redis基本数据结构之压缩列表
压缩列表(ziplist)时列表键和哈希键的底层实现之一。压缩列表时redis为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。
接下来给大家展示以下压缩列表的具体结构:
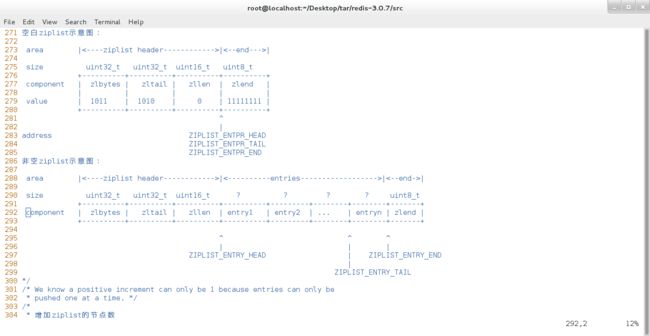
在表中列出了空的压缩列表和非空的压缩列表的具体是如何存储的。
下面我们来看redis是如何对压缩列表定义的:
/* The ziplist is a specially encoded dually linked list that is designed * to be very memory efficient. * * Ziplist 是为了尽可能地节约内存而设计的特殊编码双端链表。 * * It stores both strings and integer values, * where integers are encoded as actual integers instead of a series of * characters. * * Ziplist可以存储字符串值和整数值, * 其中,整数值被保存为整数,而不是字符数组。 * * It allows push and pop operations on either side of the list * in O(1) time. However, because every operation requires a reallocation of * the memory used by the ziplist, the actual complexity is related to the * amount of memory used by the ziplist. * * Ziplist允许在列表的两端进行o(1)复杂度的push和pop操作。 * 但是,因为这些操作都需要对整个Ziplist进行内存分配 * 所以实际的复杂度和ziplist占用的内存大小有关。 * ---------------------------------------------------------------------------- * * ZIPLIST OVERALL LAYOUT: * Ziplist整体布局: * * The general layout of the ziplist is as follows: * 以下是ziplist的一般布局: * * <zlbytes><zltail><zllen><entry><entry><zlend> * * <zlbytes> is an unsigned integer to hold the number of bytes that the * ziplist occupies. This value needs to be stored to be able to resize the * entire structure without the need to traverse it first. * * <zlbytes>是一个无符号整数,保存着ziplist使用的内存数量。 * 通过这个值,程序员可以直接对ziplist的内存大小进行调整 * * <zltail> is the offset to the last entry in the list. This allows a pop * operation on the far side of the list without the need for full traversal. * * <zltail>保存着到达列表中最后一个节点的偏移量 * 这个偏移量使得对表尾的pop操作可以在无需遍历整个列表的情况下进行。 * * <zllen> is the number of entries.When this value is larger than 2**16-2, * we need to traverse the entire list to know how many items it holds. * * <zllen>保存着列表中的节点的数量, * 当zllen保存的值大于65536时, * 程序需要遍历整个列表才能知道列表实际包含了多少个节点 * * <zlend> is a single byte special value, equal to 255, which indicates the * end of the list. * * <zlend>的长度为1字节,值为255,标识列表的末尾 * * ZIPLIST ENTRIES: * ZIPLIST 节点: * * Every entry in the ziplist is prefixed by a header that contains two pieces * of information. First, the length of the previous entry is stored to be * able to traverse the list from back to front. Second, the encoding with an * optional string length of the entry itself is stored. * * 每个ziplist节点的前面都带有一个header,这个header包含两部分信息: * (1)前置节点的长度,在程序从后向前遍历时使用, * (2)当前节点所保存的值的类型和长度 * * The length of the previous entry is encoded in the following way: * If this length is smaller than 254 bytes, it will only consume a single * byte that takes the length as value. When the length is greater than or * equal to 254, it will consume 5 bytes. The first byte is set to 254 to * indicate a larger value is following. The remaining 4 bytes take the * length of the previous entry as value. * * 编码前置节点的长度的方法如下: * (1)如果前置节点的长度小于254字节,那么程序将使用1个字节来保存这个长度 * (2)如果前置节点的长度大于等于254字节,那么程序将使用5个字节来保存这个长度值: * (a)第一个字节的值被设为254,用于标识这是一个5字节长的长度值 * (b)之后的4个字节则用于保存前置节点的实际长度。 * * The other header field of the entry itself depends on the contents of the * entry. When the entry is a string, the first 2 bits of this header will hold * the type of encoding used to store the length of the string, followed by the * actual length of the string. When the entry is an integer the first 2 bits * are both set to 1. The following 2 bits are used to specify what kind of * integer will be stored after this header. An overview of the different * types and encodings is as follows: * * header另一部分的内容和节点所保存的值有关。 * * (1)如果节点保存的是字符串值, * 那么这部分的header的头2个位保存编码字符串长度所使用的类型, * 而之后跟着的内容则是字符串的实际长度 * * |00pppppp| - 1 byte * String value with length less than or equal to 63 bytes (6 bits). * 字符串的长度小于或等于63字节。 * |01pppppp|qqqqqqqq| - 2 bytes * String value with length less than or equal to 16383 bytes (14 bits). * 字符串的长度小于或等于16383字节 * |10______|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes * String value with length greater than or equal to 16384 bytes. * 字符串的长度大于或等于16384个字节。 * * (2)如果节点保存的是整数, * 那么这部分header的头2位都被设置为1, * 而之后跟着的2位则用于标识所保存的整数的类型。 * * |11000000| - 1 byte * Integer encoded as int16_t (2 bytes). * 节点的值为int16_t类型的整数,长度为2个字节 * |11010000| - 1 byte * Integer encoded as int32_t (4 bytes). * 节点的值为int32_t类型的整数,长度为4个字节 * |11100000| - 1 byte * Integer encoded as int64_t (8 bytes). * 节点的值为int64_t类型的整数,长度为8个字节 * |11110000| - 1 byte * Integer encoded as 24 bit signed (3 bytes). * 节点的值为24位(3字节)长的整数 * |11111110| - 1 byte * Integer encoded as 8 bit signed (1 byte). * 节点的值为8位(1字节)长的整数 * |1111xxxx| - (with xxxx between 0000 and 1101) immediate 4 bit integer. * Unsigned integer from 0 to 12. The encoded value is actually from * 1 to 13 because 0000 and 1111 can not be used, so 1 should be * subtracted from the encoded 4 bit value to obtain the right value. * 节点的值介于0至12之间的无符号数, * 因为0000和1111都不能使用,所以位的实际值将是1至13。 * 程序在取得这4位的值之后,还需要减去1,才能计算出正确的值。 * 比如说,如果位的值位为0001 = 1,那么程序返回的值将是1- 1=0。 * |11111111| - End of ziplist. * ziplist的结尾标志。 * All the integers are represented in little endian byte order. * * 所有的整数都表示为小端字节序。 * ---------------------------------------------------------------------------- * * Copyright (c) 2009-2012, Pieter Noordhuis <pcnoordhuis at gmail dot com> * Copyright (c) 2009-2012, Salvatore Sanfilippo <antirez at gmail dot com> * All rights reserved. * * Redistribution and use in source and binary forms, with or without * modification, are permitted provided that the following conditions are met: * * * Redistributions of source code must retain the above copyright notice, * this list of conditions and the following disclaimer. * * Redistributions in binary form must reproduce the above copyright * notice, this list of conditions and the following disclaimer in the * documentation and/or other materials provided with the distribution. * * Neither the name of Redis nor the names of its contributors may be used * to endorse or promote products derived from this software without * specific prior written permission. * * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" * AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE * IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE * ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE * LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR * CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF * SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS * INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN * CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) * ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE * POSSIBILITY OF SUCH DAMAGE. */ #include <stdio.h> #include <stdlib.h> #include <string.h> #include <stdint.h> #include <limits.h> #include "zmalloc.h" #include "util.h" #include "ziplist.h" #include "endianconv.h" #include "redisassert.h" /* * ziplist末端标识符,以及5字节标识符 * * * */ #define ZIP_END 255 #define ZIP_BIGLEN 254 /* Different encoding/length possibilities */ /* * 字符串编码和整数编码的掩码 * * */ #define ZIP_STR_MASK 0xc0 #define ZIP_INT_MASK 0x30 /* * 字符串编码类型 * * */ //编码长度1字节,长度小于或等于63字节的字节数组 #define ZIP_STR_06B (0 << 6) //编码长度为2字节,长度小于等于16383字节的字节数组 #define ZIP_STR_14B (1 << 6) //编码长度为5字节,长度小于等于4294967295的字节数组 #define ZIP_STR_32B (2 << 6) /* * 整数编码类型 * * * */ //编码长度1字节,int16_t类型的整数 #define ZIP_INT_16B (0xc0 | 0<<4) //编码长度1字节,int32_t类型的整数 #define ZIP_INT_32B (0xc0 | 1<<4) //编码长度1字节,int64_t类型的整数 #define ZIP_INT_64B (0xc0 | 2<<4) //编码长度1字节,24位有符号的整数 #define ZIP_INT_24B (0xc0 | 3<<4) //8位有符号整数 #define ZIP_INT_8B 0xfe /* 4 bit integer immediate encoding */ /* * 4位整数编码的掩码和类型 * * */ #define ZIP_INT_IMM_MASK 0x0f #define ZIP_INT_IMM_MIN 0xf1 /* 11110001 */ #define ZIP_INT_IMM_MAX 0xfd /* 11111101 */ #define ZIP_INT_IMM_VAL(v) (v & ZIP_INT_IMM_MASK) /* * 24位整数的最大值和最小值 * */ #define INT24_MAX 0x7fffff #define INT24_MIN (-INT24_MAX - 1) /* Macro to determine type */ /* * 查看给定编码enc是否字符串编码 * * */ #define ZIP_IS_STR(enc) (((enc) & ZIP_STR_MASK) < ZIP_STR_MASK) /* Utility macros */ /* * ziplist属性宏 * * */ //定位到ziplist的bytes属性,该属性记录了整个ziplist所占用的内存字节数 //用于取出bytes属性的现有值,或者bytes属性赋予新值 #define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl))) //定位到ziplist的offset属性,该属性记录了到达表尾节点的偏移量 //用于取出offset属性的现有值,或者为offset属性赋予新值 #define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t)))) //定位到ziplist的length属性,该属性记录了ziplist包含的节点数量 //用于取出length属性的现有值,或者为length属性赋予新值 #define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2))) //返回ziplist表头的大小 #define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t)) //返回指向ziplist第一个节点(的起始位置)的指针 #define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE) //返回指向ziplist的最后一个节点(的起始位置)的指针 #define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) //返回指向ziplist末端ZIP_END(的起始位置)的指针 #define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
上述主要对压缩列表的各个属性做了解释,还有对于字符串和整数的编码,定义了redis的属性宏。。。
下面我们来看压缩列表节点的定义:
typedef struct zlentry {
//prevrawlen:前置节点的长度
//prevrawlensize:编码prevrawlen所需的字节大小
unsigned int prevrawlensize, prevrawlen;
//len:当前节点的长度
//lensize:编码len所需的字节大小
unsigned int lensize, len;
//当前节点header的大小
//等于prevrawlensize + lensize
unsigned int headersize;
//当前节点所使用的编码类型
unsigned char encoding;
//指向当前节点的指针
unsigned char *p;
} zlentry;
/* Extract the encoding from the byte pointed by 'ptr' and set it into
* 'encoding'. */
/*
* 从ptr中取出节点值的编码类型,并将它保存在encoding变量中。
*
* */
#define ZIP_ENTRY_ENCODING(ptr, encoding) do { \
(encoding) = (ptr[0]); \
if ((encoding) < ZIP_STR_MASK) (encoding) &= ZIP_STR_MASK; \
} while(0)
/*
* 增加ziplist的节点数
*
*
* */
#define ZIPLIST_INCR_LENGTH(zl,incr) { \
if (ZIPLIST_LENGTH(zl) < UINT16_MAX) \
ZIPLIST_LENGTH(zl) = intrev16ifbe(intrev16ifbe(ZIPLIST_LENGTH(zl))+incr); \
}上述就是redis对于压缩列表节点的定义。
下面我们来看redis对于一下接口的具体实现:
/* Return bytes needed to store integer encoded by 'encoding' */
/*
* 返回保存encoding编码的值所需要的字节数量
*
* */
static unsigned int zipIntSize(unsigned char encoding) {
switch(encoding) {
case ZIP_INT_8B: return 1;
case ZIP_INT_16B: return 2;
case ZIP_INT_24B: return 3;
case ZIP_INT_32B: return 4;
case ZIP_INT_64B: return 8;
default: return 0; /* 4 bit immediate */
}
assert(NULL);
return 0;
}
/* Encode the length 'rawlen' writing it in 'p'. If p is NULL it just returns
* the amount of bytes required to encode such a length. */
/*
* 编码节点的长度值为l,并将它写入到p中,然后返回编码l所需的字节数量。
*
* 如果p为NULL,那么仅返回编码l所需的字节数量,不进行写入
*
* */
static unsigned int zipEncodeLength(unsigned char *p, unsigned char encoding, unsigned int rawlen) {
unsigned char len = 1, buf[5];
//判断encoding是否为字符串编码
if (ZIP_IS_STR(encoding)) {
/* Although encoding is given it may not be set for strings,
* so we determine it here using the raw length. */
if (rawlen <= 0x3f) {
//rawlen 长度小于等于63字节的字节数组
//编码长度为1个字节
if (!p) return len;
//程序执行到这一步时,说明p不为空,要将编码节点的长度值写入p中
//ZIP_STR_06B == 00bbbbbb
buf[0] = ZIP_STR_06B | rawlen;
} else if (rawlen <= 0x3fff) {
//rawlen长度小于等于16383字节的字节数组
//编码长度为2个字节
len += 1;
if (!p) return len;
buf[0] = ZIP_STR_14B | ((rawlen >> 8) & 0x3f);
buf[1] = rawlen & 0xff;
} else {
//否则,长度小于等于4294967295的字节数组
//编码长度为5个字节
len += 4;
if (!p) return len;
buf[0] = ZIP_STR_32B;
buf[1] = (rawlen >> 24) & 0xff;
buf[2] = (rawlen >> 16) & 0xff;
buf[3] = (rawlen >> 8) & 0xff;
buf[4] = rawlen & 0xff;
}
} else {
//编码整数
/* Implies integer encoding, so length is always 1. */
if (!p) return len;
buf[0] = encoding;
}
/* Store this length at p */
//将编码的长度写入p
memcpy(p,buf,len);
//返回编码所需的字节数
return len;
}
/* Decode the length encoded in 'ptr'. The 'encoding' variable will hold the
* entries encoding, the 'lensize' variable will hold the number of bytes
* required to encode the entries length, and the 'len' variable will hold the
* entries length.
