IBM InfoSphere DataStage 8.1 DataStage Job 开发详解
简介
DataStage 使用了 Client-Server 架构,服务器端存储所有的项目和元数据,客户端 DataStage Designer 为整个 ETL 过程提供了一个图形化的开发环境,用所见即所得的方式设计数据的抽取清洗转换整合和加载的过程。Datastage 的可运行单元是 Datastage Job ,用户在 Designer 中对 Datastage Job 的进行设计和开发。Datastage 中的 Job 分为 Server Job, Parallel Job 和 Mainframe Job ,其中 Mainframe Job 专供大型机上用,常用到的 Job 为 Server Job 和 Parallel Job 。本文将介绍如何使用 Server Job 和 Parallel Job 进行 ETL 开发。
Server Job
一个 Job 就是一个 Datastage 的可运行单元。Server Job 是最简单常用的 Job 类型,它使用拖拽的方式将基本的设计单元 -Stage 拖拽到工作区中,并通过连线的方式代表数据的流向。通过 Server Job,可以实现以下功能。
- 定义数据如何抽取
- 定义数据流程
- 定义数据的集合
- 定义数据的转换
- 定义数据的约束条件
- 定义数据的聚载
- 定义数据的写入
Parallel Job
Server Job 简单而强大,适合快速开发 ETL 流程。Parallel Job 与 Server Job 的不同点在于其提供了并行机制,在支持多节点的情况下可以迅速提高数据处理效率。Parallel Job 中包含更多的 Stage 并用于不同的需求,每种 Stage 使用上的限制也往往大于 Server Job。
Sequence Job
Sequence Job 用于 Job 之间的协同控制,使用图形化的方式来将多个 Job 汇集在一起,并指定了 Job 之间的执行顺序,逻辑关系和出错处理等。
数据源的连接
DataStage 能够直接连接非常多的数据源,应用范围非常大,可连接的数据源包括:
- 文本文件
- XML 文件
- 企业应用程序,比如 SAP 、PeopleSoft 、Siebel 、Oracle Application
- 几乎所有的数据库系统,比如 DB2 、Oracle 、SQL Server 、Sybase ASE/IQ 、Teradata 、Informix 以及可通过 ODBC 连接的数据库等
- Web Services
- SAS 、WebSphere MQ
回页首
Server Job
Server Job 中的 Stage 综述
Stage 是构成 Datastage Job 的基本元素,在 Server Job 中,Stage 可分为以下五种:
- General
- Database
- File
- Processing
- Real Time
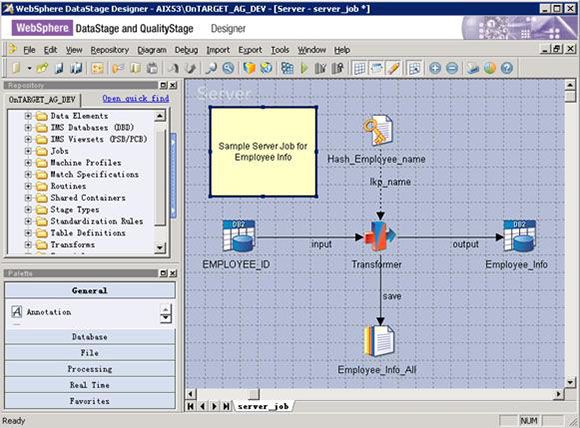
本节中将介绍如何使用 Datastage 开发一个 Server Job。如图 1 所示:
图 1. Server Job
Sequential File Stage
Sequential File Stage 可用来从一个 Sequential 文件中获取源数据或将数据加载到一个 Sequential 文件中。在使用 Sequential File Stage 时需要指定文件的路径和名称,文件的格式,列的定义和文件写入的类型(覆盖或追加)。
图 2. Sequential File 属性框

