《Linux内核完全剖析》阅读笔记
读完之后觉得很有收获,虽然版本很低,但是已经对OS有一个很具体的认识了,比理论上的要来得深刻、真实。下面是我自己学习过程的思考和总结,在看完细节之后主要从LINUX各个功能模块其及相互之间和内部的层次关系去考虑的,本文图片均取自该书。我觉得这篇总结性质的文章对还没有接触linux0.11内核的人来说肯定没有什么意义。应该只有读过的代码的人才会有同感吧。另外我看代码的时候使用了VC版的内核源码工程,代码中的注释与书中几乎一样。用VC可以更容易地在函数定义中跳转查看,节约时间,我的方法是看书上代码前给出的知识介绍,然后在电脑上看代码实现,一共用了十天把这本书主要部分看完了。这里给希望阅读代码的人分享一下:
http://www.mcuol.com/download/upfile/20071011080428_linux011VC.rar。
一.源码目录
<!--[if !vml]-->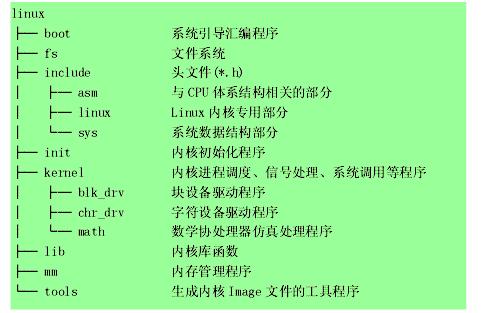 <!--[endif]-->
<!--[endif]-->
图1
二.系统总体流程:
系统从boot开始动作,把内核从启动盘装到正确的位置,进行一些基本的初始化,如检测内存,保护模式相关,建立页目录和内存页表,GDT表,IDT表。然后进入main进行初始化设置,main完成系统各个模块要用到的所有数据结构和外部设备的初始化。使得系统可以正常的工作。然后才进入用户模式。执行第一个fork生成进程1执行init,运行shell,接受并执行用户命令.
这里整个系统建立起来了,OS就处于被动状态,靠中断和系统调用来完成每一项服务。
三.各个目录的阅读总结:
(一) boot
1.bootsect.s :
bootsect.s编译结果生成一个512BYTE(一个扇区)镜像。这个扇区的最后一个字是0xAA55,倒数第二个字是root_dev变量,值为ROOT_DEV(306),即根文件系统所在的设备号。这段代码必须写入到启动盘的启动扇区,也就第一个物理扇区上。这样机器启动后,BIOS自动把它加载到7C00H处并跳到那里开始执行。bootsect将自己移动到90000H(576K)处,并跳至那里相应位置执行。然后利用BIOS中断将setup直接加载到自己的后面(90200h)(576.5K处),并将system加载到地址10000h处。 跳到setup中执行。
2.setup.s:
利用BIOS中断把系统参数如显卡,硬盘参数保存到内存90000开始的位置,即覆盖原bootsect所在的内存位置。再把整个system 模块移动到00000 位置。加载GDTR和IDTR,这里的GDT表是临时的,保存了两个描述符,即内核代码、内核数据段描述符,其段基地址为0。而加载IDT除了进入保护模式需要加载IDTR之外,没有任何意义。开启A20 地址线开启扩展内存。重新设置8259中断码0x20~0x2f。进入保护模式(PE置1)跳转到system模块中的head.s中(0处)执行。Bootsect.s和setup.s执行时内存变化情况。
<!--[if !vml]-->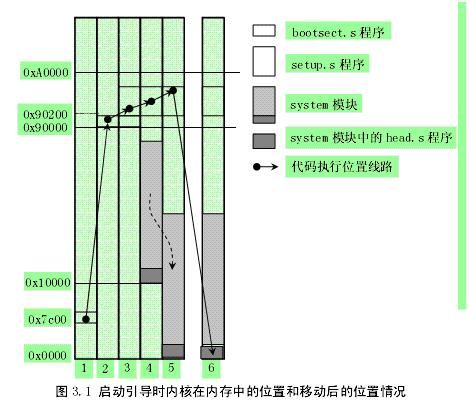 <!--[endif]-->
<!--[endif]-->
图2
3.head.s:
前4KB的代码将被页目录覆盖掉。这些代码执行的操作包括:设置系统堆栈为_stack_start。重新设置GDTR和IDTR。gdt,idt表都定义在head.s的末端,长度均为256项(2KBYTE)。第2个页面到第5个页面是系统的4张页表。最后一个页表后面的代码执行分页操作,即填充的4个页目录和4张页表的内容,实现对等映射,即物理地址=线性地址。每个页表项属性为存在并且用户可读写。设置好后置CR3页目录地址即0。启动分页标志,CR0的PG标志置1。跳到main函数中执行。
跳到main之前,内存布局如下:从0到16M
页目录4K(0x0开始)
页表1 4K
页表2 4K
页表3 4K
页表4 4K
软盘缓冲区1K
head.s后半部分代码
IDT表2K
GDT表2K
main.o代码部分
内核其余部分(大约到512K,end值为结束地址)
setup保存的系统参数(90000H~900200)这个区间还保存着root_dev.
