x264代码剖析(十八):核心算法之滤波
x264代码剖析(十八):核心算法之滤波
H.264/MPEG-4 AVC视频编码标准中,在编解码器反变换量化后,图像会出现方块效应,主要原因是:1)基于块的帧内和帧间预测残差的DCT变换,变换系数的量化过程相对粗糙,因而反量化过程恢复的变换系数有误差,会造成在图像块边界上的视觉不连续;2)运动补偿可能是从不是同一帧的不同位置上内插样点数据复制而来,因为运动补偿块的匹配不可能是绝对准确的,所以就会在复制块的边界上产生数据不连续;3)参考帧中的存在的不连续也被复制到需要补偿的图像块内。
尽管H.264采用较小的4×4变换尺寸可以降低这种不连续现象,但仍需要一个去方块滤波器,以最大程度提高编码性能。在x264中,x264_slice_write()函数中调用了x264_fdec_filter_row()的源代码。x264_fdec_filter_row()对应着x264中的滤波模块。滤波模块主要完成了下面3个方面的功能:
(1)环路滤波(去块效应滤波);
(2)半像素内插;
(3)视频质量指标PSNR和SSIM的计算。
滤波模块对应的函数关系调用图如下:
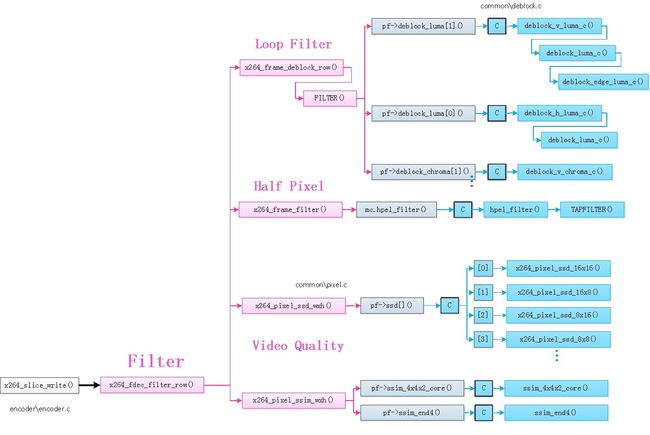
下面对x264中的滤波模块对应的主要函数分别进行分析。
1、x264_slice_write()函数
x264_slice_write()函数中调用了x264_fdec_filter_row()函数,对应于滤波模块。具体的代码分析见《x264代码剖析(九):x264_encoder_encode()函数之x264_slice's'_write()函数》。
2、x264_fdec_filter_row()函数
x264_fdec_filter_row()函数用于对一行宏块进行滤波。该函数的定义位于encoder\encoder.c,x264_fdec_filter_row()完成了三步工作:
(1)环路滤波(去块效应滤波)。通过调用x264_frame_deblock_row()函数实现。
(2)半像素内插。通过调用x264_frame_filter()函数实现。
(3)视频质量SSIM和PSNR的计算。PSNR通过调用x264_pixel_ssd_wxh()函数实现,在这里只计算了SSD;SSIM的计算则是通过x264_pixel_ssim_wxh()函数实现。
对应的代码分析如下:
/******************************************************************/
/******************************************************************/
/*
======Analysed by RuiDong Fang
======Csdn Blog:http://blog.csdn.net/frd2009041510
======Date:2016.04.06
*/
/******************************************************************/
/******************************************************************/
/************====== x264_fdec_filter_row()函数 ======************/
/*
功能:对一行宏块进行滤波-去块效应滤波、半像素插值、SSIM/PSNR计算等
*/
static void x264_fdec_filter_row( x264_t *h, int mb_y, int pass )
{
/* mb_y is the mb to be encoded next, not the mb to be filtered here */
int b_hpel = h->fdec->b_kept_as_ref;
int b_deblock = h->sh.i_disable_deblocking_filter_idc != 1;
int b_end = mb_y == h->i_threadslice_end;
int b_measure_quality = 1;
int min_y = mb_y - (1 << SLICE_MBAFF);
int b_start = min_y == h->i_threadslice_start;
/* Even in interlaced mode, deblocking never modifies more than 4 pixels
* above each MB, as bS=4 doesn't happen for the top of interlaced mbpairs. */
int minpix_y = min_y*16 - 4 * !b_start;
int maxpix_y = mb_y*16 - 4 * !b_end;
b_deblock &= b_hpel || h->param.b_full_recon || h->param.psz_dump_yuv;
if( h->param.b_sliced_threads )
{
switch( pass )
{
/* During encode: only do deblock if asked for */
default:
case 0:
b_deblock &= h->param.b_full_recon;
b_hpel = 0;
break;
/* During post-encode pass: do deblock if not done yet, do hpel for all
* rows except those between slices. */
case 1:
b_deblock &= !h->param.b_full_recon;
b_hpel &= !(b_start && min_y > 0);
b_measure_quality = 0;
break;
/* Final pass: do the rows between slices in sequence. */
case 2:
b_deblock = 0;
b_measure_quality = 0;
break;
}