图 3. Sequential File 列定义

上图是本节例子中使用到的 Sequence File。在 Input 页中,File Name 参数代表文件的实际路径,如果文件不存在将会被自动建立。Update Action 中选择 Overwrite existing file 表示此文件在加载数据之前将被清空;在 Format 页中,定义文件的格式,例如分隔符,NULL 值,首行是否为列定义等;在 Column 页中,需要输入文件的列定义。
Hash File Stage
Hash File 以主键将记录分成一个或多个部分的文件,在 Datastage 中通常被用做参考查找。在进行参考查找的时候,Hash File 文件会被加载到内存中,因此具有较高的查找效率。
和 Sequence File 类似,使用 Hash File 时需要输入文件的实际地址,通过参数设置写入时的选项,并提供数据的列定义。需要注意的是,Hash File 需要指定主键,如果未指定,第一列被默认为主键。进行参数查找时,使用主键值在 Hash File 中搜索,如果找到则返回该数据,如果未找到则返回 NULL 值。
图 4. Hash File 属性框

Transformer Stage
Transformer Stage 是一个重要的,功能强大的 Stage。它负责 ETL 过程中的数据转换操作。在 Transformer Stage 中可以指定数据的来源和目的地,匹配对应输入字段和输出字段,并指定转换规则和约束条件。
图 5. Transformer Stage 列映射

Transformer Stage 中分为 5 个区域:
左上方区域,是用表格形式描述的输入数据信息。 如果有多条输入数据流,则有很多表格。本例中有一个输入,一个参照查询,因此左上方有两个表格。
右上方区域,是用表格形式描述的输出信息。
左下方区域为输入的元数据列定义,包括列名,类型和长度等属性。
右下方区域为输出的元数据列定义,包括列名,类型和长度等属性。
左上方和右上方的表格由带有流向的箭头连接,代表了字段的对应关系。此例中,输入的数据只有一个字段 EMPLOYEE_ID,通过此字段在 Hash File 中进行参照查找,获取 EMPLOYEE_NAME 字段。如果在 Hash File 中找到了 EMPLOYEE_NAME 则将数据发送到输出端,这个条件是通过 Transformer Stage 提高的约束功能实现,我们在约束中的定义为 NOT(ISNULL(lkp_name.EMPLOYEE_ID))。另外无论是否在 Hash File 中查找到对应的数据,我们都将数据记录到一个 csv 文件中,即对应的 save_all 输出。
回页首
Parallel Job
Parallel Job 的 Stage 综述
与 Server job 相比,Parallel Job 提供了更丰富的 stage,增加了 Development/Debug,Restructure 和 Transactional 类的 stage。同时,对于一些在 server job 中可以在 transformer 中完成的功能,Parallel job 也提供了专用的 stage 以提高运行性能和开发效率,比如 lookup,join,Compare 等。另外一个显著的区别是在 Parallel Job 中内置地支持 job 的并行运行,并行执行也就意味着数据在 job 中的各个 stage 见处理时需要处理 partition 和 combination 的问题,所以在开发 job 时,我们需要设定 partition 和 combination 的策略。
Lookup DataSet 与 Lookup Stage
Parallel Job 对 lookup 的实现做了一些调整,在 Server Job 中,我们一般是用 Transformer Stage 配合 lookup 数据源(一般是 hash 文件)来实现 lookup,同一个 transformer 中可以同时完成多个 lookup,类似于 sql 中的多表自然联接,如果 lookup 数据源使用的是 database stage 而不是 hash file 而且对于一条记录返回多条 lookup data 的话,job 会产生 warning(hash file 的键唯一特性使得它不会存在这个问题,后面插入的重复数据会覆盖前面的同主键的数据)。
而在 Parallel Job 中,lookup 需要用一个单独的 stage 来实现,transformer 不再兼职 lookup 的“副业”,在一个 lookup stage 中,可以有一个主数据 link 和多个 lookup link。同时,Parallel 中的 lookup 还有以下的新特性
- 支持 multi rows,在一个 lookup stage 中对于一行主输入数据可以有一个 lookup link 返回多于一行的 lookup 数据。结果也会变成多行。
- Parallel 中不在支持 hash file,转而使用封装更强的 Data Set stage, Data Set 本质上也是 hash 数据结构,但对 Job 开发人员隐藏了实现细节,我们不用象开发 Server Job 那样去手动设定详细参数
- Parallel 中除了支持等值 lookup 外,还直接支持 Range lookup 和 Caseless lookup。这样我们在完成类似月份转换为季度性质的设计时就会非常的方便和自然。
类似于 Server Job 中的 hash 文件,在 Parallel Job 中我们使用 Data Set 文件来缓存 lookup 数据,并加载到内存中,在 Data Set stage 中,我们只需要制定记录的主键和存储的文件名,Parallel 引擎会为我们处理其他的操作。但为了达到性能的最优化,我们有时需要制定 Data Set 的缓存策略和缓存大小,系统默认的缓存大小是 3M,如果我们的 lookup 数据比较大,就需要设定合适的缓存大小,否则会严重影响 lookup 的性能。
图 6. DataSet 缓存设置