BIOS(640K-1M)
主内存区(1M-16M)
现在初始化好了内核工作依赖的主要的数据结构是GDT和IDT表,还有页表。
(二)内核初始化init
main.c将进行进一步初始化工作。主要方面:分配主内存功能,IDT表各中断描述符重新设定,对内核其它模块如mm,fs进行初始化,然后移到用户模式下生成进程1执行init,常驻进程0死循环执行pause。进程init加载根文件系统,设置终端标准IO,创建进程2以/etc/rc为标准输入文件执行shell.完成rc文件中的命令。
init等进程2退出,进入死循环:创建子进程,建立新会话,设置标准IO终端,以登录方式执行shell.
至此系统动作起来了。
所以整个系统的建立起来后除了两个死循环的进程idle和init,其它的动作都是由用户在shell下执行命令,产生系统调用来工作的。
通过执行move_to_usermdoe(),idle和init进程都属于用户态下的进程。而内核则完全是中断驱动的。也就是说只有通过中断才能进入系统,如时钟和系统调用等。
所以问题的重点就在于内核各部分数据结构的建立、初始化、操作是怎样进行的。这些初始化流程涉及到内核各个模块全部重要的数据结构。
现在从main执行的一系列初始化代码来浅窥一下:
1.根据内存的大小,设置高速缓冲的末端。16M内存把高速缓冲末端设为4M。缓冲末端到主存末端为主内存区。
2.mem_init(main_memory_start,memory_end);主内存区初始化
设置高端内存HIGH_MEMORY=memory_end,
设置内存映射字节图mem_map [ PAGING_PAGES ],将不可用的全部置为USED,可用的置为0。mem_map数组是系统mm模块核心数据结构,记载了每个内存页使用计数。
3.trap_init().硬件中断向量表设置。
向IDT中填充各个中断描述符,使其指向对应的中断处理程序。对于错误,基本是结束当前进程。其他如外设中断都是各个模块初始化的时候向IDT表中相应项进行设置。
4.blk_dev_init(); // 块设备初始化。
初始化请求数组request[],将所有请求项置为空闲项(dev = -1)。
5.chr_dev_init(); // 字符设备初始化。尚为空操作。
6.tty_init(); // tty 初始化。
/// tty 终端初始化函数。
// 初始化串口终端和控制台终端。
void tty_init (void)
{
rs_init (); // 初始化串行中断程序和串行接口1 和2。(serial.c, 37)
con_init (); // 初始化控制台终端。(console.c, 617)
}
rs_init 初始化两个串口,安装串口中断处理IDT项。
con_init 初始化显示器和键盘。安装键盘中断处理IDT项。
7.time_init().取CMOS 时钟,并设置开机时间 startup_time(为从1970-1-1-0 时起到开机时的秒数)
8.sched_init(); // 调度程序初始化(加载了任务0 的tr, ldtr)
这里初始化与进程调度有关的数据结构。
手工设置了任务0的TSS和LDT到GDT表中。
清GDT表和task[NR_TASKS]数组其余部分。
ltr (0); // 将任务0 的TSS 加载到任务寄存器tr。
lldt (0); // 将局部描述符表加载到局部描述符表寄存器。
设置内核的工作心跳--8253定时器,安装定时器中断。
设置系统调用中断门:set_system_gate (0x80, &system_call);
9.buffer_init(buffer_memory_end);// 缓冲管理初始化,建内存链表等。
在内核的结束地址end(由连接程序生成)到buffer_memory_end之间(除掉640kb-1M的BIOS范围)区域中,建立缓冲区链表(表头start_buffer)并分配缓冲块(1KB)。
初始化空闲表free_list,HASH表hash_table。
10.hd_init();// 硬盘初始化。
blk_dev[MAJOR_NR].request_fn = DEVICE_REQUEST; //设置硬盘的设备请求函数为do_hd_request.