*
* 解码ptr指针,取出列表节点的相关信息,并将它们保存在以下变量中:
*
* -encoding 保存节点值的编码类型
*
* -lensize 保存编码节点长度所需的字节数
*
* -len 保存节点所需的长度
*
* */
#define ZIP_DECODE_LENGTH(ptr, encoding, lensize, len) do { \
//取出节点值的编码类型,并保存到encoding变量中
ZIP_ENTRY_ENCODING((ptr), (encoding)); \
if ((encoding) < ZIP_STR_MASK) { \
//字符串编码
if ((encoding) == ZIP_STR_06B) { \
//如果编码为00bbbbbb
//编码节点长度所需要的字节数为1
(lensize) = 1; \
//保存节点所需的长度
(len) = (ptr)[0] & 0x3f; \
} else if ((encoding) == ZIP_STR_14B) { \
//如果编码为01bbbbbb
//编码节点长度所需要的字节数为2
(lensize) = 2; \
//保存节点所需的长度
(len) = (((ptr)[0] & 0x3f) << 8) | (ptr)[1]; \
} else if (encoding == ZIP_STR_32B) { \
//如果编码为10_ _ _ _ _ _ _
//编码节点长度所需要的字节数为5
(lensize) = 5; \
(len) = ((ptr)[1] << 24) | \
((ptr)[2] << 16) | \
((ptr)[3] << 8) | \
((ptr)[4]); \
} else { \
//否则直接退出
assert(NULL); \
} \
} else { \
//编码整数
(lensize) = 1; \
//保存encoding编码的值所需的字节长度
(len) = zipIntSize(encoding); \
} \
} while(0);
/* Encode the length of the previous entry and write it to "p". Return the
* number of bytes needed to encode this length if "p" is NULL.
*
* 对前置节点的长度len进行编码,并将它写入到p中,
* 然后返回编码len所需的字节数量
*
* 如果p为空,那么不进行写入,仅返回编码len所需的字节数量
*
* */
static unsigned int zipPrevEncodeLength(unsigned char *p, unsigned int len) {
if (p == NULL) {
//p为空时,仅返回编码len所需的字节数量
//如果len < 254时,编码len仅需要1个字节
return (len < ZIP_BIGLEN) ? 1 : sizeof(len)+1;
} else {
//当p不为空时
if (len < ZIP_BIGLEN) {
//(1)如果len < 254时
p[0] = len;
return 1;
} else {
//(2)如果len > 254时
//第一个字节被设置为254
p[0] = ZIP_BIGLEN;
//将len的值拷贝到字符串从p+1开始的位置
memcpy(p+1,&len,sizeof(len));
//大小端进行转换
memrev32ifbe(p+1);
//返回编码长度
return 1+sizeof(len);
}
}
}
/* Encode the length of the previous entry and write it to "p". This only
* uses the larger encoding (required in __ziplistCascadeUpdate).
*
* 将原本只需要1个字节来保存的前置节点长度len编码至一个5字节长的header中
*
* */
static void zipPrevEncodeLengthForceLarge(unsigned char *p, unsigned int len) {
//如果p为空,则直接返回
if (p == NULL) return;
//当p不为空时,首先将p[0]设置为254,用于标识5字节长度标识
p[0] = ZIP_BIGLEN;
//内存拷贝,将len写入字符串p + 1的位置
memcpy(p+1,&len,sizeof(len));
//大小端的转换
memrev32ifbe(p+1);
}
/* Decode the number of bytes required to store the length of the previous
* element, from the perspective of the entry pointed to by 'ptr'.
*
* 解码ptr指针,取出解码前置节点长度的字节数,并将它保存到prevlensize变量中。
*
* */
#define ZIP_DECODE_PREVLENSIZE(ptr, prevlensize) do { \
if ((ptr)[0] < ZIP_BIGLEN) { \
//当ptr[0]小于254时,说明前置节点的字节数为1
(prevlensize) = 1; \
} else { \
//否则说明前置节点的字节数为5
(prevlensize) = 5; \
} \
} while(0);
/* Decode the length of the previous element, from the perspective of the entry
* pointed to by 'ptr'.
*
* 解码pre指针,
* 取出编码前置节点长度所需的字节数,并将它保存到prevlensize变量中。
*
* 然后根据prevlensize,从ptr中取出前置节点的长度值,
* 并将这个长度保存到prevlen变量中。
* */
#define ZIP_DECODE_PREVLEN(ptr, prevlensize, prevlen) do { \
//获取编码前置节点长度所需的字节数,并将其保存在prevlensize中
ZIP_DECODE_PREVLENSIZE(ptr, prevlensize); \
if ((prevlensize) == 1) { \
//如果所需字节数为1,则说明其长度值小于254,仅用一个字节就可以编码
(prevlen) = (ptr)[0]; \
} else if ((prevlensize) == 5) { \
//当所需字节数为5时,则说明其长度大于等于254。
assert(sizeof((prevlensize)) == 4); \
//如果前置节点的字节数为4时,将ptr从下标为1到4的内容拷贝到prevlen内
memcpy(&(prevlen), ((char*)(ptr)) + 1, 4); \
//进行大小端转换
memrev32ifbe(&prevlen); \
} \
} while(0);
/* Return the difference in number of bytes needed to store the length of the
* previous element 'len', in the entry pointed to by 'p'.
*
* 计算编码新的前置节点长度len所需的字节数
* 减去编码p原来的前置节点长度所需的字节数之差
* */
static int zipPrevLenByteDiff(unsigned char *p, unsigned int len) {
unsigned int prevlensize;
//取出前置节点长度所需的字节数,并将它保存在prevlensize变量中
ZIP_DECODE_PREVLENSIZE(p, prevlensize);
//计算编码len所需的字节数,然后进行减法
return zipPrevEncodeLength(NULL, len) - prevlensize;
}
/* Return the total number of bytes used by the entry pointed to by 'p'.