Sort Stage
Parallel Sort stage 的行为类似于 Sql 中的 order by,但是比 order by 提供了更多的选项。在 job 中,Sort stage 接收一个输入 link 并产生一个输出 link。对于写过 sql order by 或者排序程序的开发人员使用 Sort Stage 的基本功能应该是很简单的,但是要充分发挥 Parallel stage 的强大功能,我们还是需要注意下面几点:
- 并行还是串行执行,如果选择串行执行,那么 Sort stage 的行为就类似于 Server Job 中的 Sort Stage,整个输入数据都会按照设定的排序选项排序,但如果选择分区 / 并行排序,则只有每个分区内的输出是有序的,这在有些情况下是可以接受的,但在另外一些情况下会导致代码缺陷,需要根据 sort 的后续操作做出选择。
- 如果有可能,尽量在数据源端的数据库中进行排序,这样不但会提高数据排序的效率,还能大大减少 job 对内存,I/O 的压力。Sort stage 只有在接收完输入之后才能完成排序,进而输出数据,使得 job 的后续 stage 都处于等待状态。
- 类似于 order by 后面的字段列表,我们可以指定排序的方向,是升序还是降序,Sort Stage 也可以指定对多个字段进行排序,排在前面的 column 称为主排序字段,如果排序字段中有某一个或几个字段已经是有序的,我么也可以指定其为有序,这样在排序的时候就可以提高排序的效率。
- 稳定排序(stable sort)/ 允许重复,stable sort 默认是 yes,这样如果两条记录 sort key 相同的话,排序的输出和输入顺序将是相同的,如果没有选择允许重复,两条或者多条记录的 sort key 相同的话,将只保留一条记录。
- 限制内存的使用,数据的排序操作是非常耗费内存的,如果不加限制,让所有的数据的排序都在内存中完成的话,job 的其他操作或者其他 job 的执行的效率将受到严重影响,所有在 Sort Stage 中,我们可以设定此排序可以使用的最大内存数(M),这样我们在可以接受的排序效率和使用的内存数量之间找到平衡点。
Compare/Difference/Change Capture Stage
Compare, Difference 和 Change Capture Stage 是 Parallel job 中三个用于比较数据集合异同的 stage,对于这三个 stage 本身的使用没有太多困难的地方,基本的参数和设置都很简明直观,我们的介绍主要集中在这三个 stage 在使用中的相同点和不同点上,一旦了解了这些 stage 的特点,使用的时候不但能根据需求选择正确的 stage,也能根据 stage 特性知道需要设置哪些参数。
相同点:
- 都有两个输入,产生一个输出,
- 输入的数据主键的字段名相同,都需要指定需要比较的字段。
- 产生的结果数据中都会增加一个整型的结果字段,用于表示两行数据的比较结果
不同点:
- Capture Change Stage 输出的是以 after 输入流为基础,外加 change code 字段,适合和 change apply 配合使用,把 before 输入流同步为和 after 一样。
- Difference Stage 的输出是以 before 输入流为基础,外加 change code 字段
- Compare Stage 产生的结果包括 before 和 after,以及 change code 字段
下面是一个 Capture Change Stage 的示例:
图 7. Capture Change Stage 的示例