设置硬盘中断处理IDT项。
11.floppy_init();//软盘初始化。
blk_dev[MAJOR_NR].request_fn = DEVICE_REQUEST;
设置软盘中断处理IDT项。
12.sti()开中断。
13.move_to_user_mode();移动到用户态执行。
这是个宏。由嵌入汇编代码组成。设置内核堆栈中的CS为任务0代码段(用户态),通过中断返回iret, 自动加载了LDT0的代码段到CS,数据段到SS,DS等,完成了从特权级从0跳到3。其实执行的代码在内存中的位置完全相同。只是完成执行权跳到用户态而已。这样,内核执行变成了任务0的执行。
14.fork();生成进程1,执行init();
这里的fork()是内联函数。为了不使用用户栈。
进程0从此死循环执行pause();
15 init();
进程1执行init()函数。
调用setup取硬盘分区信息hd.加载虚拟盘,进程init加载根文件系统,设置终端标准IO,创建进程2以/etc/rc为标准输入文件执行shell.完成rc文件中的命令。加载完根文件系统之后,整个OS就已经完整地运行起来了。
init等进程2退出,进入死循环:创建子进程,建立新会话,设置标准IO终端,以登录方式执行shell.,剩下的动作由用户来决定了。
(三)kernel:
<!--[if !vml]-->
<!--[endif]-->
图3
个人认为最主要的是中断代码,然后是中断代码会调用的通用代码。为什么这么说呢,无论是调度schedule,还是fork,都只有在用户进程执行int 0x80 中断进行系统调用或者是硬件中断才能进入内核代码,执行内核函数。当内核初始化结束后所有进程都是用户态进程,只有通过IDT表中定义的那些中断函数去执行内核代码。所以中断是OS的主线,只是在功能上分成了多个模块。
在traps.c中,设置了绝大多数中断向量,通过set_trap_gate()或者set_intr_gate设置对应IDT描述符。set_trap_gate()不会屏蔽中断,而set_intr_gate屏蔽外部中断,中断处理程序都是用汇编定义的,大部分在asm.s中定义,其余在system_call.s,keyboard.s,rs_io.s中定义。 汇编程序中再调用C语言程序做具体的处理。
比较重要的中断时钟中断int 0x20,系统调用中断int 0x80,页故障中断int14,还有一些外部设备如键盘,硬盘等也很重要,不过属于fs模块的内容。大多数异常只是简单调用sys_exit()结束当前进程,并重新调度其他进程schedule()。
从几个重要中断去中断执行流程去弄清OS怎么工作的:
1)int 0x20 时钟中断。
时钟是整个OS工作的心跳。8253每10ms产生一个中断。中断服务执行do_timer(),然后do_signal();
do_timer主要判断当前进程时间片是否用完,如果用完且处于用户态则执行schedule()重新调度。如果中断时当前进程正在内核态执行,则不能进行切换。也是说linux在内核态不支持任务抢占。这样使得内核的设计大大的简化了,因为除了进程自己放弃执行(如sleep,wait类)不用担心临界区资源竞争的问题。
如果当前进程是用户进程,判断当前信号位图中是否有未处理的信号,取最小信号然后调用do_signal()。这个函数想要执行用户定义的信号处理函数。
do_signal()把信号对应的处理函数插入到内核堆栈eip处,并修改用户堆栈使中断返回后用户进程执行信号处理函数,
信号处理函数返回后执行一个sa_restorer,恢复用户堆栈为正常中断退出之后的状态。(这是一个技巧,它实现了内核空间调用用户空间的函数!!!)
另外内核空间与用户空间数据交换默认通过fs来完成。
用户进程总是通过中断进入内核态,信号判断总是发生在时钟中断和系统调用中断处理之后。所以实时性也很强,因此称为软中断。
关于信号,在schedule()中,对当前系统中的所有进程alarm信号定时判断,可睡眠打断进程如果有未屏蔽信号置位唤醒(状态改为就绪)。
因此时钟,系统调用,以及最频繁调用的schedule()里面都会处理信号。因此信号总是可以及时地得到"触发"。
2)int 0x80 系统调用
系统调用的架构就是一个统一的中断入口和出口_system_call,保护现场,准备参数(最多三个),取调用号,调用系统调用函数列表中对应处理函数,多是名为sys_XXX()的C函数。C处理函数返回后的后期流程:
如果进程系统调用后状态不为就绪态或者时间片用完,执行调度schedule();判断中断前是用户进程且有未处理的信号?执行do_signal(),中断返回。
最重要的系统调用莫过于fork()和execve;
首先进程的重要组成部分:
任务数组task[],每个任务占一项(假定序号为nr),每个虚拟地址空间都是64M, 范围从nr*64M到(nr+1)*64M-1 ,在页目录表中最多占16项,每项对应一个页表即4M空间。进程任务数据结构task和内核栈共用一页空间,内核栈顶在页空间末端,task数据在页起始端。
进程的页表占用的页需要通过内存管理提供的接口get_free_page()来申请。 每个进程在GDT表中占用两个描述符项,LDT(nr)和TSS(nr)。
fork()流程:
调用find_empty_process()找一个空闲的进程任务task[]下标即任务号nr,并取得一个不重复的pid.