*
* 返回指针p所指向的节点占用的字节数总和
*
* */
static unsigned int zipRawEntryLength(unsigned char *p) {
unsigned int prevlensize, encoding, lensize, len;
//解码p指针,取出编码前置节点长度所需的字节数,并将它保存到prevlensize中。
ZIP_DECODE_PREVLENSIZE(p, prevlensize);
//encoding:用于保存当前节点的编码类型
//lensize:用于保存当前节点长度所需的字节数
//len:保存当前节点长度
ZIP_DECODE_LENGTH(p + prevlensize, encoding, lensize, len);
//返回占用的总的字节总和
return prevlensize + lensize + len;
}
/* Check if string pointed to by 'entry' can be encoded as an integer.
* Stores the integer value in 'v' and its encoding in 'encoding'.
*
* 检查entry中指定的字符串能否被编码为整数
*
* 如果可以的话,
* 将编码的整数保存在指针v的值中,并将编码方式保存在指针encoding的值中。
*
*
*
* */
static int zipTryEncoding(unsigned char *entry, unsigned int entrylen, long long *v, unsigned char *encoding) {
long long value;
//忽略太长或太短的字符串
if (entrylen >= 32 || entrylen == 0) return 0;
//将一个字符串转换为long long 类型
if (string2ll((char*)entry,entrylen,&value)) {
/* Great, the string can be encoded. Check what's the smallest
* of our encoding types that can hold this value. */
//当转换成功时,
//以从大到小的顺序检查适合value的编码方式
if (value >= 0 && value <= 12) {
*encoding = ZIP_INT_IMM_MIN+value;
} else if (value >= INT8_MIN && value <= INT8_MAX) {
*encoding = ZIP_INT_8B;
} else if (value >= INT16_MIN && value <= INT16_MAX) {
*encoding = ZIP_INT_16B;
} else if (value >= INT24_MIN && value <= INT24_MAX) {
*encoding = ZIP_INT_24B;
} else if (value >= INT32_MIN && value <= INT32_MAX) {
*encoding = ZIP_INT_32B;
} else {
*encoding = ZIP_INT_64B;
}
//使用指针记录value的值
*v = value;
//返回转换成功的标识
return 1;
}
//转换失败
return 0;
}
/* Store integer 'value' at 'p', encoded as 'encoding'
*
* 以encoding指定的编码方式,将整数值value写入到p
*
* */
static void zipSaveInteger(unsigned char *p, int64_t value, unsigned char encoding) {
int16_t i16;
int32_t i32;
int64_t i64;
if (encoding == ZIP_INT_8B) {
//当编码方式为8为有符号的整数时
//编码长度只需要一个字节,
((int8_t*)p)[0] = (int8_t)value;
} else if (encoding == ZIP_INT_16B) {
//当编码方式为int32_t类型的整数时,
//编码长度为1个字节
//i16用于保存int16_t类型的整数
i16 = value;
//内存拷贝,将i16的值拷贝到字符串指针p中
memcpy(p,&i16,sizeof(i16));
//进行大小端转换
memrev16ifbe(p);
} else if (encoding == ZIP_INT_24B) {
//当编码方式为24位有符号数时,
i32 = value<<8;
memrev32ifbe(&i32);
memcpy(p,((uint8_t*)&i32)+1,sizeof(i32)-sizeof(uint8_t));
} else if (encoding == ZIP_INT_32B) {
//当编码方式为int32_t类型的整数时
i32 = value;
//内存拷贝
memcpy(p,&i32,sizeof(i32));
//大小端转换
memrev32ifbe(p);
} else if (encoding == ZIP_INT_64B) {
//当编码方式为int64_t类型时,
i64 = value;
//内存拷贝
memcpy(p,&i64,sizeof(i64));
//大小端转换
memrev64ifbe(p);
} else if (encoding >= ZIP_INT_IMM_MIN && encoding <= ZIP_INT_IMM_MAX) {
/* Nothing to do, the value is stored in the encoding itself. */
//否则,什么也不做
} else {
assert(NULL);
}
}
/* Read integer encoded as 'encoding' from 'p'
*
* 以encoding指定的编码方式,读取并返回指针p中的整数值
*
* */
static int64_t zipLoadInteger(unsigned char *p, unsigned char encoding) {
int16_t i16;
int32_t i32;
int64_t i64, ret = 0;
if (encoding == ZIP_INT_8B) {
//当编码方式为8位的有符号整数时,
//其编码长度为1个字节
//首先将指针p转化为int8_t的类型
//然后将第一个字节里的内容赋给ret
ret = ((int8_t*)p)[0];
} else if (encoding == ZIP_INT_16B) {
//当编码方式为int16_t类型时,
//进行内存拷贝
memcpy(&i16,p,sizeof(i16));
//大小端转换
memrev16ifbe(&i16);
ret = i16;
} else if (encoding == ZIP_INT_32B) {
memcpy(&i32,p,sizeof(i32));
memrev32ifbe(&i32);
ret = i32;
} else if (encoding == ZIP_INT_24B) {
i32 = 0;
memcpy(((uint8_t*)&i32)+1,p,sizeof(i32)-sizeof(uint8_t));
memrev32ifbe(&i32);
ret = i32>>8;
} else if (encoding == ZIP_INT_64B) {
memcpy(&i64,p,sizeof(i64));
memrev64ifbe(&i64);
ret = i64;
} else if (encoding >= ZIP_INT_IMM_MIN && encoding <= ZIP_INT_IMM_MAX) {
ret = (encoding & ZIP_INT_IMM_MASK)-1;
} else {
assert(NULL);
}
return ret;
}
/* Return a struct with all information about an entry.
*
* 将p所指向的列表节点的信息全保存到zlentry中,并返回该zlentry
*
* */
static zlentry zipEntry(unsigned char *p) {
zlentry e;
//e.prevrawlensize保存着编码前一个节点的长度所需的字节数
//e.prevrawlen保存着前一个节点的长度
//调用ZIP_DECODE_PREVLEN 对p进行解码,取出编码前置节点长度所需的字节数和长度值分别保存在e.prevrawlensize和e.prevrawlen中
ZIP_DECODE_PREVLEN(p, e.prevrawlensize, e.prevrawlen);
//调用ZIP_DECODE_LENGTH 对p进行解码,
//e.encoding 保存节点值的编码类型
//e.lensize保存编码节点值长度所需的字节数
//e.len保存节点值的长度
ZIP_DECODE_LENGTH(p + e.prevrawlensize, e.encoding, e.lensize, e.len);
//计算头节点的字节数
e.headersize = e.prevrawlensize + e.lensize;
//记录指针
e.p = p;
return e;
}
上述的接口主要是一些静态的函数,只能在本文件内使用。
下面我们看几个操作压缩列表的函数:
(1)创建一个空的新的ziplist:
/* Create a new empty ziplist.