Before source Sql: SELECT k,v FROM (values (1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10)) as temp(k,v) order by k asc After source Sql: SELECT k,v FROM (values (1,1),(2,2),(11,11),(4,5),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10)) as temp(k,v) order by k asc
图 8. Capture Change Stage 参数设置

从以上设置可以看到,我们选择了明确指定主键,剩余 column 都当作 value,对于比较的结果,如果结果相同,则从结果中删除,也就是我们只希望看到对 Before 数据做 Delete,Edit,和 insert 后产生的差异,下图是我们 job 运行得到的结果:
图 9. Comparsion 结果

从以上的结果可以看到,before 和 after 数据有三处差异,change_code 的值对应为 2,3,1。分别表示对 before 执行 Delete,Update,Insert 产生的差异。要同步这些差异,我们只需要对 before 数据执行相应的 Delete,Update 和 Insert 即可实现两个数据集合的同步。
Filter Stage
Filter Stage 顾名思义是一个用于过滤的 Stage,其作用类似于我们写 sql 中的 where 子句,而且其支持的逻辑表达式和运算符也类似于 sql 语句的 where 子句,比如,在 filter stage 中,我们可以使用以下常见的逻辑表达式和运算符以及其组合 ,
- true 和 false
- 六个比较运算符 : =, <>, <, >, <=, >=
- is null 和 is not null
- like 和 between
从其语法作用上看,则类似于 java 或者 C 语言中的 switch case 语句,我们可以通过设置“Output Row Only Once”选项的值来决定是否在每个 case when 子句后面是否添加 break,通过添加或者删除“Reject Link”来确定是否添加一个 default 子句 . 下面是一个简单的例子。展示了我们如何通过员工编号和薪水的组合条件来过滤员工的记录到不同的结果文件的。
图 10. Filter Stage 的示例

图 11. Filter Stage 的设置

对于每一个 where 条件,我们需要设置相应的输出链接,这是一个整型数字,我们可以在“Link Ordering”页签上找到输出链接的编号和名称之间的对应关系。
另外需要注意的一点是,Filter Stage 不对输入的记录做任何改动,只做分发。但是你可以手动设置输出的 column,使得每个输出的 column 列表不一样,但只要是输入 column 列表的子集即可,但是对于 Reject Link, Column 列表是默认完全等同于输入的,且不可更改。
用于调试的 Stages
我们知道 DataStage Server Job 中提供了 Debug 功能,我们在开发过程中遇到问题的时候可以让 Job 运行在 debug 模式下,仔细查看每行数据在 Job 中各个 Stage 之间的流动和转换情况,但 Parallel Job 并没有给我们提供调试功能,但 Parallel Job 用另外一种方式提供了调试的能力:Parallel Job 内置了用于调试的 Stage,使用这些 Stage,我们可以按照我们的需要,把我们怀疑有问题的中间数据输出,进而可以深入查找问题的根源。在 Parallel Job 中提供了以下的 Stage 用于调试:
- Head Stage
- Tail Stage
- Sample Stage
- Peek Stage
- Row Generator Stage
- Column Generator Stage
我们以一个 peek 的实例展示一下 development/debug Stage 的使用,其他的 Stage 的用法类似,可以参见后面的表格和文档。如下图是我们的 Job,DB2 Stage 的 Source Sql 如下:
SELECT k,v FROM (values (1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9), (10,10),(11,11),(12,12),(13,13),(14,14),(15,15),(16,16),(17,17),(18,18),(19,19),(20,20) ) as temp(k,v)
图 12. Peek Job 的示例
图 13. Peek Stage 的设置
图 14. Peek 的结果