}
if( mb_y & SLICE_MBAFF )
return;
if( min_y < h->i_threadslice_start )
return;
if( b_deblock )
for( int y = min_y; y < mb_y; y += (1 << SLICE_MBAFF) )
x264_frame_deblock_row( h, y ); ////////////////////////////去块效应滤波
/* FIXME: Prediction requires different borders for interlaced/progressive mc,
* but the actual image data is equivalent. For now, maintain this
* consistency by copying deblocked pixels between planes. */
if( PARAM_INTERLACED && (!h->param.b_sliced_threads || pass == 1) )
for( int p = 0; p < h->fdec->i_plane; p++ )
for( int i = minpix_y>>(CHROMA_V_SHIFT && p); i < maxpix_y>>(CHROMA_V_SHIFT && p); i++ )
memcpy( h->fdec->plane_fld[p] + i*h->fdec->i_stride[p],
h->fdec->plane[p] + i*h->fdec->i_stride[p],
h->mb.i_mb_width*16*sizeof(pixel) );
if( h->fdec->b_kept_as_ref && (!h->param.b_sliced_threads || pass == 1) )
x264_frame_expand_border( h, h->fdec, min_y );
if( b_hpel )
{
int end = mb_y == h->mb.i_mb_height;
/* Can't do hpel until the previous slice is done encoding. */
if( h->param.analyse.i_subpel_refine )
{
x264_frame_filter( h, h->fdec, min_y, end ); ////////////////////////////半像素内插
x264_frame_expand_border_filtered( h, h->fdec, min_y, end );
}
}
if( SLICE_MBAFF && pass == 0 )
for( int i = 0; i < 3; i++ )
{
XCHG( pixel *, h->intra_border_backup[0][i], h->intra_border_backup[3][i] );
XCHG( pixel *, h->intra_border_backup[1][i], h->intra_border_backup[4][i] );
}
if( h->i_thread_frames > 1 && h->fdec->b_kept_as_ref )
x264_frame_cond_broadcast( h->fdec, mb_y*16 + (b_end ? 10000 : -(X264_THREAD_HEIGHT << SLICE_MBAFF)) );
//计算编码的质量
if( b_measure_quality )
{
maxpix_y = X264_MIN( maxpix_y, h->param.i_height );
//如果需要打印输出PSNR
if( h->param.analyse.b_psnr )
{
//实际上是计算SSD
//输出的时候调用x264_psnr()换算SSD为PSNR
/**
* 计算PSNR的过程
*
* MSE = SSD*1/(w*h)
* PSNR= 10*log10(MAX^2/MSE)
*
* 其中MAX指的是图像的灰度级,对于8bit来说就是2^8-1=255
*/
for( int p = 0; p < (CHROMA444 ? 3 : 1); p++ )
h->stat.frame.i_ssd[p] += x264_pixel_ssd_wxh( &h->pixf,
h->fdec->plane[p] + minpix_y * h->fdec->i_stride[p], h->fdec->i_stride[p], //重建帧
h->fenc->plane[p] + minpix_y * h->fenc->i_stride[p], h->fenc->i_stride[p], //编码帧
h->param.i_width, maxpix_y-minpix_y );
if( !CHROMA444 )
{
uint64_t ssd_u, ssd_v;
int v_shift = CHROMA_V_SHIFT;
x264_pixel_ssd_nv12( &h->pixf,
h->fdec->plane[1] + (minpix_y>>v_shift) * h->fdec->i_stride[1], h->fdec->i_stride[1],
h->fenc->plane[1] + (minpix_y>>v_shift) * h->fenc->i_stride[1], h->fenc->i_stride[1],
h->param.i_width>>1, (maxpix_y-minpix_y)>>v_shift, &ssd_u, &ssd_v );
h->stat.frame.i_ssd[1] += ssd_u;
h->stat.frame.i_ssd[2] += ssd_v;
}
}
//如果需要打印输出SSIM
if( h->param.analyse.b_ssim )
{
int ssim_cnt;
x264_emms();
/* offset by 2 pixels to avoid alignment of ssim blocks with dct blocks,
* and overlap by 4 */
