【java虚拟机系列】java虚拟机系列之JVM总述
我们知道java之所以能够快速崛起一个重要的原因就是其跨平台性,而跨平台就是通过java虚拟机来完成的,java虚拟机属于java底层的知识范畴,即使你不了解也不会影响绝大部分人从事的java应用层的开发,但是如果你了解JVM的底层知识,你就能更加了解java这门语言的本质,从而对你应用层的java程序的性能优化起到很大的帮助(主要是指内存方面的)另外像一些要求比较高的公司可能在面试的时候会问一些JVM相关的知识,如博主在阿里巴巴内推一面的时候就被问到过JVM的内存区域模型(要知道博主目前可是大三学生啊,就被问道了JVM的知识,而且面试官告诉我这些属于java的基础知识![]() ),这也说明了JVM知识的重要性。
),这也说明了JVM知识的重要性。
本博客将从JVM的整个体系方面来总的叙述一下JVM,具体各部分的详细讲解后续将通过【java虚拟机系列】博客的方式不断补充完善,敬请期待。
一java类型的生命周期:
java中的一个类的生命周期可以概括为三个阶段:开始阶段,使用阶段,结束阶段:
开始阶段:开始阶段包括三个步骤:
装载:把二进制形式的java类型读入jvm中。
1)通过该类型的完全限定名,产生一个代表该类型的二进制数据流;
2)解析这个二进制数据流为方法区内的内部数据结构;
3)创建一个表示该类型的java.lang.Class类的实例;
连接:把已读入的类型数据合并到虚拟机的运行时状态中。
1)验证:确保java类型数据格式正确并且适用于jvm使用;
2)准备:为该类型分配内存;
3)解析:把常量池中的符号引用转换为直接引用;
初始化:每个类和接口在首次主动使用时初始化。为类变量赋予正确的初始值;
1)如果类存在直接超类,且直接超类没有被初始化,先初始化直接超类;
2)如果类存在初始化方法,就执行此方法;
只有六种活动被认为是主动使用:
1)、创建类的新实例
2)、调用类中声明的静态方法
3)、操作类或者接口中声明的非常量静态字段
4)、调用Java API中特定的反射方法
5)、初始化一个类的子类
6)、指定一个类作为jvm启动时的初始化类
使用阶段:实例化
实例化途径
明确实例化一个类的四种途径:
1)、new操作符;
2)、调用Class或者Java.lang.reflect.Constructor对象的newInstance()方法;
3)、调用任何现有对象的Clone()方法;
4)、通过java.io.ObjectInputStream类的getObject()方法反序列化;
隐含实例化的几种途径:
1)、保存命令行参数的String对象;
2)、和类装载相关,jvm装载的每一个类型,会暗中实例化一个Class对象来代表这个类型;
3)、和类装载相关,当jvm装载了在常量池中包含CONSTANT_String_info入口类的时候,会创建新的String对象的实例来表示这些常量字符串;
4)、通过执行包含字符串连接操作符的表达式产生对象;
实例化步骤
1)、在堆中为保存对象的实例变量分配内存;
2)、为实例变量初始化为默认的初始值;
3)、为实例变量赋正确的初始值,有三种技术完成赋值:
a)、如果对象是clone() 创建的,jvm把原实例变量中的值拷贝到新对象中;
b)、如果是通过ObjectInputStream类的readObject()调用反序列化的,jvm从输入流中读取的值来初始化实例变量;
c)、jvm调用对象的实例化方法把对象的实例变量初始化为正确的初始值;
垃圾收集和对象终结
jvm实现必须具有某种自动堆存储管理策略,大部分是使用垃圾收集器。如果类声明了 void finalize()方法,垃圾收集器在释放实例内存前会执行这个方法。
垃圾收集器自动调用的finalize()方法抛出的任何异常都将被忽略。
结束阶段:
从jvm中卸载类型
很多情况,jvm中类的生命周期和对象的生命周期很相似。jvm如何判断动态装载的类型是否仍然被程序使用,其判断方式和判断对象是否仍然被使用很相似。
如果程序不再引用某类型,那么类型就是不可触及的,就可以被卸载。
使用启动类装载器装载的类型永远都是可触及的,所以永远不会被卸载。只有使用用户定义的类装载器装载的类型才会变成不可触及,才会被卸载。
二java程序的执行过程:
从这个框图很容易大体上了解java程序工作原理。首先,你写好java代码,保存到硬盘当中。然后你在命令行中输入
javac ClassName.java