调用copy_process(...),里面一堆参数都是系统栈中保存的全部内容。(汇编和C混合编程技巧!)。copy_process 向mm申请一页内存保存task数据和设置内核堆栈。把父进程也就是当前进程的task数据全部拷贝,然后修改。
设置tss内容,(需要修改的主要是ss0=内核数据段,esp0=申请的页底部,eax=0)。
copy_mem拷贝进程空间。注意任务号nr意义在于进程的虚拟地址空间在nr*64M~(nr+1)*64M范围内。copy_mem先计算子进程虚拟地址空间基址和父进程空间大小,设置子进程LDT中的代码段和数据段描述符基址和段限。调用copy_page_tables复制进程空间。copy_page_tables就是把父进程占用的页目录项和全部页表中指定的有效的物理页面全部拷贝到子进程的页目录项和页表中去。同时把父子进程的页表设为共享的也就是只读的,一旦任意一个进程执行写内存操作,将发生页错误中断。这个中断将导致系统为进程重新分配可写的内存页。copy_page_tables先计算父子进程虚拟地址空间占用的目录项(16个最多)开始地址,对每个有效的目录项先为子进程分配一个页面作为页表,然后对该目录项下所有有效的页表项进行复制。同时把r/w位都置0。把对应物理页的mem_map[]加1。这样做非常高效而且非常巧妙。最大限度地共享了本身就只读或者不需要再写的页面。每当进程和内核之间要交换数据时尤其是内核向进程空间写数据时总是要先验证进程给的线性地址是否有效。如verify_area,write_verify..这两个函数最终会调用un_wp_page,取消页面的写保护。对mem_map[]=1的直接置r/w为1,mem_map[]>1表明页面共享了,内存页映射表mem_map[]-1然后申请空闲物理页,设置到页表项中,并复制页面copy_page。可见,父子进程先写进程者将申请空闲页并拷贝页面内容,另一个则可以直接使用原来的页面,因为这时mem_map[]=1了。
进程空间拷贝完毕之后,再设置一些task结构数据。给GDT表填加两项LDT(nr),TSS(nr).进程状态设为就绪,等待被调度就OK了。。
这就是所谓的写时复制,太神奇了。。
execve提供了需求加载的机制。
它加载一个程序文件到进程中执行,因此把原来进程拥有的页表项和页表全部释放掉。同时分配一页内存存放参数。
根据可执行文件头把进程任务数据结构task[nr]所有数据都设置好,但是并不加载一页代码数据。所以整个进程就是一副空架子。
从进程空间的第一条语句开始执行就会产生中断,然后根据PC的值从外设中加载所在页到内存中。这个中断将执行do_no_page.
这个函数在fs模块中定义,在fs模块中再仔细分析。
3)缺页中断int14
这个中断是十分有用的,它实现写时复制。fork和execve没做完的事情都会由这个中断提供的功能来了结。
中断错误号为出错页表项的最后3位。根据P位0或1判断是缺页中断或写保护中断。
缺页中断调用do_no_page,写保护调用do_wp_page.
do_wp_page提供写时复制机制,
取消页面保护(对于主内存区而言),页面不是共享状态,即mem_map[]=1,则置r/w=1返回。
如果页面是共享状态(mem_map[]>1),mem_map[]--,申请一页内存,并拷贝,映射到进程空间。
do_no_page提供的需求加载机制。
CR2提供发生错误时的线性地址。如果当前进程没有可执行文件且该地址比数据段末地址大,这可能是因为堆栈伸长引起的,直接申请一页内存映射到该线性地址所在页。
否则尝试页面共享,即如果有执行文件而且其inode使用计数>1,表明系统中可能有进程也在执行这个程序,这样可以查找到这个进程并把其对应地址处的页面共享到自己空间,也就是修改这两个进程对应的页表项。而且是共享方式,所以只能读不能写,如果有一个进程要执行写,则会引起写保护中断,系统再给写的进程另外再分配内存页并拷贝一页内容。如果尝试页面共享失败,没办法只得从外设中加载,找到可执行文件的inode.计算要读的逻辑块号(注意第一块是文件头),读一页(4块)到内存。分配页面,复制缓冲中的4块数据,把页面映射到进程空间引起中断的线性地址处。
(四)mm内存管理
linux的mm虽然只有两个文件memory.c和page.s,但是内容却很不简单。必须对分页机制有很好的理解才能读明白。
这个版本的内核每个进程虚拟空间64M,共支持4G/64M=64的任务数。所有进程共用一个页目录,但是却有自己的页表。
对虚拟地址的划分使得在页目录中也存在划分。每个进程虚拟空间最大占用16个目录项,每个目录项指向一个页表(1024个内存页),对应4M空间。
线性地址分三段,每段都是一个索引index或者叫偏移(offset),第一段索引是在页目录(基址在CR3)中找到页目录项,页目录项里保存的是一张页表的基地址。以线性地址的第二段为索引加上这个基地址,得到的页表项保存的是实际内存页的起始地址。再加上线性地址第三段为偏移,得到线性地址映射的实际物理地址。
内存管理提供的功能主要有管理页面,操作进程空间,缺页中断处理(写时复制,需求加载),共享内存页。其中大多数函数都会访问页目录和页表,都使用上述的计算的原理。
内存管理mm和内核kernel两部分代码联系十分密切
内存管理提供的主要的功能函数可以分为
1管理页面 :取一个空闲页get_free_page,释放一页free_page.