minpix_y += b_start ? 2 : -6;
h->stat.frame.f_ssim +=
x264_pixel_ssim_wxh( &h->pixf,
h->fdec->plane[0] + 2+minpix_y*h->fdec->i_stride[0], h->fdec->i_stride[0], //重建帧
h->fenc->plane[0] + 2+minpix_y*h->fenc->i_stride[0], h->fenc->i_stride[0], //编码帧
h->param.i_width-2, maxpix_y-minpix_y, h->scratch_buffer, &ssim_cnt );
h->stat.frame.i_ssim_cnt += ssim_cnt;
}
}
}
3、x264_frame_deblock_row()函数
x264_frame_deblock_row()用于进行环路滤波(去块效应滤波)。该函数的定义位于common\deblock.c,x264_frame_deblock_row()中有一个很长的宏定义“FILTER()”定义了函数调用的方式。FILTER( intra, dir, edge, qp, chroma_qp )中:
(1)“intra”指定了是普通滤波(Bs=1,2,3)还是强滤波(Bs=4);
(2)“dir”指定了滤波器的方向。0为水平滤波器(垂直边界),1为垂直滤波器(水平边界);
(3)“edge”指定了边界的位置。“0”,“1”,“2”,“3”分别代表了水平(或者垂直)的4条边界。
对应的代码分析如下:
/************====== x264_frame_deblock_row()函数 ======************/
/*
功能:去块效应滤波
*/
void x264_frame_deblock_row( x264_t *h, int mb_y )
{
int b_interlaced = SLICE_MBAFF;
int a = h->sh.i_alpha_c0_offset - QP_BD_OFFSET;
int b = h->sh.i_beta_offset - QP_BD_OFFSET;
int qp_thresh = 15 - X264_MIN( a, b ) - X264_MAX( 0, h->pps->i_chroma_qp_index_offset );
int stridey = h->fdec->i_stride[0];
int strideuv = h->fdec->i_stride[1];
int chroma444 = CHROMA444;
int chroma_height = 16 >> CHROMA_V_SHIFT;
intptr_t uvdiff = chroma444 ? h->fdec->plane[2] - h->fdec->plane[1] : 1;
for( int mb_x = 0; mb_x < h->mb.i_mb_width; mb_x += (~b_interlaced | mb_y)&1, mb_y ^= b_interlaced )
{
x264_prefetch_fenc( h, h->fdec, mb_x, mb_y );
x264_macroblock_cache_load_neighbours_deblock( h, mb_x, mb_y );
int mb_xy = h->mb.i_mb_xy;
int transform_8x8 = h->mb.mb_transform_size[mb_xy];
int intra_cur = IS_INTRA( h->mb.type[mb_xy] );
uint8_t (*bs)[8][4] = h->deblock_strength[mb_y&1][h->param.b_sliced_threads?mb_xy:mb_x];
//找到像素数据(宏块的大小是16x16)
pixel *pixy = h->fdec->plane[0] + 16*mb_y*stridey + 16*mb_x;
pixel *pixuv = h->fdec->plane[1] + chroma_height*mb_y*strideuv + 16*mb_x;
if( mb_y & MB_INTERLACED )
{
pixy -= 15*stridey;
pixuv -= (chroma_height-1)*strideuv;
}
int stride2y = stridey << MB_INTERLACED;
int stride2uv = strideuv << MB_INTERLACED;
//QP,用于计算环路滤波的门限值alpha和beta
int qp = h->mb.qp[mb_xy];
int qpc = h->chroma_qp_table[qp];
int first_edge_only = (h->mb.partition[mb_xy] == D_16x16 && !h->mb.cbp[mb_xy] && !intra_cur) || qp <= qp_thresh;
/*
* 滤波顺序如下所示(大方框代表16x16块)
*
* +--4-+--4-+--4-+--4-+
* 0 1 2 3 |
* +--5-+--5-+--5-+--5-+
* 0 1 2 3 |
* +--6-+--6-+--6-+--6-+
* 0 1 2 3 |
* +--7-+--7-+--7-+--7-+
* 0 1 2 3 |
* +----+----+----+----+
*
*/
//一个比较长的宏,用于进行环路滤波
//根据不同的情况传递不同的参数
//几个参数的含义:
//intra:
//为“_intra”的时候:
//其中的“deblock_edge##intra()”展开为函数deblock_edge_intra()
//其中的“h->loopf.deblock_luma##intra[dir]”展开为强滤波汇编函数h->loopf.deblock_luma_intra[dir]()
//为“”(空),其中的“deblock_edge##intra()”展开为函数deblock_edge()
//其中的“h->loopf.deblock_luma##intra[dir]”展开为普通滤波汇编函数h->loopf.deblock_luma[dir]()
