReader类型的MetadataReader ,这个类是持有class各种方法以及属性类型的对象
if (isCandidateComponent(metadataReader)) {
//根据配置的excludeFilters和includeFilters判断此class文件是不是候选对象
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setResource(resource);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
else {
........
........
//捕获的一些异常信息
}
return candidates;
}
以上就是对配置了component-scan节点,属性为base-package包下的文件的扫描过程,对于属性有Autowired注解了,然后实际情况是如何注入的,是属于另外的一个流程,将会在下一篇文章中进行分析!