*
*创建并返回一个新的ziplist
* */
unsigned char *ziplistNew(void) {
//ZIPLIST_HEADER_SIZE是ziplist表头的大小
//1 字节是表末端ZIP_END的大小
unsigned int bytes = ZIPLIST_HEADER_SIZE+1;
//为表头和表尾分配空间
unsigned char *zl = zmalloc(bytes);
//初始化表的属性
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
//设置表末端
zl[bytes-1] = ZIP_END;
//返回空的新的ziplist
return zl;
}
(2)压缩列表的删除:
/* Resize the ziplist.
*
* 调整ziplist的大小为len个字节
*
*当ziplist原有的大小小于len时,扩展ziplist不会改变ziplist原有的元素
* */
static unsigned char *ziplistResize(unsigned char *zl, unsigned int len) {
//用zrealloc扩展时不改变现有元素
zl = zrealloc(zl,len);
//更新bytes属性
ZIPLIST_BYTES(zl) = intrev32ifbe(len);
//重新设置表末端
zl[len-1] = ZIP_END;
return zl;
}
/* When an entry is inserted, we need to set the prevlen field of the next
* entry to equal the length of the inserted entry. It can occur that this
* length cannot be encoded in 1 byte and the next entry needs to be grow
* a bit larger to hold the 5-byte encoded prevlen. This can be done for free,
* because this only happens when an entry is already being inserted (which
* causes a realloc and memmove). However, encoding the prevlen may require
* that this entry is grown as well. This effect may cascade throughout
* the ziplist when there are consecutive entries with a size close to
* ZIP_BIGLEN, so we need to check that the prevlen can be encoded in every
* consecutive entry.
*
* 当一个新节点添加到某个节点之前的时候,
* 如果原节点的header空间不足以保存新节点的长度,
* 那么就需要对原节点的header空间进行扩展(从1字节扩展到5字节)。
*
* 但是,当对原节点进行扩展之后,原节点的下一个节点的prevlen可能出现空间不足,
* 这种情况在多个连续节点的长度都接近于ZIP_BIGLEN时可能发生。
*
* 这个函数就用于检查并修复后续节点的空间问题
*
* Note that this effect can also happen in reverse, where the bytes required
* to encode the prevlen field can shrink. This effect is deliberately ignored,
* because it can cause a "flapping" effect where a chain prevlen fields is
* first grown and then shrunk again after consecutive inserts. Rather, the
* field is allowed to stay larger than necessary, because a large prevlen
* field implies the ziplist is holding large entries anyway.
*
* 反过来说,
* 因为节点的长度变小引起的连续缩小也可能出现,
*
* The pointer "p" points to the first entry that does NOT need to be
* updated, i.e. consecutive fields MAY need an update. */
static unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p) {
//curlen用于记录ziplist所占用的内存的字节数
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), rawlen, rawlensize;
size_t offset, noffset, extra;
unsigned char *np;
//定义ziplist结构体
zlentry cur, next;
while (p[0] != ZIP_END) {
//将p所指向的列表节点的信息全部保存到cur中
cur = zipEntry(p);
//当前p节点的整个entry的字节数
rawlen = cur.headersize + cur.len;
//调用函数zipPrevEncodeLength,由于第一个参数为NULL,则仅返回编码len所需的字节数量
//存储rawlen需要的字节数
rawlensize = zipPrevEncodeLength(NULL,rawlen);
/* Abort if there is no next entry. */
//如果已经没有后续空间需要更新了,跳出
//到达表尾
if (p[rawlen] == ZIP_END) break;
//取出后续节点的信息,保存到next结构中
next = zipEntry(p+rawlen);
/* Abort when "prevlen" has not changed. */
//后续节点编码当前节点的空间已经足够,无需再进行任何处理,跳出
//可以证明,只要遇到一个空间足够的节点,
//那么这个节点之后的所有节点的空间都是足够的
if (next.prevrawlen == rawlen) break;
if (next.prevrawlensize < rawlensize) {
/* The "prevlen" field of "next" needs more bytes to hold
* the raw length of "cur". */
//执行到这里,表示next空间的大小不足以编码cur的长度
//所以程序需要对next节点的(header部分)空间进行扩展
//记录p的偏移量
offset = p-zl;
//计算需要增加的字节数
extra = rawlensize-next.prevrawlensize;
//调用ziplistResize函数,调整ziplist的大小为len字节
//当ziplist原有的大小小于len时,扩展ziplist不会改变ziplist原有的元素
zl = ziplistResize(zl,curlen+extra);
p = zl+offset;
/* Current pointer and offset for next element. */
//新的下一个节点的首地址
np = p+rawlen;
//新节点的偏移量
noffset = np-zl;
/* Update tail offset when next element is not the tail element. */
if ((zl+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) != np) {
//ZIPLIST_TAIL_OFFSET(zl):记录到达表尾节点的偏移量
//当 np不是尾节点时
//更新zl的尾节点的偏移量
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra);
}
//当next节点不是表尾节点时,更新列表到表尾节点的偏移量
//
//不用更新的情况(next为表尾节点):
//
// | | next | ==> | | new next |
// ^ ^
// | |
// tail tail
//
// 需要更新的情况(next不是表位节点):
//
// | next | | ==> | new next | |
// ^ ^
// | |
// old tail old tail
// 更新之后:
// | new next | |
// ^
// |
// new tail
//
/* Move the tail to the back. */
//np + rawlensize :新的下一个节点存储自身数据的首地址
//np + next.prevrawlensize :旧的下一个节点存储自身数据的首地址
//向后移动cur节点之后的数据,为cur的新header腾出空间
//
//例:
// | header | value | ==> | header | | value | ==> | header | value |
// |<-->|
// 为新header腾出的空间
memmove(np+rawlensize,
np+next.prevrawlensize,
curlen-noffset-next.prevrawlensize-1);
//对前置节点p的长度进行编码写入到np中
zipPrevEncodeLength(np,rawlen);
/* Advance the cursor */
//移动指针,处理下一个节点
p += rawlen;
//更新ziplist所占用的字节数
curlen += extra;
} else {
//执行到这里说明next节点编码前置节点header空间有5字节
//而编码rawlen只需要1字节
//但是程序不会对next进行缩小
//所以这里只将rawlen写入5字节的header中算了
if (next.prevrawlensize > rawlensize) {
/* This would result in shrinking, which we want to avoid.
* So, set "rawlen" in the available bytes. */
zipPrevEncodeLengthForceLarge(p+rawlen,rawlen);
} else {
//运行到这正好说明cur节点的长度正好可以编码next节点的header中
zipPrevEncodeLength(p+rawlen,rawlen);
}
/* Stop here, as the raw length of "next" has not changed. */
//后续节点不用扩展
break;
}
}
return zl;
}
/* Delete "num" entries, starting at "p". Returns pointer to the ziplist.