//dir:
//决定了滤波的方向:0为水平滤波器(垂直边界),1为垂直滤波器(水平边界)
#define FILTER( intra, dir, edge, qp, chroma_qp )\
do\
{\
if( !(edge & 1) || !transform_8x8 )\
{\
deblock_edge##intra( h, pixy + 4*edge*(dir?stride2y:1),\
stride2y, bs[dir][edge], qp, a, b, 0,\
h->loopf.deblock_luma##intra[dir] );\
if( CHROMA_FORMAT == CHROMA_444 )\
{\
deblock_edge##intra( h, pixuv + 4*edge*(dir?stride2uv:1),\
stride2uv, bs[dir][edge], chroma_qp, a, b, 0,\
h->loopf.deblock_luma##intra[dir] );\
deblock_edge##intra( h, pixuv + uvdiff + 4*edge*(dir?stride2uv:1),\
stride2uv, bs[dir][edge], chroma_qp, a, b, 0,\
h->loopf.deblock_luma##intra[dir] );\
}\
else if( CHROMA_FORMAT == CHROMA_420 && !(edge & 1) )\
{\
deblock_edge##intra( h, pixuv + edge*(dir?2*stride2uv:4),\
stride2uv, bs[dir][edge], chroma_qp, a, b, 1,\
h->loopf.deblock_chroma##intra[dir] );\
}\
}\
if( CHROMA_FORMAT == CHROMA_422 && (dir || !(edge & 1)) )\
{\
deblock_edge##intra( h, pixuv + edge*(dir?4*stride2uv:4),\
stride2uv, bs[dir][edge], chroma_qp, a, b, 1,\
h->loopf.deblock_chroma##intra[dir] );\
}\
} while(0)
if( h->mb.i_neighbour & MB_LEFT )
{
if( b_interlaced && h->mb.field[h->mb.i_mb_left_xy[0]] != MB_INTERLACED )
{
int luma_qp[2];
int chroma_qp[2];
int left_qp[2];
x264_deblock_inter_t luma_deblock = h->loopf.deblock_luma_mbaff;
x264_deblock_inter_t chroma_deblock = h->loopf.deblock_chroma_mbaff;
x264_deblock_intra_t luma_intra_deblock = h->loopf.deblock_luma_intra_mbaff;
x264_deblock_intra_t chroma_intra_deblock = h->loopf.deblock_chroma_intra_mbaff;
int c = chroma444 ? 0 : 1;
left_qp[0] = h->mb.qp[h->mb.i_mb_left_xy[0]];
luma_qp[0] = (qp + left_qp[0] + 1) >> 1;
chroma_qp[0] = (qpc + h->chroma_qp_table[left_qp[0]] + 1) >> 1;
if( intra_cur || IS_INTRA( h->mb.type[h->mb.i_mb_left_xy[0]] ) )
{
deblock_edge_intra( h, pixy, 2*stridey, bs[0][0], luma_qp[0], a, b, 0, luma_intra_deblock );
deblock_edge_intra( h, pixuv, 2*strideuv, bs[0][0], chroma_qp[0], a, b, c, chroma_intra_deblock );
if( chroma444 )
deblock_edge_intra( h, pixuv + uvdiff, 2*strideuv, bs[0][0], chroma_qp[0], a, b, c, chroma_intra_deblock );
}
else
{
deblock_edge( h, pixy, 2*stridey, bs[0][0], luma_qp[0], a, b, 0, luma_deblock );
deblock_edge( h, pixuv, 2*strideuv, bs[0][0], chroma_qp[0], a, b, c, chroma_deblock );
if( chroma444 )
deblock_edge( h, pixuv + uvdiff, 2*strideuv, bs[0][0], chroma_qp[0], a, b, c, chroma_deblock );
}
int offy = MB_INTERLACED ? 4 : 0;
int offuv = MB_INTERLACED ? 4-CHROMA_V_SHIFT : 0;
left_qp[1] = h->mb.qp[h->mb.i_mb_left_xy[1]];
luma_qp[1] = (qp + left_qp[1] + 1) >> 1;
chroma_qp[1] = (qpc + h->chroma_qp_table[left_qp[1]] + 1) >> 1;
if( intra_cur || IS_INTRA( h->mb.type[h->mb.i_mb_left_xy[1]] ) )
{