此时,你的java代码就被编译成字节码(.class).如果你是在Eclipse IDE或者其他开发工具中,你保存代码的时候,开发工具已经帮你完成了上述的编译工作,因此你可以在对应的目录下看到class文件。此时的class文件依然是保存在硬盘中,因此,当你在命令行中运行
java ClassName
就完成了上面红色方框中的工作。JRE的来加载器从硬盘中读取class文件,载入到系统分配给JVM的内存区域--运行数据区(Runtime Data Areas). 然后执行引擎解释或者编译类文件,转化成特定CPU的机器码,CPU执行机器码,至此完成整个过程。
因此从上述过程中可以看到java程序执行的过程最最重要的过程就是上述红色方框中的内容,而这部分内容就属于java体系结构的内容。下面我们来看一下JVM体系结构。
二JVM体系结构:我们先l来看一张图:

下面我们来逐个介绍:
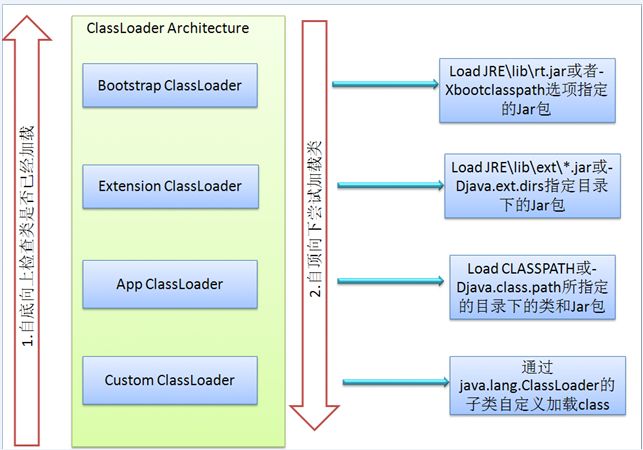
1类装载器子系统
类装载器子系统与java对象的生命周期息息相关,关于java对象的生命周期请参考上述相关内容,类装载器子系统是一个层级结构:用图示表示如下:
--Bootstrap class loader:
当运行java虚拟机时,这个类加载器被创建,它加载一些基本的java API,包括Object这个类。需要注意的是,这个类加载器不是用java语言写的,而是用C/C++写的。
--Extension class loader:
这个加载器加载出了基本API之外的一些拓展类,包括一些与安全性能相关的类。
--System Class Loader:
它加载应用程序中的类,也就是在你的classpath中配置的类。
--User-Defined Class Loader:
这是开发人员通过拓展ClassLoader类定义的自定义加载器,加载程序员定义的一些类。
委派模式(Delegation Mode)仔细看上面的层次结构,当JVM加载一个类的时候,下层的加载器会将将任务委托给上一层类加载器,上一层加载检查它的命名空间中是否已经加载这个类,如果已经加载,直接使用这个类。如果没有加载,继续往上委托直到顶部。检查完了之后,按照相反的顺序进行加载,如果Bootstrap加载器找不到这个类,则往下委托,直到找到类文件。对于某个特定的类加载器来说,一个Java类只能被载入一次,也就是说在Java虚拟机中,类的完整标识是(classLoader,package,className)。一个类可以被不同的类加载器加载。用图示表示如下:
举个具体的例子来说明,现在假如有一个自己定义的类MyClass需要加载,如果不指定的话,一般交App(System)加载。接到任务后,System检查自己的库里是否已经有这个类,发现没有之后委托给Extension,Extension进行同样的检查,发现还是没有继续往上委托,最顶层的Boots发现自己库里也没有,于是根据它的路径(Java 核心类库,如java.lang)尝试去加载,没找到这个MaClass类,于是只好往下委托给Extension,Extension到自己的路径(JAVA_HOME/jre/lib/ext)中找,还是没找到,继续往下,此时System加载器到classpath路径寻找,找到了,于是加载到Java虚拟机。
现在假设我们将这个类放到JAVA_HOME/jre/lib/ext这个路径中去(相当于交给Extension加载器加载),按照同样的规则,最后由Extension加载器加载MyClass类,看到了吧,同一个类被两次加载到JVM,但是每次都是由不同的ClassLoader完成。
可见性限制
下层的加载器能够看到上层加载器中的类,反之则不行,也就是是说委托只能从下到上。
不允许卸载类
类加载器可以加载一个类,但是它不能卸载一个类。但是类加载器可以被删除或者被创建
当类加载完成之后,该类的生命周期就开始了,JVM将完成该类的装载,连接,与初始化。
装载:
Loading:将文件系统中的Class文件载入到JVM内存(运行数据区域)
连接:
Verifying:检查载入的类文件是否符合Java规范和虚拟机规范。
Preparing:为这个类分配所需要的内存,确定这个类的属性、方法等所需的数据结构。(Prepare a data structure that assigns the memory required by classes andindicates the fields, methods, and interfaces defined in the class.)
