Hadoop 2.6.0 HBase 0.98 VMware单机伪分布式式环境搭建(作业用)
部分参考 Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04, 部分地方作了修正
从头开始,从虚拟机开始
安装Ubuntu 14.04
- 文件 -> 新建虚拟机 -> 自定义
直接默认下一步即可 - 选择ubuntu镜像
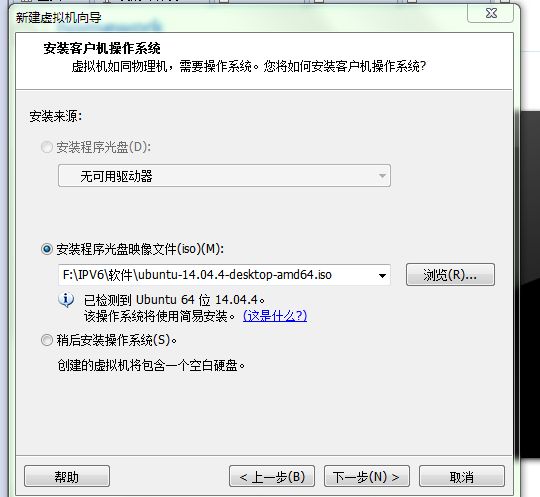
下一步 - 下面随便填,就自动安装了,就不在赘述了。
Ubuntu 基本环境
- 点击网络适配器
- 选择自定义VMnet8 模式

这样就可以共享windows下的宽连接啦~~~
Hadoop 2.6.0 配置
创建hadoop用户
如果你安装 Ubuntu 的时候不是用的 “hadoop” 用户,那么需要增加一个名为 hadoop 的用户。
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
sudo useradd -m hadoop -s /bin/bash设置密码,可简单设置为 hadoop,按提示输入两次密码,为hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题
sudo passwd hadoop
sudo adduser hadoop sudo安装SSH、配置SSH无密码登陆
sudo apt-get install openssh-server #安装服务
ssh localhost #登录本机,没配置无密码登录每次都要输入密码,麻烦首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了
关闭防火墙
- 关闭ubuntu的防火墙
ufw disable - 卸载了iptables
apt-get remove iptables 最后准备工作
更新 apt-get install、安装Java 参见博客 Spark-1.6.1 Hadoop-2.6.4 VMware Ubuntu伪分布式集群搭建 全过程, 这仅简要介绍Java 安装
安装Java
1.下载JDK
本次选择的是 jdk-8u73-linux-x64
放到Download目录, 当然随意看喜好
2.创建新目录
sudo mkdir /usr/local/java3.将下载到压缩包拷贝到java文件夹中
进入jdk源码包所在目录Download
解压压缩包,然后可以删除压缩包
cd Downloads
cp jdk-8u73-linux-x64.tar.gz /usr/local/java
cd /usr/local/java
sudo tar xvf jdk-8u73-linux-x64.tar.gz
sudo rm jdk-8u73-linux-x64.tar.gz4.设置jdk环境变量
sudo gedit ~/.bashrc添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_73
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin然后
source ~/.bashrc让配置立即生效
5.最后检查是否生效
在终端输入
java -version有一长串提示出现即可
Hadoop 2.6.0 配置
Hadoop 下载地址 http://www-us.apache.org/dist/hadoop/common/
假设将安装包放在 Downloads 中
我们选择将 Hadoop 安装至 /usr/local/ 中:
sudo tar -zxf ~/Downloads/hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version一些配置文件
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml
修改配置文件 core-site.xml (通过 gedit 编辑会比较方便: gedit ./etc/hadoop/core-site.xml)
gedit ./etc/hadoop/core-site.xml内容配置为
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>修改配置文件 hdfs-site.xml:
gedit ./etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>hadoop-env.sh
#第27行
export JAVA_HOME=/usr/local/java/jdk1.8.0_73将Hadoop 加入path
sudo gedit ~/.bashrc
#在其中添加
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export PATH=${SPARK_HOME}/sbin:$PATH
export PATH=${SPARK_HOME}/bin:$PATH
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后
source ~/.bashrc让配置立即生效
配置完成后,执行 NameNode 的格式化:
./bin/hdfs namenode -format执行成功后会提示“has been successful formatted”
开启Hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh 输入jps 会出现
jps、NameNode、DataNode、SecondaryNameNode
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
完工,接下来配置HBase
配置HBase
1.下载压缩包
http://www-us.apache.org/dist/hbase/0.98.17/
hbase-0.98.17-hadoop2-bin.tar.gz
2.创建并解压到 /usr/local/hbase
sudo tar -zxf ~/Downloads/hbase-0.98.17-hadoop2-bin.tar.gz -C /usr/local
cd /usr/local/
sudo mv ./hbase-0.98.17-hadoop2 ./hbase
sudo chown -R hadoop:hadoop ./hbase3.配置Hbase
编辑conf/hbase-env.sh文件
cd /usr/local/hbase/
#编辑conf/hbase-env.sh文件
vim conf/base-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_73编辑conf/hbase-site.xml文件:
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
<description>数据存放的位置。</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>指定副本个数为1,因为伪分布式。</description>
</property>修改 ulimit 限制
HBase 会在同一时间打开大量的文件句柄和进程,超过 Linux 的默认限制
所以编辑/etc/security/limits.conf文件,添加以下两行,提高能打开的句柄数量和进程数量。
hadoop - nofile 32768
hadoop - nproc 32000
还需要在 /etc/pam.d/common-session 加上这一行:
session required pam_limits.so
否则在/etc/security/limits.conf上的配置不会生效。
注销虚拟机
更新为hadoop的jar包
rm -rf hadoop*.jar
find /usr/local/hadoop/share/hadoop -name "hadoop*jar" | xargs -i cp {} /usr/local/hbase/lib/
运行Hbase
运行前确保hadoop已开启
cd /usr/local/hbase
./bin/start-hbase.sh
运行 jps 应该会有HMaster进程。在
在浏览器中输入 http://lochost:60010 可以看到 HBase Web UI 。
完工!!!