Ubuntu系统下使用Eclipse搭建hadoop2.4运行环境
时间 2014-11-18 23:53:13 CSDN博客
原文 http://blog.csdn.net/zhouzhoujianquan/article/details/41255181
主题 Eclipse Hadoop Ubuntu
使用hadoop进行MapReduce编程的时候,我们都希望使用IDE进行开发,本文主要介绍如何使用Eclipse进行hadoop编程。
如果你的集群还没搭好,可以参考我的前一篇文章 Ubuntu下用hadoop2.4搭建集群(伪分布式)
一、安装Eclipse
方法一:直接在Ubuntu的软件中心进行下载,如下图所示。
方法二:先下载Eclispe压缩文件后,使用命令进行安装,下载地址: http://pan.baidu.com/s/1mgiHFok
sudo tar -zxvf eclipse-dsl-juno-SR1-linux-gtk.tar.gz
![]()
这样Eclipse就安装好了。
二、安装 Hadoop-Eclipse-Plugin
下载 hadoop2x-eclipse-plugin ,将 release 中的 hadoop-eclipse-kepler-plugin-2.2.0.jar (虽然标注的是 2.2.0,但在 2.4.1 下是没问题的,应该在 2.x 版本下都可以,不过有时候会提示有些东西过期,对于学习者来说,我个人觉得暂时可以不考虑这些细节)复制到 Eclipse 安装目录的 plugin 文件夹中,运行 ./eclipse -clean 重启 Eclipse 即可。使用方法一的Eclipse 的默认安装目录为:/usr/lib/eclipse :使用方法二的安装Eclipse的话目录根据自己而定了,我的目录是/usr/local/eclipse。 ./eclipse -clea n命令需要在Eclipse的安装目录下。打开后就可一看到文件系统了。

第一步:选择 Window 菜单下的 Preference ,然后弹出一个窗体,窗体的左侧会多出 Hadoop Map/Reduce 选项,点击此选项,选择 Hadoop 的安装目录(如/usr/local/hadoop)。
 第二步:切换 Map/Reduce 工作目录,选择 Window 菜单下选择 Open Perspective,弹出一个窗体,从中选择 Map/Reduce 选项即可进行切换。
第二步:切换 Map/Reduce 工作目录,选择 Window 菜单下选择 Open Perspective,弹出一个窗体,从中选择 Map/Reduce 选项即可进行切换。
第三步 点击Map/Reduce Location选项卡,点击右边小象图标,打开Hadoop Location配置窗口:

输入Location Name,任意名称即可.配置Map/Reduce Master和DFS Mastrer,Host和Port配置成与core-site.xml的设置一致即可。
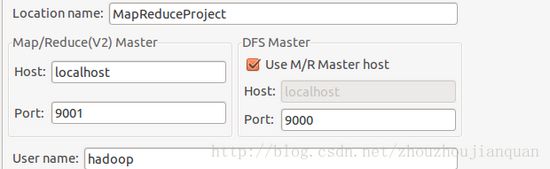
点击"Finish"按钮,关闭窗口。
点击左侧的DFSLocations—>MapReduceProject(上一步配置的location name),如能看到user,表示安装成功
如果出现这个提示这个错误 Error:call from mylinux/127.0.1.1 to localhost:9090 failed on connection exception java.Connection.net.ConnectException拒绝连接。

首先确定 hadoop有没有启动 。我当时也是由于没有启动hadoop,然后折腾了好久才发现了这个问题,希望对大家有所帮助。
具体一些原因可以参考我的一篇博客 在Ubuntu下使用Eclispe连接hadoop时拒绝链接解决方案总结
三、新建WordCount例子
File— > Project,选择Map/Reduce Project,输入项目名称WordCount等。
在WordCount项目里新建class,名称为WordCount,代码如下:
import java.io.IOException;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.GenericOptionsParser;public class WordCount {public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
1、在HDFS上创建目录input
hadoop fs -mkdir input
这是使用命令来创建,我们可以在Eclipse里面右键hadoop(根据个人配置不同这个会有出入)进行创建
2、拷贝本地README.txt到HDFS的input里
hadoop fs -copyFromLocal /usr/local/hadoop/README.txt input
同样我们可以右键input,然后选择Upload file ,使用可视化的形式进行文件上传。
3、点击WordCount.java,右键,点击Run As—>Run Configurations,配置运行参数,即输入和输出文件夹
当然我们也可以在代码里直接写路径,真正搞懂文件系统你会发现方法还有很多,只是需要修改java代码。
下面这个配置是对应了代码里面这个
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();,
hdfs://localhost:9000/user/hadoop/input hdfs://localhost:9000/user/hadoop/output
4、运行完成后,查看运行结果
第一种方法就是在终端里面直接使用命令行进行查看。
hadoop fs -ls output
可以看到有两个输出结果,_SUCCESS和part-r-00000
执行
hadoop fs -cat output/*
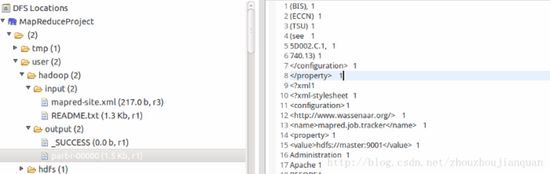
第二种方法就是直接在Eclipse里面查看。首先记得刷新一下文件系统~
展开DFS Locations,如下图所示,双击打开part-r00000查看结果