deblock_edge_intra( h, pixy + (stridey<<offy), 2*stridey, bs[0][4], luma_qp[1], a, b, 0, luma_intra_deblock );
deblock_edge_intra( h, pixuv + (strideuv<<offuv), 2*strideuv, bs[0][4], chroma_qp[1], a, b, c, chroma_intra_deblock );
if( chroma444 )
deblock_edge_intra( h, pixuv + uvdiff + (strideuv<<offuv), 2*strideuv, bs[0][4], chroma_qp[1], a, b, c, chroma_intra_deblock );
}
else
{
deblock_edge( h, pixy + (stridey<<offy), 2*stridey, bs[0][4], luma_qp[1], a, b, 0, luma_deblock );
deblock_edge( h, pixuv + (strideuv<<offuv), 2*strideuv, bs[0][4], chroma_qp[1], a, b, c, chroma_deblock );
if( chroma444 )
deblock_edge( h, pixuv + uvdiff + (strideuv<<offuv), 2*strideuv, bs[0][4], chroma_qp[1], a, b, c, chroma_deblock );
}
}
else
{
//左边宏块的qp
int qpl = h->mb.qp[h->mb.i_mb_xy-1];
int qp_left = (qp + qpl + 1) >> 1;
int qpc_left = (qpc + h->chroma_qp_table[qpl] + 1) >> 1;
//Intra宏块左边宏块的qp
int intra_left = IS_INTRA( h->mb.type[h->mb.i_mb_xy-1] );
int intra_deblock = intra_cur || intra_left;
/* Any MB that was coded, or that analysis decided to skip, has quality commensurate with its QP.
* But if deblocking affects neighboring MBs that were force-skipped, blur might accumulate there.
* So reset their effective QP to max, to indicate that lack of guarantee. */
if( h->fdec->mb_info && M32( bs[0][0] ) )
{
#define RESET_EFFECTIVE_QP(xy) h->fdec->effective_qp[xy] |= 0xff * !!(h->fdec->mb_info[xy] & X264_MBINFO_CONSTANT);
RESET_EFFECTIVE_QP(mb_xy);
RESET_EFFECTIVE_QP(h->mb.i_mb_left_xy[0]);
}
if( intra_deblock )
//【0】强滤波,水平滤波器(垂直边界)
FILTER( _intra, 0, 0, qp_left, qpc_left );
else
//【0】普通滤波,水平滤波器(垂直边界)
FILTER( , 0, 0, qp_left, qpc_left );
}
}
if( !first_edge_only )
{
//普通滤波,水平滤波器(垂直边界)
FILTER( , 0, 1, qp, qpc );//【1】
FILTER( , 0, 2, qp, qpc );//【2】
FILTER( , 0, 3, qp, qpc );//【3】
}
if( h->mb.i_neighbour & MB_TOP )
{
if( b_interlaced && !(mb_y&1) && !MB_INTERLACED && h->mb.field[h->mb.i_mb_top_xy] )
{
int mbn_xy = mb_xy - 2 * h->mb.i_mb_stride;
for( int j = 0; j < 2; j++, mbn_xy += h->mb.i_mb_stride )
{
int qpt = h->mb.qp[mbn_xy];
int qp_top = (qp + qpt + 1) >> 1;
int qpc_top = (qpc + h->chroma_qp_table[qpt] + 1) >> 1;
int intra_top = IS_INTRA( h->mb.type[mbn_xy] );
if( intra_cur || intra_top )
M32( bs[1][4*j] ) = 0x03030303;
// deblock the first horizontal edge of the even rows, then the first horizontal edge of the odd rows
deblock_edge( h, pixy + j*stridey, 2* stridey, bs[1][4*j], qp_top, a, b, 0, h->loopf.deblock_luma[1] );
if( chroma444 )
{
deblock_edge( h, pixuv + j*strideuv, 2*strideuv, bs[1][4*j], qpc_top, a, b, 0, h->loopf.deblock_luma[1] );
deblock_edge( h, pixuv + uvdiff + j*strideuv, 2*strideuv, bs[1][4*j], qpc_top, a, b, 0, h->loopf.deblock_luma[1] );
}
else
deblock_edge( h, pixuv + j*strideuv, 2*strideuv, bs[1][4*j], qpc_top, a, b, 1, h->loopf.deblock_chroma[1] );
}
}
else
{
int qpt = h->mb.qp[h->mb.i_mb_top_xy];
int qp_top = (qp + qpt + 1) >> 1;
int qpc_top = (qpc + h->chroma_qp_table[qpt] + 1) >> 1;
int intra_top = IS_INTRA( h->mb.type[h->mb.i_mb_top_xy] );
int intra_deblock = intra_cur || intra_top;
/* This edge has been modified, reset effective qp to max. */
if( h->fdec->mb_info && M32( bs[1][0] ) )
{
RESET_EFFECTIVE_QP(mb_xy);
RESET_EFFECTIVE_QP(h->mb.i_mb_top_xy);
}
if( (!b_interlaced || (!MB_INTERLACED && !h->mb.field[h->mb.i_mb_top_xy])) && intra_deblock )
{
FILTER( _intra, 1, 0, qp_top, qpc_top );//【4】普通滤波,垂直滤波器(水平边界)
}
else
{
if( intra_deblock )
M32( bs[1][0] ) = 0x03030303;
FILTER( , 1, 0, qp_top, qpc_top );//【4】普通滤波,垂直滤波器(水平边界)
}
}
}
if( !first_edge_only )
{
//普通滤波,垂直滤波器(水平边界)
FILTER( , 1, 1, qp, qpc );//【5】
FILTER( , 1, 2, qp, qpc );//【6】
FILTER( , 1, 3, qp, qpc );//【7】
}
#undef FILTER
}
}
4、x264_frame_filter()函数
x264_frame_filter()用于完成半像素内插的工作。该函数的定义位于common\mc.c,x264_frame_filter()调用了汇编函数h->mc.hpel_filter()完成了半像素内插的工作。经过汇编半像素内插函数处理之后,得到的水平半像素内差点存储在x264_frame_t的filtered[][1]中,垂直半像素内差点存储在x264_frame_t的filtered[][2]中,对角线半像素内差点存储在x264_frame_t的filtered[][3]中(整像素点存储在x264_frame_t的filtered[][0]中)。
对应的代码分析如下:
/************====== x264_frame_filter()函数 ======************/
/*
功能:半像素内插
*/
void x264_frame_filter( x264_t *h, x264_frame_t *frame, int mb_y, int b_end )
{
const int b_interlaced = PARAM_INTERLACED;
int start = mb_y*16 - 8; // buffer = 4 for deblock + 3 for 6tap, rounded to 8
int height = (b_end ? frame->i_lines[0] + 16*PARAM_INTERLACED : (mb_y+b_interlaced)*16) + 8;
if( mb_y & b_interlaced )
return;
for( int p = 0; p < (CHROMA444 ? 3 : 1); p++ )
{
int stride = frame->i_stride[p];
const int width = frame->i_width[p];
int offs = start*stride - 8; // buffer = 3 for 6tap, aligned to 8 for simd
//半像素内插
if( !b_interlaced || h->mb.b_adaptive_mbaff )
h->mc.hpel_filter(
frame->filtered[p][1] + offs,//水平半像素内插
frame->filtered[p][2] + offs,//垂直半像素内插
frame->filtered[p][3] + offs,//中间半像素内插
frame->plane[p] + offs,
stride, width + 16, height - start,
h->scratch_buffer );
if( b_interlaced )
{
/* MC must happen between pixels in the same field. */
stride = frame->i_stride[p] << 1;
start = (mb_y*16 >> 1) - 8;
int height_fld = ((b_end ? frame->i_lines[p] : mb_y*16) >> 1) + 8;
offs = start*stride - 8;
for( int i = 0; i < 2; i++, offs += frame->i_stride[p] )
{
h->mc.hpel_filter(
frame->filtered_fld[p][1] + offs,
frame->filtered_fld[p][2] + offs,
frame->filtered_fld[p][3] + offs,
frame->plane_fld[p] + offs,
stride, width + 16, height_fld - start,
h->scratch_buffer );
}
}
}
/* generate integral image:
* frame->integral contains 2 planes. in the upper plane, each element is
* the sum of an 8x8 pixel region with top-left corner on that point.