2操作进程空间:free_page_tables释放进程页目录和页表
copy_page_tables在进程空间之间复制页目录和页表。主要提供给fork()使用,实现写时分配。
put_page 把一页内存映射到进程空间中去。
write_verify进程空间有效性验证,当内核向用户空间写数据之前必须进行验证。为可能为无效的地址区域分配页面
3页面共享&页故障中断:
try_to_share 尝试在打开文件表中找当前执行程序inode,已经存在的话就查找所有进程中executalbe与当前进程相同的任务。有则尝试共享对应地址的映射的物理页面。即添加到自己相应位置的页表项中去。(share_page)
do_no_page 缺页中断。判断地址是否超出end_data,是则可能是堆栈伸长,分配页面到相应位置(get_free_page,put_page),否则表示地址在可执行文件内部,先尝试共享,不成功则从线性地址计算需加载部分在文件上内部的块号,通过bmap把文件内部块号映射的设备逻辑块号计算出来。申请空闲页并通过bread_page读取一页,最近由put_page把这页映射到发生中断的进程页面上。
un_wp_page在写保护中断中调用,取消页表保护,实现写时复制。
(五)文件系统模块fs:
1.总体结构:
Linux把所有设备都做为文件来看待。提供统一的打开,关闭,读写系统调用接口。 下面是文件系统层次关系:
<!--[if !vml]--> <!--[endif]-->
<!--[endif]-->
图4
总体来说,文件系统提供两类外部接口(系统调用),文件读写和文件管理控制。
上图中Read_write代表的是文件读写系统调用接口read,wirte。它根据操作文件的类型分别调用了四种读写函数:
字符型文件tty_read,tty_write,在kernel/chr_drv驱动模块中定义;
FIFO文件 pipe_read,pipe_write 都是内存操作。Fs/pipe.c中定义
block_dev块设备文件 :block_read,block_wirte,间接调用bread。
File_dev 常规文件。File_read,file_write, 涉及的内容是fs主要的内容。
图中Open stat fcntl 则是文件系统的系统管理控制接口如创建打开关闭,状态访问修改功能。这主要针对常规文件,如根文件系统下的全部文件。这些都需要底层文件系统函数支持,主要包括文件系统超级块,i结点位图和逻辑块位图,i结点,文件名解析等操作。而这些底层文件系统函数则建立于buffer提供的缓冲管理机制之上。这些是对上图的大体归纳吧!
在上面总结kernel的时候,没有提及blk_drv和chr_drv,因为我觉得把它们放在文件系统里面来更合适。
Blk_drv目录是块设备驱动代码。实现了HD(硬盘),FD(软盘),RD(Ramdisk)三种块设备的底层驱动,并提供一个外部调用的接口ll_rw_block(dev,nr)。就是上图中右下虚框示意的层次上。
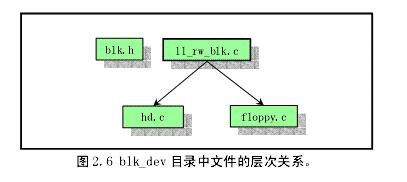
图5
同样的,char_drv实现了字符设备(串行终端)的驱动,包括控制台(键盘屏幕),两个串口。实现供上层调用的读写接口read_tty , write_tty。下面是源码关系图:
<!--[if !vml]--><!--[endif]-->
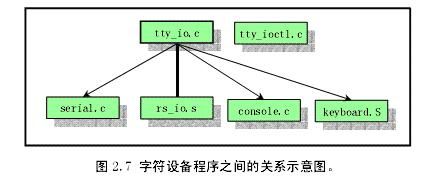 图6
图6
2下面分别从从底层向高层总结一下各个层次中源码实现的主要细节:
2.1 块设备驱动部分 kernel/blk_drv
块设备工作流程(粗略):
1)文件设备接口调用底层块设备读写函数ll_rw_block(int rw,buffer_head *bh).这里bh要读的设备号,块号,已经写入bh, rw是读或者写指令
2)ll_rw_block(int rw,buffer_head *bh)取主设备号major,调用make_request(major,rw,bh);
3)make_request(major,rw,bh)申请一个请求项,根据rw和bh相应设置填充req各字段值, 并调用add_request (major + blk_dev, req)插入到设备major的请求队列。
4)add_request (major + blk_dev, req)检查设备等待队列是否为空,为空则把req添加到队列中并马上调用设备的请求执行函数。
对于硬盘,这个函数就是do_hd_request,它将根据请求项的各个字段设置向硬盘发出相应的命令. 如果请求队列不为空,则按照电梯算法把req加到队列中。
ll_rw_block函数返回。
整个ll_rw_block()返回到上层调用(缓冲管理部分buffer.c)。然后调用进程将执行等待wait_on_buffer(bh);进程切换。
硬盘接受命令后,完成req要求的读/写一个扇区后将发出中断。hd_interrupt(定义于kernel/system_call.s)被执行。调用_do_hd。do_hd是设备当前要调用的中断处理函数的指针。根据当前请求,do_hd_request在调用hd_out向硬盘控制器发命令(如读写或复位等)时根据命令类型指定do_hd为read_intr, write_intr或其它。如果为读,do_hd=read_intr。写则do_hd=write_intr.
read_intr 将判断当前请求项请求读的扇区数是否已经全部读完,如果没有,再次设置do_hd=read_intr,然后返回。如果全部完成,则调用end_request(1)去唤醒等待的进程。然后调用do_hd_request去处理其余请求项。
write_intr 将判断当前请求项请求写的扇区数是否已经写完,如果没有,把一扇区数据复制到硬盘缓冲区内,然后再次设置do_hd=write_intr并返回。如果写完,则调用end_request(1),更新并有效缓存块,然后调用do_hd_request去处理其余请求项。
整个硬盘读写流程如下 :
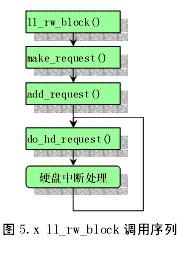
图7
对于软盘,大体的流程差不多。只是软盘有启动马达等延时写时操作,比较琐碎一些。
对于ramdisk,速度很快所以不需要中断机制,当然请求队列也最多只有当前一个。像上面的过程一样,make_request会调用add_request,而由于前面的请求队列一定为空,所以会马上执行do_rd_request. 在do_rd_request中直接读、写数据。然后就end_request(1).