下表简述了这些 Stage 的特点和用法
表 1. Stage 的特点和用法
| Stage 类型 | 用途 | 可设置项目 |
|---|---|---|
| Head Stage | 从头部开始抓取输入流的数据 一个输入一个输出 |
抓取的行数 从哪些分区抓取 每个分区的起始位置 每次抓取的间隔 |
| Tail Stage | 抓取输入流尾部的 N 行数据 一个输入一个输出 |
抓取的行数 从哪些分区抓取 |
| Sample Stage | 一个输入,多个输出根据设置的策略从输入流的各个分区抓取数据,每个输出流有不同的百分比设置 | 百分比 随机数的种子 每个分区抓取的最多行数 |
| Peek Stage | 从一个数据流中有选择地“偷窥”流经的数据,一个输入,两个输出,一个输出原样输出输入数据,一个输出生成一个文本,包含“偷窥到的数据” | 每次抓取的间隔 每个分区抓取的行数 “偷窥”哪些行 输出“偷窥”结果到 log 还是输出 |
| Row Generator Stage | 根据定义的数据 schema,生成模拟数据,无需输入,一个输出 | Schema(column list 或者 schema file) 生成的行数 |
| Column Generator Stage | 在一个输入流上添加新的 column,为这些新添加的或原有的 column 生成模拟数据 | 需要生成模拟数据的 column |
回页首
Sequence Job
如果说每个个 Server Job 或 Parallel Job 完成 ETL 流程中的一个数据抽取,转换,加载的子过程的话,那么 Sequence Job 的作用就是把这些子过程给串联起来,形成一个完整的全局的 ETL 过程。从结构上看,一个 Sequence Job 类似于一个 C 或者 Java 语言的一个函数,但功能更为强大。
- 可以使用 UserVariables Activity Stage 定义局部变量,变量在定义的时候需要赋值,赋值表达式可以是系统变量,Job 参数,Datastage 的宏,常量,Routine 的返回结果等,还可以是这些单独变量的条件,数学或者字符串运算后的结果。几乎你在一个函数中能完成的局部变量定义的功能这儿都能实现。下面的示例定义了六个变量。
- 可以调用其他的功能模块,通过 Job Activity Stage 可以调用 Server Job,Parallel Job;通过 Execute Command Stage 调用 unix/windows cmd,通过 Routine Activity 支持调用 datastage routine。
- 支持循环,Sequence Job 通过 StartLoop Activity Stage 和 EndLoop Activity Stage 提供了循环的功能。循环变量可以是基于起始值,结束值和步长的整数循环,也可以基于给定的列表进行循环,还可以把这些循环中的临时变量传递给每个具体的循环步骤。在 StartLoop Activity Stage 和 EndLoop Activity Stage 之间,可以加入任意多个的
- 支持逻辑运算,Nested Condition Stage 支持类似 switch 的逻辑,Sequencer Stage 支持与和或的逻辑运算,通过这些 Stage 的组合,可以支持任意复杂的逻辑控制。
- 支持 email 通知,使用 Notification Stage,在 job 运行成功,失败或者满足其他设定条件时,Sequence Job 可以发送一封或者多封的通知邮件,使我们可以更方便地监控 Job 的运行状态,邮件的内容可以包含 job 的运行状态,当前的参数等等,凡是可以在 User Variables Stage 中引用的变量都可以包含在邮件中,同时还可以包含我们指定的文件和 Sequence Job 的运行状态等。
- 支持错误处理和现场清理,使用 Terminator Activity Stage 和 Exception Handler Stage,我们可以定义需要处理的错误,并在错误发生的使用根据定义的策略停止不必要的 Job 运行。
- 通过 Wait for File Activity Stage 可以支持等待时间,我们可以定义只有某个信号文件出现或者消失的时候才开始启动 Wait for File Activity Stage 后续的执行。
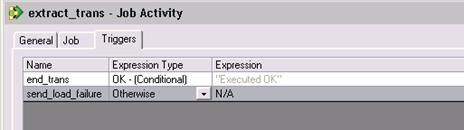
下面的图展示了一个简单的 Sequence Job,在 Job 的开始,我们定义一组变量,这些变量在我们循环和发送通知邮件的时候将会被引用。然后利用 Job 参数 yearlist 开始循环,每一个循环里面我们调用一次 Job extract_trans, 如果这个 job 调用执行不成功,我们就发邮件通知 Job 运行失败,否则进入下一个循环,在循环结束后,发邮件通知 Sequence Job 运行成功
图 15. Job 全景
图 16. 定义的变量

图 17. StartLoop Stage 的定义

图 18. Job Activity Triggers 定义