图解机器学习总结——1、基本概念
序言:近期主要帮同事讲解《图解机器学习》,刚拿到这本书觉得内容相比较平常使用的机器学习算法,很多地方讲解得比较奇怪,在认真的读完后,觉得还是有很多重要的东西,因此读了书就想把知识点整理出来,加上一些自己对各种算法的认识,因此这个系列里面有一些个人的理解,若有不对的地方,还请不吝指出,谢谢。
一、机器学习的概念
对于机器学习概念的理解,机器学习主要是从大量的数据中找到数据中潜在的模式或者规律,并利用这样的模式或者规律作用于一些未知的数据。根据数据形式的不同,可以将机器学习分为:
- 监督学习。
- 无监督学习。
- 强化学习。
1.1、监督学习
对于监督学习的数据形式为 (x(i),y(i)),i=1⋯n ,需要学习的是从特征 x(i) 到标签 y(i) 的映射: f(x(i)) 。
典型的任务包括:预测数值型数据的回归、预测分类标签的分类、预测顺序的排序等。
1.2、无监督学习
对于无监督学习的数据形式为 (x(i)),i=1⋯n ,需要学习的是特征与特征之间的一种关系。
典型的任务包括:聚类、异常检测等。
1.3、强化学习
强化学习的数据形式与监督学习一致,但是在学习的过程中,不要通过标签评价学习的效果,而是通过自己对预测的结果进行评估。强化学习在机器人的自动控制、计算机游戏中的人工智能等方面有着广泛的应用。
二、机器学习中的典型任务
在机器学习中,典型的任务包括
- 回归
- 分类
- 异常检测
- 聚类
- 降维
2.1、回归
回归,指的是把实函数在样本点附近加以近似的有监督的函数近似问题。简单来讲,对于训练数据集 (x(i),y(i)),i=1⋯n ,其中, y(i) 为实数,通过学习得到一个函数:
常用的回归算法有:线性回归,Lasso,岭回归,回归树等。
2.2、分类
分类,指的是对于指定的模式进行识别的有监督的模式识别问题。简单来讲,对于训练数据集 (x(i),y(i)),i=1⋯n ,其中, y(i) 为类别型数据,如 {−1,1} ,通过学习得到一个函数:
常用的分类算有有:SVM,Logistic回归,BP神经网络,朴素贝叶斯等。
2.3、异常检测
异常检测,指的是寻找样本集 (x(i)),i=1⋯n 中所包含的异常数据的问题。
通常对于这类的无监督问题,采用密度估计的方法,把靠近密度中心的数据作为正常的数据,把偏离密度中心的数据作为异常的数据。
2.4、聚类
聚类也是一类无监督学习问题,是将样本划分到不同的类别中。
常用的聚类算法有:K-Means,谱聚类等。
2.5、降维
降维,是指从高维数据中提取出关键的信息,将其转换为易于计算的低维问题,进而对其进行求解。降维可以分为无监督的降维和有监督的降维。
常用的降维算法有:PCA,SVD等。
三、机器学习的方法
在机器学习中,对于分类问题,通常可以分为两种不同的学习的方法,即:
- 判别式分类
- 生成式分类
3.1、判别式分类
判别式分类是指利用训练数据集 (x(i),y(i)),i=1⋯n ,求得分类类别 y 的条件概率 p(y∣x) 到达最大的类别:
这种直接利用后验概率 p(y∣x) 进行学习的过程,称为判别式分类。
3.2、生成式分类
由贝叶斯定理可知:
通过预测数据生成概率 p(x,y) 进行模式识别的分类方法称为生成式分类。
四、机器学习中的各种模型
1、线性模型
线性模型是一种较为简单的模型,其基本模型如下:
在实际的使用中,通常很少直接使用这样的线性模型,通常将其进行推广,推广为基于参数的线性模型:
其中 ϕj(x) 是基函数向量 Φ(x)=(ϕ1(x),ϕ2(x),⋯,ϕn(x))T 的第 j 个因子。
2、核模型
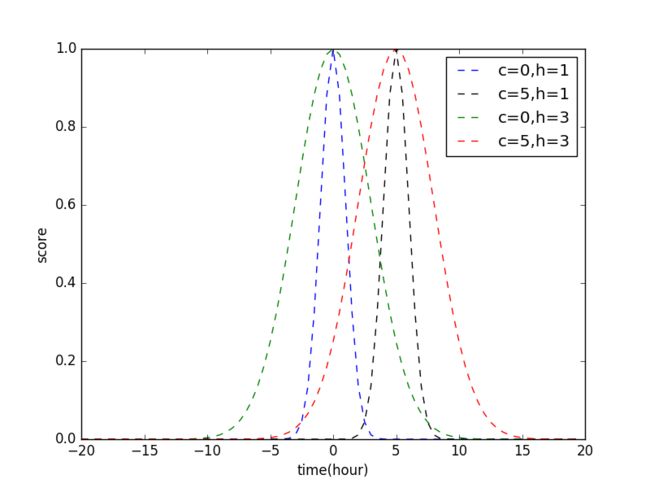
核模型是针对基函数向量的设计,通常使用二元函数 K(⋅,⋅) 表示核函数,使用较多的是高斯核函数:
其中, h 和 c 分别对应于高斯核函数的带宽与均值。
''' Date:20160409 @author: zhaozhiyong '''
import matplotlib.pyplot as plt
import math
def cal_Gaussian(x, c=0, h=1):
molecule = (x - c) * (x - c)
denominator = 2 * h * h
return math.exp(-molecule / denominator)
x = []
for i in xrange(-40,40):
x.append(i * 0.5);
score_1 = []
score_2 = []
score_3 = []
score_4 = []
for i in x:
score_1.append(cal_Gaussian(i,0,1))
score_2.append(cal_Gaussian(i,5,1))
score_3.append(cal_Gaussian(i,0,3))
score_4.append(cal_Gaussian(i,5,3))
plt.plot(x, score_1, 'b--', label="c=0,h=1")
plt.plot(x, score_2, 'k--', label="c=5,h=1")
plt.plot(x, score_3, 'g--', label="c=0,h=3")
plt.plot(x, score_4, 'r--', label="c=5,h=3")
plt.legend(loc="upper right")
plt.xlabel(r"time(hour)")
plt.ylabel("score")
plt.show()
3、层级模型
与参数相关的非参数模型,称为非线性模型。在非线性模型中,有一类是层级模型。层级模型中典型的是神经网络模型。