*
* 从位置p开始,连续删除num个节点
*
* 函数返回值为处理删除操作之后的ziplist
*
* */
static unsigned char *__ziplistDelete(unsigned char *zl, unsigned char *p, unsigned int num) {
unsigned int i, totlen, deleted = 0;
size_t offset;
int nextdiff = 0;
zlentry first, tail;
//使用first记录节点p的所有信息
first = zipEntry(p);
//计算被删除节点的总个数
for (i = 0; p[0] != ZIP_END && i < num; i++) {
//zipRawEntryLength:用于计算节点p所占的节点数
p += zipRawEntryLength(p);
deleted++;
}
//totlen用于记录所有被删除节点占用的内存字节数
totlen = p-first.p;
if (totlen > 0) {
if (p[0] != ZIP_END) {
//执行到这里说明被删除的节点之后还有节点存在
/* Storing `prevrawlen` in this entry may increase or decrease the
* number of bytes required compare to the current `prevrawlen`.
* There always is room to store this, because it was previously
* stored by an entry that is now being deleted. */
//因为位于被删除节点范围之后的第一个节点的header部分的大小
//可能容纳不了新的前置节点,所以需要计算新旧前置节点的字节数差
nextdiff = zipPrevLenByteDiff(p,first.prevrawlen);
//将指针p后退nextdiff个字节,为新的header空出空间
p -= nextdiff;
//将first前置节点的长度编码至p中
zipPrevEncodeLength(p,first.prevrawlen);
/* Update offset for tail */
//更新到达表尾的偏移量
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))-totlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
//如果被删除节点之后,有多于一个节点
//那么程序需要将nextdiff记录的字节数也计算到表尾偏移量中
//这样才能让表尾的偏移量正确对齐表尾节点
tail = zipEntry(p);
if (p[tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
/* Move tail to the front of the ziplist */
//从表尾向表头移动数据,覆盖被删除节点的数据
memmove(first.p,p,
intrev32ifbe(ZIPLIST_BYTES(zl))-(p-zl)-1);
} else {
//执行到这里时,说明被删除节点之后没有其他的节点
/* The entire tail was deleted. No need to move memory. */
//更新表尾节点的偏移量
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe((first.p-zl)-first.prevrawlen);
}
//缩小并更新ziplist的长度
/* Resize and update length */
offset = first.p-zl;
zl = ziplistResize(zl, intrev32ifbe(ZIPLIST_BYTES(zl))-totlen+nextdiff);
ZIPLIST_INCR_LENGTH(zl,-deleted);
p = zl+offset;
/* When nextdiff != 0, the raw length of the next entry has changed, so
* we need to cascade the update throughout the ziplist */
//如果p所指向的节点的大小已经变更,那么进行级联更新
//检查p之后的所有节点是否符合ziplist编码的的要求
if (nextdiff != 0)
zl = __ziplistCascadeUpdate(zl,p);
}
return zl;
}
<span style="font-size:18px;"> 基于删除函数的封装:
</span>
/* Delete a single entry from the ziplist, pointed to by *p.
* Also update *p in place, to be able to iterate over the
* ziplist, while deleting entries.
*
* 从zl中删除*p所指向的节点,
* 并且原地更新*p所指向的位置,使得可以在迭代列表的过程中对节点进行删除
*
* */
unsigned char *ziplistDelete(unsigned char *zl, unsigned char **p) {
//因为在_ziplistDelete时会对zl进行内存的重分配
//而内存的重分配可能会改变zl的内存地址
//所以需要记录到达*p的偏移量
//这样可以在删除节点之后通过偏移量来将*p还原到正确的位置
size_t offset = *p-zl;
//调用函数_ziplistDelete
zl = __ziplistDelete(zl,*p,1);
/* Store pointer to current element in p, because ziplistDelete will
* do a realloc which might result in a different "zl"-pointer.
* When the delete direction is back to front, we might delete the last
* entry and end up with "p" pointing to ZIP_END, so check this. */
*p = zl+offset;
return zl;
}
/* Delete a range of entries from the ziplist.
*
* 从index索引指定的节点开始,连续地从zl中删除num个节点
*
* */
unsigned char *ziplistDeleteRange(unsigned char *zl, unsigned int index, unsigned int num) {
//根据索引定位到节点
unsigned char *p = ziplistIndex(zl,index);
//如果p == NULL 说明根据下标没有定位到,
//如果不为空时,调用函数_ziplistDelete进行删除
return (p == NULL) ? zl : __ziplistDelete(zl,p,num);
}
(3)压缩列表的插入:
<span style="font-size:18px;">/* Insert item at "p".
*
* 根据指针p所指定的位置,将长度为slen的字符串s插入到zl中。
*
* 函数返回值为完成插入操作之后的ziplist
*
* */
static unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
//curlen记录ziplist占用内存总的字节数
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* initialized to avoid warning. Using a value
that is easy to see if for some reason
we use it uninitialized. */
zlentry tail;
/* Find out prevlen for the entry that is inserted. */
if (p[0] != ZIP_END) {
//如果p[0]不指向列表末端,说明列表非空,并且p正指向列表中的一个节点
//调用函数ZIP_DECODE_PREVLEN:解码p指针,
//使得prevlensize用来保存p节点的前置节点长度所需的字节数
//prevlen用于保存前置节点的长度
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
//如果p指向表尾末端,那么程序需要检查序列是否为:
// (1)如果ptail也指向表尾节点ZIP_END,那么列表为空
// (2)如果列表不为空,那么ptail将指向列表的最后一个节点
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
//如果列表不为空时:
//prevlen用于记录指针ptail所指向的节点占用的字节数总和
prevlen = zipRawEntryLength(ptail);
}
}
/* See if the entry can be encoded */
//调用函数zipTryEncoding:用于检查s指向的字符串能否被编码为整数
//如果可以的话,将编码后的整数保存在指针value中,并将编码方式保存在指针encoding的值中。
if (zipTryEncoding(s,slen,&value,&encoding)) {
//当编码成功时,reqlen用于保存encoding编码的值所需的字节数量
/* 'encoding' is set to the appropriate integer encoding */
reqlen = zipIntSize(encoding);
} else {
//当编码失败时,reqlen用于保存字符串s的长度
/* 'encoding' is untouched, however zipEncodeLength will use the
* string length to figure out how to encode it. */
reqlen = slen;
}
/* We need space for both the length of the previous entry and
* the length of the payload. */
//调用函数zipPrevEncodeLength 仅返回编码前置节点长度Prevlen所需的字节数量
reqlen += zipPrevEncodeLength(NULL,prevlen);
//编码当前节点所需的字节数量
reqlen += zipEncodeLength(NULL,encoding,slen);
/* When the insert position is not equal to the tail, we need to
* make sure that the next entry can hold this entry's length in
* its prevlen field. */
//只要新节点不是被添加到列表末端
//那么程序就需要检查p所指向的节点(的header)能否编码新节点的长度。
//nextdiff保存了新旧编码之间的字节大小差,如果这个值大于0,