2.2 字符设备驱动 kernel/chr_drv
串行/字符设备在linux下叫TTY,每个TTY对就一个tty_struct结构。0.11版本一共三个,一个控制台两个串口。每个tty_struct有三个缓冲区,read_q, write_q, secondary 。
read_q保存原始的输入字符队列,write_q保存的是输出的字符队列,secondary里面是输入字符序列通过行规则处理后的字符序列。
tty_struct中的termios保存的是终端IO属性等。这个结构通过tty_ioctl.c中tty_ioctl()来对tty进行相应的控制或设置。
避开非常琐碎的行规则,从char_dev.c中函数rw_tty调用来看整个过程的粗略脉络。 rw_tty(int rw,unsigned minor,char * buf,int count, off_t * pos)。检测进程有无终端,有则根据rw调用tty_read 或者tty_write.
先看tty_read(minor,buf,count),对于要求读取的字节数nr,在定时时间内,循环读取secondary中的字符,直到读到nr个为止。如果secondary空了, 进程等待于secondary的等待队列上。如果超时,则返回。
再看tty_write(minor,buf,count),如是tty写缓冲write_q已经满了,睡眠sleep_if_full (&tty->write_q); 对于要求写字节数nr,循环拷贝到write_q中去。如果拷贝过程中write_q满了或者已经拷贝完调用写函数。没拷贝完则切换进程。剩下的工作交给中断处理程序去完成。
对于读操作,当tty收到一个字符,比如串口收到一个字符或者是用户按下键盘,系统将进入相应中断程序。中断程序对收到的字符进行处理,然后把字符放入对应tty的read_q中,调用do_tty_interrupt,do_tty_interrupt直接调用copy_to_cooked(tty). copy_to_cooked(tty)把read_q的全部字符通过行规则处理。然后放到secondary队列中去。如果tty回显标志置位,则把转换后的字符也放到写队列write_q中,并调用tty->write (tty); 如果中ISIG 标志置位,收到INTR、QUIT、SUSP 或DSUSP 字符时,需要为进程产生相应的信号。最后唤醒等待该辅助缓冲队列的进程(如果有的话)。wake_up (&tty->secondary.proc_list); 中断返回。
对于写操作,如果tty是控制台,其tty写操作为con_write (tty),这个函数直接把write_q中所有字符按照格式写到显存中去或者调整光标。如果是串口,tty写操作为rs_write(tty);这个函数更简单,打开串口发送缓冲空闲允许中断位就返回。这样,CPU会马上收到一个中断,在中断程序中,写操作才会真正进行。串口写缓冲空中断执行时先判断写队列是否为空,如果为空,唤醒可能的等待队列,并且禁止发送缓冲空中断允许并中断返回。如果不空,但是写队列字符数小于256,也唤醒可能的写等待队列,然后从写队列中取一个字符写入串口发送寄存器。中断返回。
2.3文件系统之缓冲管理fs/buffer.c
缓冲管理部分两个作用,利用cache机制提供更高效的使用外部块设备,给使用块设备的其它程序提供简单的接口如bread。使得上层程序对设备操作全部变成对缓冲块的操作。给块设备如软硬盘提供一种cache机制。每个缓冲块buffer_head都对应一个设备dev和逻辑块号block,引用计数count,修改标志dirt,有效标志uptodate。 类比CPU,修改标志与有效标志是cache机制必需的,而dev和block号则相当于地址。缓冲管理负责设备数据块与缓冲映射块数据一致性。缓冲管理具体去调用设备驱动程序ll_rw_block().