* in the lower plane, 4x4 sums (needed only with --partitions p4x4). */
if( frame->integral )
{
int stride = frame->i_stride[0];
if( start < 0 )
{
memset( frame->integral - PADV * stride - PADH, 0, stride * sizeof(uint16_t) );
start = -PADV;
}
if( b_end )
height += PADV-9;
for( int y = start; y < height; y++ )
{
pixel *pix = frame->plane[0] + y * stride - PADH;
uint16_t *sum8 = frame->integral + (y+1) * stride - PADH;
uint16_t *sum4;
if( h->frames.b_have_sub8x8_esa )
{
h->mc.integral_init4h( sum8, pix, stride );
sum8 -= 8*stride;
sum4 = sum8 + stride * (frame->i_lines[0] + PADV*2);
if( y >= 8-PADV )
h->mc.integral_init4v( sum8, sum4, stride );
}
else
{
h->mc.integral_init8h( sum8, pix, stride );
if( y >= 8-PADV )
h->mc.integral_init8v( sum8-8*stride, stride );
}
}
}
}
5、x264_pixel_ssd_wxh()函数
x264_pixel_ssd_wxh()用于计算SSD(用于以后计算PSNR)。该函数的定义位于common\pixel.c,x264_pixel_ssd_wxh()在计算大部分块的SSD的时候是以16x16的块为单位;当宽度不是16的整数倍的时候,在左侧边缘处不足16像素的地方使用了8x16的块进行计算;当高度不是16的整数倍的时候,在下方不足16像素的地方使用了8x8的块进行计算;当宽高不是8的整数倍的时候,则再单独计算。
对应的代码分析如下:
/************====== x264_pixel_ssd_wxh()函数 ======************/
/*
* 功能:计算SSD(可用于计算PSNR)
* pix1: 受损数据
* pix2: 原始数据
* i_width: 图像宽
* i_height: 图像高
*/
uint64_t x264_pixel_ssd_wxh( x264_pixel_function_t *pf, pixel *pix1, intptr_t i_pix1,
pixel *pix2, intptr_t i_pix2, int i_width, int i_height )
{
uint64_t i_ssd = 0;//计算结果都累加到i_ssd变量上
int y;
int align = !(((intptr_t)pix1 | (intptr_t)pix2 | i_pix1 | i_pix2) & 15);
#define SSD(size) i_ssd += pf->ssd[size]( pix1 + y*i_pix1 + x, i_pix1, \
pix2 + y*i_pix2 + x, i_pix2 );
/*
* SSD计算过程:
* 从左上角开始,绝大部分块使用16x16的SSD计算
* 右边边界部分可能用16x8的SSD计算
* 下边边界可能用8x8的SSD计算
* 注意:这么做主要是出于汇编优化的考虑
*
* +----+----+----+----+----+----+----+----+----+----+-+
* | | | |
* + + + +
* | | | |
* + 16x16 + 16x16 + 8x16 +
* | | | |
* + + + +
* | | | |
* +----+----+----+----+----+----+----+----+----+----+-+
* | |
* + 8x8 +
* | |
* +----+----+
* + +
*/
for( y = 0; y < i_height-15; y += 16 )
{
int x = 0;
if( align )//大部分使用16x16的SSD
for( ; x < i_width-15; x += 16 )
SSD(PIXEL_16x16);
for( ; x < i_width-7; x += 8 )//右边边缘部分可能用8x16的SSD
SSD(PIXEL_8x16);
}
if( y < i_height-7 )//下边边缘部分可能用到8x8的SSD
for( int x = 0; x < i_width-7; x += 8 )
SSD(PIXEL_8x8);
#undef SSD
#define SSD1 { int d = pix1[y*i_pix1+x] - pix2[y*i_pix2+x]; i_ssd += d*d; }
if( i_width & 7 )//如果像素不是16/8的整数倍,边界上的点需要单独算
{
for( y = 0; y < (i_height & ~7); y++ )