//那么说明需要对p所指向的节点(的header)进行扩展
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
/* Store offset because a realloc may change the address of zl. */
//因为重分配空间可能会改变zl的地址,
//所以再分配之前,需要记录zl到p的偏移量,然后在分配之后依靠偏移量还原p
offset = p-zl;
//curlen:ziplist原来的长度
//reqlen:整个新节点的长度
//nextdiff:新节点的后继节点扩展header的长度(要么0字节,要么4字节)
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
p = zl+offset;
/* Apply memory move when necessary and update tail offset. */
if (p[0] != ZIP_END) {
//当列表不为空时,
/* Subtract one because of the ZIP_END bytes */
//新节点之后还有节点,因为新节点的加入,需要对这些原有的节点进行调整
//移动现有元素,为新元素的插入空间腾出位置
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* Encode this entry's raw length in the next entry. */
//将新节点的长度编码至后置节点
//p + reqlen 定位到后置节点
//reqlen是新节点的长度
zipPrevEncodeLength(p+reqlen,reqlen);
/* Update offset for tail */
//更新表尾的偏移量,将新节点的长度也算上
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
//如果新节点的后面多于一个节点
//那么程序需要将nextdiff记录的字节数也计算到表尾偏移量中
//这样才能让表尾偏移量正确对齐表尾节点
tail = zipEntry(p+reqlen);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
//新元素为表尾节点
/* This element will be the new tail. */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
/* When nextdiff != 0, the raw length of the next entry has changed, so
* we need to cascade the update throughout the ziplist */
//当nextdiff != 0时,新节点的后继节点的(header部分)长度已经被改变,
//所以需要级联地更新后续的节点
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* Write the entry */
//调用函数zipPrevEncodeLength:对前置节点的长度进行编码,并将它写入p中,
//返回编码prevlen所需的字节数量
p += zipPrevEncodeLength(p,prevlen);
//调用函数zipEncodeLength:编码节点长度值slen,并将它写入到p中,然后返回编码slen所需的字节数量
p += zipEncodeLength(p,encoding,slen);
//如果是编码字符串
if (ZIP_IS_STR(encoding)) {
//内存拷贝
memcpy(p,s,slen);
} else {
//否则,以encoding指定的编码方式,将整数值value写入到p
zipSaveInteger(p,value,encoding);
}
//更新列表的节点数量计数器
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}</span>
基于插入函数封装的一个函数:
/*
* 将长度为slen的字符串s推入到zl中。
*
* where 参数的值决定了推入方向:
* -值为ZIPLIST_HEAD时,将新值推入到表头
* -否则,将新值推入到表末端
*
* 函数的返回值:添加新值后的ziplist
* */
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where) {
unsigned char *p;
//根据where的值,决定将值推入到表头还是表尾
p = (where == ZIPLIST_HEAD) ? ZIPLIST_ENTRY_HEAD(zl) : ZIPLIST_ENTRY_END(zl);
//调用插入函数
return __ziplistInsert(zl,p,s,slen);
}
(3)压缩列表有关的查找(比如
返回下标对应的节点,返回前置节点,返回后置节点等
):
/* Returns an offset to use for iterating with ziplistNext. When the given
* index is negative, the list is traversed back to front. When the list
* doesn't contain an element at the provided index, NULL is returned.
*
* 根据给定的索引,遍历列表,并返回索引指定节点的指针
*
* 如果索引为正,那么从表头向表尾遍历
* 如果索引为负,那么从表尾向表头遍历
* 正数索引从0开始,负数索引从-1开始
*
* 如果索引超过列表的节点数量,或者列表为空,那么返回NULL
*
* */
unsigned char *ziplistIndex(unsigned char *zl, int index) {
unsigned char *p;
unsigned int prevlensize, prevlen = 0;
if (index < 0) {
//当索引为负数时
index = (-index)-1;
//定位表尾节点
p = ZIPLIST_ENTRY_TAIL(zl);
if (p[0] != ZIP_END) {
//如果列表不为空时,
//调用函数ZIP_DECODE_PREVLEN:解码p指针
//prevlensize:保存编码前置节点长度所所需的字节数
//prevlen:保存前置节点的长度值
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
//从表尾向表头遍历
while (prevlen > 0 && index--) {
p -= prevlen;
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
}
}
} else {
//当index > 0时
//定位表头节点
p = ZIPLIST_ENTRY_HEAD(zl);
//从表头开始遍历节点
while (p[0] != ZIP_END && index--) {
p += zipRawEntryLength(p);
}
}
//返回结果
return (p[0] == ZIP_END || index > 0) ? NULL : p;
}
/* Return pointer to next entry in ziplist.
*
* zl is the pointer to the ziplist
* p is the pointer to the current element
*
* The element after 'p' is returned, otherwise NULL if we are at the end.
*
* 返回p所指向节点的后置节点
*
* 如果p为表末端,或者p已经是表尾节点,那么返回NULL
*
* */
unsigned char *ziplistNext(unsigned char *zl, unsigned char *p) {
((void) zl);
/* "p" could be equal to ZIP_END, caused by ziplistDelete,
* and we should return NULL. Otherwise, we should return NULL
* when the *next* element is ZIP_END (there is no next entry). */
//如果p已经指向列表末端
if (p[0] == ZIP_END) {
return NULL;
}
//指向p的后一个节点
p += zipRawEntryLength(p);
if (p[0] == ZIP_END) {
//p已经是表尾节点,没有后置节点
return NULL;
}
return p;
}
/* Return pointer to previous entry in ziplist.
*
* 返回p所指向节点的前置节点
*
* 如果p指向为空列表,或者p已经指向表头节点,那么返回NULL
*
* */
unsigned char *ziplistPrev(unsigned char *zl, unsigned char *p) {
unsigned int prevlensize, prevlen = 0;
/* Iterating backwards from ZIP_END should return the tail. When "p" is
* equal to the first element of the list, we're already at the head,
* and should return NULL. */
//如果p指向表列表末端
if (p[0] == ZIP_END) {
//定位表尾节点
p = ZIPLIST_ENTRY_TAIL(zl);
//如果表尾节点也指向列表末端,那么列表为空,返回NULL,
//否则,返回p
return (p[0] == ZIP_END) ? NULL : p;
} else if (p == ZIPLIST_ENTRY_HEAD(zl)) {
//如果p指向表头节点,则其前置节点为NULL
return NULL;
} else {
//当p既不是表头也不是表尾时,
//调用ZIP_DECODE_PREVLEN函数:获得编码前置节点需要的字节数和前置节点的长度
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
//保证prevlen > 0
assert(prevlen > 0);
//移动指针指向前一个节点
return p-prevlen;
}
}
(4)
获取节点值:
<span style="font-size:18px;">/* Get entry pointed to by 'p' and store in either '*sstr' or 'sval' depending
* on the encoding of the entry. '*sstr' is always set to NULL to be able
* to find out whether the string pointer or the integer value was set.
* Return 0 if 'p' points to the end of the ziplist, 1 otherwise.