Buffer.c主要提供的函数有申请、释放缓存,同步(buffer与设备内容一致),读取。而写操作则总是在缓冲不足的情况下利用同步进行的。读取的时候总是根据给定的dev和block先查找当前缓存中是否存在有效的对应块,如果存在就不再访问设备。否则取一个空闲缓冲,调用设备驱动ll_rw_block。
缓冲块链表实现了hash链表和LRU算法,所有的缓冲块都连接于链表中,链表头总是空闲度最高的缓冲块,链表尾则是最近刚申请的块。查找空闲缓冲从头开始比较空闲度,找最大的。这就实现了LRU算法。 所有具有相同hash值的缓冲块连接于同一个hash_table[nr]项上。nr值由设备号和块号经过一个hash算法得到。这样查找速度会快好多倍。
所有对外设逻辑块的读写都在这里被转化为对缓冲块的读写。每次读写前总是先根据设备号和逻辑块号到hash_table[]表中查找hash链表,若已经存在且有效,则直接对缓冲读写。写后要置修改标志dirt。这样当执行同步操作,或者getblk()找不到干净的空闲块的时候会把所有dirt为1的未被占用(count=0)的缓冲块写入磁盘。
2.4 文件系统之文件系统底层操作。
文件底层操作。(bitmap.c,inode.c,namei.c,super.c,truncate.c,)这部分按照文件系统对硬盘等块设备的使用规则,实现了相应规则的操作函数。文件系统把块设备按逻辑块管理,功能划分:
| 引导块 |
超级块 |
i结点位图块区 |
逻辑块位图块区 |
i结点块区 |
数据块区 |
超级块指明了整个文件系统各区段的信息。两个位图区分别指示i结点区和数据块区的占用和空闲状况,i结点区中每个i结点都代表一个文件或者目录。整个文件系统的根目录在第1个i结点处。通过它可以找出任何路径下的文件的i结点。
i结点指示一个文件或者目录,一个i结点的内容主要是文件占用的数据块号。直接块号,一、二次间接块号提供了灵活的机制来线性地查找文件中一个数据块对应在哪一个具体的物理块上。目录文件的数据块内容是目录项,它包含的所在目录的全部文件和子目录的信息。每个目录项保存一个文件或者子目录的inode号和文件名。
相应地,bitmap.c提供了i结点位图,数据块位图的占用和释放操作。super.c实现对超级块的读定安装卸载操作。inode.c实现是获取指定nr的inode(iget(dev,nr)),写回inode ( iput(inode) )等操作。
namei.c则实现了按照文件名来获取inode的操作。从而提供了通过文件名来管理文件(inode)的方法。
这些操作之间的层次并不十分清晰,相互调用很多。注意块设备是按块为最小单位访问的,这些操作不过是按照文件系统对设备块使用的定义对各个块以及块中的数据做解析和操作罢了。文件底层操作都貌似在访问块设备,但是却仅仅调用了缓冲管理提供的接口。它们操作了内存。缓冲管理去实现设备的读写。比如在系统安装根文件系统的时候,超级块已经读如缓冲,根据超级块的信息,将i结点位图块,逻辑位图块读入到内存缓冲中了。
下面对各个源文件的实现进行小结:
bitmap.c: 位图操作,主要提供文件系统中i结点位图,逻辑块位图相关操作,包括申请和释放inode,申请和释放block.首先文件系统的位图块在mount_root中已经缓存到buffer中,缓冲块指针由超级块s_zmap[],s_imap[]指向。所以申请释放操作主要的一部分------对位图相应位置位或者复位就变成对缓冲块置位复位了,然后修改标志dirt=1就行了。
new_block除了要对找到的空闲位置位外,还要申请一块空闲缓冲(清0)并填申请块的dev和block。置有效和修改标志。这么做其实就等于一个写操作,即把申请的设备块清0。(当然,可能申请后马上就要写这一块,所以这么做最高效了。)
truncate.c: 对文件(inode)长度清0。主要调用free_block对位图进行操作。直接块直接释放,对一次间接块上所有有效块号释放,然后再释放一次间接块。二次间接块同理。
inode.c: 主要提供三个函数,iget,iput,bmap. iget是获取指定设备和i结点号的内存i结点。使用计数加1。主要调用read_inode(调用buffer管理部分) ;iput是把一个内存i节点写回到设备中去。使用计数减1。主要调用write_inode(调用buffer管理部分)
bmap是把文件块号对应到设备块号(逻辑块号)中去。文件块号是按直接块,一直间接,二次间接顺序计算的索引。逻辑块号则是保存在它们里面的块号。有点像页表,页的线性地址对应文件块号,页的物理地址对应逻辑块号。页表项中的保存的地址就是页物理地址。bmap有创建和不创建两种方式。创建时会根据文件块号给文件(inode)申请逻辑块存放可能需要的一、二次间接块和数据块。
super.c:对文件系统超级块的相关操作。如get_super,put_super,read_super,sys_mount,sys_umount;超级块对应一个文件系统。
get_super(dev)在系统超级块数组中查找并返回匹配的超级块。
put_super(dev)释放超级块数组中超级块信息,并释放超级块i结点,逻辑块位图占用的缓冲区。
read_super(dev)先在超级块数组中查找,有直接返回,没有则先在超级块数组找一空闲项。读dev 1号块,取得超级块信息,如位图占多少块,再读位图块(i位图,逻辑块位图)到缓冲中。设置完毕返回。
sys_mount(devname,dirname,rw_flag) 在目录dirname上安装devname设备的文件系统。取dirname和devname的i结点判断二者都有效?然后读dev超级块read_super(dev),置超级块安装结点为direname的i结点 sb->s_imount=dir_i. 置目录i结点安装标志1。所以i结点的安装标志表明该目录是否安装了一个文件系统。而要知道安装的文件系统的具体信息则要查找超级块数组,看看哪一个超级块的s_imount等于该i结点。。。
namei.c:提供文件路径名到i结点的操作。大部函数参数都直接给出文件路径名,所以它实现了通过文件名来管理文件系统的接口。如打开创建删除文件、目录,创建删除文件硬连接等。
大部分函数的原理都差不多:调用get_dir取得文件最后一层目录的i结点dir。如果是查找就调用find_entry从dir的数据块中查找匹配文件名字符串的目录项。这样通过目录项就取得了文件的i结点。如果是创建(sys_mknod)就申请一个空的inode,在dir的数据块中找一个空闲的目录项,把文件名和inode号填入目录项。创建目录的时候要特殊一些,要为目录申请一个数据块,至少填两个目录项,.和.. (sys_mkdir)。
删除文件和目录的时候把要释放i结点并删除所在目录的数据块中占用的目录项。
打开函数open_namei()基本上实现了open()的绝大部分功能。它先按照上述过程通过文件路径名查找 最后一层目录i结点,在目录数据块中查找目录顶。如果没找到且有创建标志,则创建新文件,申请一个空闲的inode和目录项进行设置。 对于得到的文件inode,根据打开选项进行相应处理。成功则通过调用参数返回inode指针。
这个文件用得最多的功能函数莫过于namei();根据文件名返回i节点。
这里任何对inode的操作都是通过iget,iput这类更底层的函数去实现,iget和iput所在的层次基于buffer管理和内存inode表的操作之上。
2.5 文件系统之文件数据访问操作 这提供读写系统调用接口read,write。
主要包括文件:
block_dev.c:定义了块设备文件的读写函数,block_write,block_read.