for( int x = i_width & ~7; x < i_width; x++ )
SSD1;
}
if( i_height & 7 )
{
for( y = i_height & ~7; y < i_height; y++ )
for( int x = 0; x < i_width; x++ )
SSD1;
}
#undef SSD1
return i_ssd;
}
6、x264_pixel_ssim_wxh()函数
x264_pixel_ssim_wxh()用于计算SSIM。该函数的定义位于common\pixel.c,x264_pixel_ssim_wxh()中是按照4x4的块对像素进行处理的。使用sum1[]保存上一行块的“信息”,sum0[]保存当前一行块的“信息”。“信息”包含4个元素:
s1:原始像素之和;
s2:受损像素之和;
ss:原始像素平方之和+受损像素平方之和;
s12:原始像素*受损像素的值的和。
对应的代码分析如下:
/************====== x264_pixel_ssd_wxh()函数 ======************/
/*
* 功能:计算SSIM
* pix1: 受损数据
* pix2: 原始数据
* i_width: 图像宽
* i_height: 图像高
*/
float x264_pixel_ssim_wxh( x264_pixel_function_t *pf,
pixel *pix1, intptr_t stride1,
pixel *pix2, intptr_t stride2,
int width, int height, void *buf, int *cnt )
{
/*
* SSIM公式
* SSIM = ((2*ux*uy+C1)(2*σxy+C2))/((ux^2+uy^2+C1)(σx^2+σy^2+C2))
*
* 其中
* ux=E(x)
* uy=E(y)
* σxy=cov(x,y)=E(XY)-ux*uy
* σx^2=E(x^2)-E(x)^2
*
*/
int z = 0;
float ssim = 0.0;
//这是数组指针,注意和指针数组的区别
//数组指针就是指向数组的指针
int (*sum0)[4] = buf;
/*
* sum0是一个数组指针,其中存储了一个4元素数组的地址
* 换句话说,sum0[]中每一个元素对应一个4x4块的信息(该信息包含4个元素)。
*
* 4个元素中:
* [0]原始像素之和
* [1]受损像素之和
* [2]原始像素平方之和+受损像素平方之和
* [3]原始像素*受损像素的值的和
*
*/
int (*sum1)[4] = sum0 + (width >> 2) + 3;
//除以4,编程以“4x4块”为单位
width >>= 2;
height >>= 2;
//以8*8的块为单位计算SSIM值。然后以4个像素为step滑动窗口
for( int y = 1; y < height; y++ )
{
//下面这个循环,只有在第一次执行的时候执行2次,处理第1行和第2行的块
//后面的都只会执行一次
for( ; z <= y; z++ )
{
//执行完XCHG()之后,sum1[]存储上1行块的值(在上面),而sum0[]等待ssim_4x4x2_core()计算当前行的值(在下面)
XCHG( void*, sum0, sum1 );
//获取4x4块的信息(这里并没有代入公式计算SSIM结果)
//结果存储在sum0[]中。从左到右每个4x4的块依次存储在sum0[0],sum0[1],sum0[2]...
//每次x前进2个块
/*
* ssim_4x4x2_core():计算2个4x4块
* +----+----+
* | | |
* +----+----+
*/
for( int x = 0; x < width; x+=2 )
pf->ssim_4x4x2_core( &pix1[4*(x+z*stride1)], stride1, &pix2[4*(x+z*stride2)], stride2, &sum0[x] );
}
//x每次增加4,前进4个块
//以8*8的块为单位计算
/*
* sum1[]为上一行4x4块信息,sum0[]为当前行4x4块信息
* 示例(line以4x4块为单位)
* 第1次运行
* +----+----+----+----+
* 1line | sum1[]
* +----+----+----+----+
* 2line | sum0[]
* +----+----+----+----+
*
* 第2次运行
* +
* 1line |
* +----+----+----+----+
* 2line | sum1[]
* +----+----+----+----+
* 3line | sum0[]
* +----+----+----+----+
*/
for( int x = 0; x < width-1; x += 4 )
ssim += pf->ssim_end4( sum0+x, sum1+x, X264_MIN(4,width-x-1) );
}
*cnt = (height-1) * (width-1);
return ssim;
}
![]() 滤波模块的主要代码分析就到这儿,其实中间有很多实用且有效的函数块,待后面用到时更新。
滤波模块的主要代码分析就到这儿,其实中间有很多实用且有效的函数块,待后面用到时更新。