*
* 取出p所指向节点的值:
*
* -如果节点保存的是字符串,那么将字符串指针保存到*sstr中,字符串长度保存到*slen
*
* -如果节点保存的是整数,那么将整数保存到*sval
*
* 程序可以通过检查*sstr是否为NULL来检查值是字符串还是整数
*
* 提取成功返回1
* 如果p为空,或者p指向的是列表末端,那么返回0,提取值失败
*
* */
unsigned int ziplistGet(unsigned char *p, unsigned char **sstr, unsigned int *slen, long long *sval) {
zlentry entry;
//如果p == NULL 或 列表为空时,返回0,提取失败
if (p == NULL || p[0] == ZIP_END) return 0;
if (sstr) *sstr = NULL;
//取出p所指向的节点的各项信息,并保存到结构entry中
entry = zipEntry(p);
if (ZIP_IS_STR(entry.encoding)) {
//当节点的值为字符串,将字符串长度保存到*slen,字符串保存到*sstr
if (sstr) {
//字符串长度
*slen = entry.len;
//字符串内容
*sstr = p+entry.headersize;
}
} else {
//节点的值为整数时,
if (sval) {
//调用函数zipLoadInteger,以encoding指定的编码方式,读取并返回指针p中的整数值
*sval = zipLoadInteger(p+entry.headersize,entry.encoding);
}
}
return 1;
}
</span>
(5)节点值的比较:
/* Compare entry pointer to by 'p' with 'sstr' of length 'slen'. */
/* Return 1 if equal.
*
* 将p所指向的节点的值和sstr进行对比
*
* 如果节点值和sstr的值相等,返回1,不相等返回0
*
* */
unsigned int ziplistCompare(unsigned char *p, unsigned char *sstr, unsigned int slen) {
zlentry entry;
unsigned char sencoding;
long long zval, sval;
//如果列表为空,则返回0
if (p[0] == ZIP_END) return 0;
//取出节点p所对应的信息保存于entry中
entry = zipEntry(p);
if (ZIP_IS_STR(entry.encoding)) {
//如果节点值为字符串,进行字符串对比
/* Raw compare */
if (entry.len == slen) {
//如果节点p中保存的字符串长度 == slen
//调用字符串对比函数
return memcmp(p+entry.headersize,sstr,slen) == 0;
} else {
//两长度不相等时,返回0
return 0;
}
} else {
//如果节点值为整数时,
/* Try to compare encoded values. Don't compare encoding because
* different implementations may encoded integers differently. */
//调用函数zipEncoding:检查sstr中指向的字符串能否被编码为整数
//如果可以编码的话,将编码后的整数保存在sval中,将编码方式保存在sencoding中
if (zipTryEncoding(sstr,slen,&sval,&sencoding)) {
//当编码成功时,调用函数获取p节点的整数值
zval = zipLoadInteger(p+entry.headersize,entry.encoding);
return zval == sval;
}
}
return 0;
}
/* Find pointer to the entry equal to the specified entry. Skip 'skip' entries
* between every comparison. Returns NULL when the field could not be found.
*
* 寻找节点值和vstr相等的列表节点,并返回该节点的指针
*
* 每次对比之前都跳过skip个节点
*
* 如果找不到相应的节点,则返回NULL
*
* */
unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip) {
int skipcnt = 0;
unsigned char vencoding = 0;
long long vll = 0;
//只要没有到达列表末节点,就一直迭代
while (p[0] != ZIP_END) {
unsigned int prevlensize, encoding, lensize, len;
unsigned char *q;
//获得编码前置节点长度所需的字节数
ZIP_DECODE_PREVLENSIZE(p, prevlensize);
//调用函数获取列表节点的相关信息
//encoding:保存节点的编码类型
//lensize:保存编码节点长度所需的字节数
//len:保存节点的长度
ZIP_DECODE_LENGTH(p + prevlensize, encoding, lensize, len);
q = p + prevlensize + lensize;
if (skipcnt == 0) {
/* Compare current entry with specified entry */
if (ZIP_IS_STR(encoding)) {
//如果p中保存的是字符串,
//对比字符串
if (len == vlen && memcmp(q, vstr, vlen) == 0) {
return p;
}
} else {
/* Find out if the searched field can be encoded. Note that
* we do it only the first time, once done vencoding is set
* to non-zero and vll is set to the integer value. */
//因为传入值有可能被编码了
//所以当第一次进行值对比时,程序会对传入值进行解码
//这个解码操作只会进行1次
if (vencoding == 0) {
//调用函数zipTryEncoding:尝试将vstr编码为整数
if (!zipTryEncoding(vstr, vlen, &vll, &vencoding)) {
/* If the entry can't be encoded we set it to
* UCHAR_MAX so that we don't retry again the next
* time. */
//当编码失败时,
vencoding = UCHAR_MAX;
}
/* Must be non-zero by now */
assert(vencoding);
}
/* Compare current entry with specified entry, do it only
* if vencoding != UCHAR_MAX because if there is no encoding
* possible for the field it can't be a valid integer. */
if (vencoding != UCHAR_MAX) {
//当程序执行到这时,说明vstr可以编码为整数。
//q代表节点p所占的字节数,将p根据编码转化为整数
long long ll = zipLoadInteger(q, encoding);
if (ll == vll) {
return p;
}
}
}
/* Reset skip count */
skipcnt = skip;
} else {
/* Skip entry */
skipcnt--;
}
/* Move to next entry */
//指针后移
p = q + len;
}
return NULL;
}
/* Return length of ziplist.
*
* 返回ziplist中的节点个数
*
* */
unsigned int ziplistLen(unsigned char *zl) {
unsigned int len = 0;
//节点数小于< UINT16_MAX,直接返回其长度
if (intrev16ifbe(ZIPLIST_LENGTH(zl)) < UINT16_MAX) {
len = intrev16ifbe(ZIPLIST_LENGTH(zl));
} else {
//当节点数大于UINT16_MAX,需要遍历整个列表才能计算出节点
unsigned char *p = zl+ZIPLIST_HEADER_SIZE;
while (*p != ZIP_END) {
p += zipRawEntryLength(p);
len++;
}
/* Re-store length if small enough */
if (len < UINT16_MAX) ZIPLIST_LENGTH(zl) = intrev16ifbe(len);
}
return len;
}
/* Return ziplist blob size in bytes.
*
* 返回整个ziplist占用的内存字节数
* */
size_t ziplistBlobLen(unsigned char *zl) {
return intrev32ifbe(ZIPLIST_BYTES(zl));
}
上述则是所有redis对于压缩列表的实现!!!源代码我也做了比较清楚的说明,欢迎大家找茬!!!
看过源码的人应该知道,压缩列表在插入和删除时效率是比较低的,因为在压缩列表的节点的结构体中封装了一个叫prevlensize的成员,该成员记录的是编码前置节点所需的字节数,和prevlen记录前置节点的长度,在插入的过程中就会出现连锁更新的现象,删除也是如此,对于插入和删除的最坏的时间复杂度达到o(n^2),所以压缩列表不太适合数据量比较的时候,它适用于数据量不大的情况下。。。