file_dev.c :定义正规文件读写函数。file_read, file_write
pipe.c :定义FIFO文件读写及管道系统调用。read_pipe, write_pipe, sys_pipe
char_dev.c :定义字符型设备访问读写,rw_ttyx, rw_tty, rw_char. 最终都调用tty_read,tty_write
read_write.c:实现文件系统读写接口 read,write,lseek。
read,write的参数是文件句柄fd,这需要通过系统调用sys_open来获取。函数根据进程task的filp[fd]指向的系统打开文件表项获取inode、读写权限、当前读写位置等。由inode的类型(上面四种之一)调用相应读写函数(参看图4)。对于正规文件,过程如下:由inode指向的内存inode项获取文件在设备上的位置大小等信息。通过inode和bmap计算要读取的文件数据在设备的逻辑块号。通过bread读数据块,然后对缓冲块进行读写。到此就不用管了。缓冲管理的作用真的是太神奇了。
2.6 文件系统高层操作&管理部分:
包括文件open.c,exec.c,stat.c,fcntl.c,ioctl.c 实现文件系统中对文件的管理和操作,如创建,打开,设置/读取文件信息,执行一个文件程序。这个层次位于文件底层操作之上,调用底层函数去实现。
open.c: 定义了系统调用sys_ustat,sys_access,sys_chmod,sys_chdir,sys_chroot,sys_open,sys_close.参数基本上是文件名或者文件句柄。
可以分为三类:修改inode属性类(前3个),修改进程根/当前目录,打开关闭文件。
第一类通过namei找到i结点,修改相关属性域,iput写回设备。
第二类通过namei找到i结点,把进程task数据相应域设为对应inode.
第三类打开时主要调用open_namei返回一个文件名对应的i结点,并设置系统打开文件表和进程打开文件表。返回文件句柄。关闭则清进程打开文件表项,处理对应的系统打开文件表项(引用减1),写回i结点。
execv.c:主要一个函数do_execve.往往在系统执行完fork之后会调用execve簇函数去执行一个全新的程序。必须重新对进程空间进行初始化。
主要流程:找到执行程序inode,进行相应判断(如如权限等),读文件头(第1个数据块)信息。
如果是脚本文件,则取shell文件名和参数,以shell为执行程序去执行该脚本文件,这时重新以shell为文件名,以本脚本文件为参数,执行上述过程。
根据文件头信息得到文件各段长度,entry位置,修改进程任务结构中相应的数据。然后拷贝参数到进程空间末端,设置堆栈指针。
清空原进程空间占用的页目录和页表。 修改系统调用返回地址为进程空间的起始地址。
该系统调用返回后,新进程执行第一条语句,会引起一个缺页中断。根据要求的线性地址和executable,在中断中执行do_no_page进行共享或者需求加载。
stat.c : 系统调用sys_stat,sys_fstat.取文件状态信息。
fcntl.c: 实现sys_dup,sys_dup2,sys_fcntl.
dup复制到从0开始找最小的空闲句柄。
dup2指定开始搜索的最小句柄。
fcntl主要根据flag参数不同。可以实现四方面的操作:复制文件句柄同dup,设/取close_on_exec标志。设/取文件状态和访问模式。给文件上/解锁。
ioctl.c:主要实现系统调用sys_ioctl,间接调用tty_ioctl.主要对终端设备进行命令控制、参数设置、状态读取等。
结束.
看这本书的剖析的linux代码之前觉得LINUX很神秘,现在觉得亲切多了。心里面对内核的动作已经有了比较清晰的概念。但是还远远不足以运用到嵌入式中去,最新的内核与0.11相比,我觉得好像自己还是啥也不知道一样,差得太多,显得很陌生。下一步必须看看2.6版本的内核分析一类的书籍,了解最新的内核。