Resolving:将该类常量池中的符号引用都改变为直接引用。
初始化:
Initialing:初始化类的局部变量,为静态域赋值,同时执行静态初始化块。
2运行时数据区
Runtime Data Areas:当运行一个JVM示例时,系统将分配给它一块内存区域(这块内存区域的大小可以设置的),这一内存区域由JVM自己来管理。从这一块内存中分出一块用来存储一些运行数据,例如创建的对象,传递给方法的参数,局部变量,返回值等等。这块就称为运行数据区域。运行数据区域可以划分为6大块:Java栈、程序计数寄存器(PC寄存器)、本地方法栈(Native Method Stack)、Java堆、方法区域、运行常量池(Runtime Constant Pool)。运行常量池本应该属于方法区,但是由于其重要性,JVM规范将其独立出来说明。其中,前面3各区域(PC寄存器、Java栈、本地方法栈)是每个线程独自拥有的,后三者则是整个JVM实例中的所有线程共有的。这六大块如下图所示:

PC计数器:
每一个线程都拥有一个PC计数器,当线程启动(start)时,PC计数器被创建,这个计数器存放当前正在被执行的字节码指令(JVM指令)的地址。
Java栈:
同样的,Java栈也是每个线程单独拥有,线程启动时创建。这个栈中存放着一系列的栈帧(Stack Frame),JVM只能进行压入(Push)和弹出(Pop)栈帧这两种操作。每当调用一个方法时,JVM就往栈里压入一个栈帧,方法结束返回时弹出栈帧。如果方法执行时出现异常,可以调用printStackTrace等方法来查看栈的情况。栈的示意图如下:
OK。现在我们再来详细看看每一个栈帧中都放着什么东西。从示意图很容易看出,每个栈帧包含三个部分:本地变量数组,操作数栈,方法所属类的常量池引用。
》局部(本地)变量数组:
局部(本地)变量数组中,从0开始按顺序存放方法所属对象的引用、传递给方法的参数、局部变量。举个例子:
...
}
这个方法的栈帧中的局部变量存储的内容分别是:
0: this
1: a
2,3:b
4:0
看仔细了,其中double类型的b需要两个连续的索引。取值的时候,取出的是2这个索引中的值。如果是静态方法,则数组第0个不存放this引用,而是直接存储传递的参数。
操作数栈:
操作数栈中存放方法执行时的一些中间变量,JVM在执行方法时压入或者弹出这些变量。其实,操作数栈是方法真正工作的地方,执行方法时,局部变量数组与操作数栈根据方法定义进行数据交换。
栈帧中数据引用:
除了局部变量数组和操作数栈之外,栈帧还需要一个常量池的引用。当JVM执行到需要常量池的数据时,就是通过这个引用来访问常量池的。栈帧中的数据还要负责处理方法的返回和异常。如果通过return返回,则将该方法的栈帧从Java栈中弹出。如果方法有返回值,则将返回值压入到调用该方法的方法的操作数栈中。另外,数据区中还保存中该方法可能的异常表的引用。
本地方法栈
当程序通过JNI(Java Native Interface)调用本地方法(如C或者C++代码)时,就根据本地方法的语言类型建立相应的栈。
方法区域
方法区域是一个JVM实例中的所有线程共享的,当启动一个JVM实例时,方法区域被创建。它用于存运行放常量池、有关域和方法的信息、静态变量、类和方法的字节码。不同的JVM实现方式在实现方法区域的时候会有所区别。Oracle的HotSpot称之为永久区域(Permanent Area)或者永久代(Permanent Generation)。
运行常量池
这个区域存放类和接口的常量,除此之外,它还存放方法和域的所有引用。当一个方法或者域被引用的时候,JVM就通过运行常量池中的这些引用来查找方法和域在内存中的的实际地址。
堆(Heap)
1)堆中存放的是程序创建的实例对象和数组。这个区域对JVM的性能影响很大。垃圾回收机制处理的正是这一块内存区域。
2)一个java虚拟机实例只存在一个堆空间,因此虚拟机中的所有线程都共享这个堆;
3)一个java程序独占一个java虚拟机实例,因此每个java程序都有他自己的堆空间;
类加载器加载其实就是根据编译后的Class文件,将java字节码载入JVM内存,并完成对运行数据处于的初始化工作,供执行引擎执行,接下来就了解一下java执行引擎
3执行引擎
类加载器将字节码载入内存之后,执行引擎以Java 字节码指令为单元,读取Java字节码。但是java字节码机器是读不懂的,因此还必须想办法将字节码转化成平台相关的机器码。这个过程可以由解释器来执行或即时编译器(JIT Compiler)来完成。用图示表示如下:
