多线程系列:并发编程模型
本文属于并发编程网多线程学习系列。
并发系统可以采用多种并发编程模型来实现。并发模型指定了系统中的线程如何通过协作来完成分配给它们的作业。
并行工作者
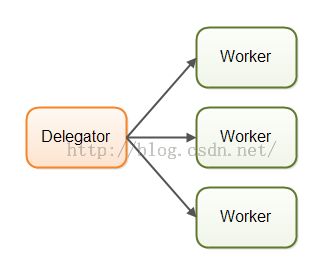
在并行工作者模型中,委派者(Delegator)将传入的作业分配给不同的工作者。每个工作者完成整个任务。工作者们并行运作在不同的线程上,甚至可能在不同的CPU上。在Java应用系统中,并行工作者模型是最常见的并发模型(即使正在转变)。java.util.concurrent包中的许多并发实用工具都是设计用于这个模型的。
优点:
可以多个worker并行工作,提高系统并行性。
缺点:
共享状态可能会很复杂
线程需要以某种方式存取共享数据,以确保某个线程的修改能够对其他线程可见(数据修改需要同步到主存中,不仅仅将数据保存在执行这个线程的CPU的缓存中)。线程需要避免竟态,死锁以及很多其他共享状态的并发性问题。
此外,在等待访问共享数据结构时,线程之间的互相等待将会丢失部分并行性。许多并发数据结构是阻塞的,意味着在任何一个时间只有一个或者很少的线程能够访问。这样会导致在这些共享数据结构上出现竞争状态。在执行需要访问共享数据结构部分的代码时,高竞争基本上会导致执行时出现一定程度的串行化。
无状态的工作者
共享状态能够被系统中得其他线程修改。所以工作者在每次需要的时候必须重读状态,以确保每次都能访问到最新的副本,不管共享状态是保存在内存中的还是在外部数据库中。工作者无法在内部保存这个状态(但是每次需要的时候可以重读)称为无状态的。
任务顺序是不确定的
并行工作者模式的另一个缺点是,作业执行顺序是不确定的。无法保证哪个作业最先或者最后被执行。作业A可能在作业B之前就被分配工作者了,但是作业B反而有可能在作业A之前执行。
并行工作者模式的这种非确定性的特性,使得很难在任何特定的时间点推断系统的状态。这也使得它也更难(如果不是不可能的话)保证一个作业在其他作业之前被执行。
流水线模式
流水线模式为了跟上面并发模式对应,还有别的名字如:反应器系统,或事件驱动系统。下图表示一个流水线并发模型:
通常使用非阻塞的IO来设计使用流水线并发模型的系统。非阻塞IO意味着,一旦某个工作者开始一个IO操作的时候(比如读取文件或从网络连接中读取数据),这个工作者不会一直等待IO操作的结束。IO操作速度很慢,所以等待IO操作结束很浪费CPU时间。此时CPU可以做一些其他事情。当IO操作完成的时候,IO操作的结果(比如读出的数据或者数据写完的状态)被传递给下一个工作者。
有了非阻塞IO,就可以使用IO操作确定工作者之间的边界。工作者会尽可能多运行直到遇到并启动一个IO操作。然后交出作业的控制权。当IO操作完成的时候,在流水线上的下一个工作者继续进行操作,直到它也遇到并启动一个IO操作。
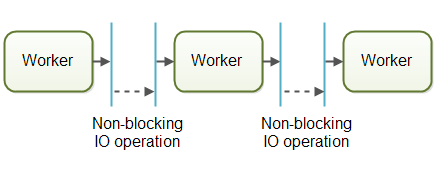
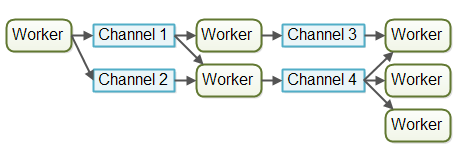
在实际应用中,作业有可能不会沿着单一流水线进行。作业甚至也有可能被转发到超过一个工作者上并发处理。比如说,作业有可能被同时转发到作业执行器和作业日志器。下图说明了三条流水线是如何通过将作业转发给同一个工作者(中间流水线的最后一个工作者)来完成作业:
Actors 和 Channels
Actors 和 channels 是两种比较类似的流水线(或反应器/事件驱动)模型。
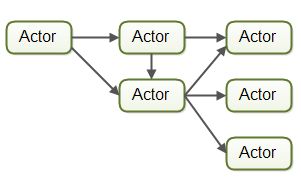
在Actor模型中每个工作者被称为actor。Actor之间可以直接异步地发送和处理消息。Actor可以被用来实现一个或多个像前文描述的那样的作业处理流水线。下图给出了Actor模型:
优点:
无需共享的状态
工作者之间无需共享状态,意味着实现的时候无需考虑所有因并发访问共享对象而产生的并发性问题。这使得在实现工作者的时候变得非常容易。在实现工作者的时候就好像是单个线程在处理工作-基本上是一个单线程的实现。
有状态的工作者
当工作者知道了没有其他线程可以修改它们的数据,工作者可以变成有状态的。对于有状态,我是指,它们可以在内存中保存它们需要操作的数据,只需在最后将更改写回到外部存储系统。因此,有状态的工作者通常比无状态的工作者具有更高的性能。
合理的作业顺序
基于流水线并发模型实现的并发系统,在某种程度上是有可能保证作业的顺序的。作业的有序性使得它更容易地推出系统在某个特定时间点的状态。
缺点:
流水线并发模型最大的缺点是作业的执行往往分布到多个工作者上,并因此分布到项目中的多个类上。这样导致在追踪某个作业到底被什么代码执行时变得困难。三函数式并行
函数式并行的基本思想是采用函数调用实现程序。函数可以看作是”代理人(agents)“或者”actor“,函数之间可以像流水线模型(AKA 反应器或者事件驱动系统)那样互相发送消息。某个函数调用另一个函数,这个过程类似于消息发送。
函数都是通过拷贝来传递参数的,所以除了接收函数外没有实体可以操作数据。这对于避免共享数据的竞态来说是很有必要的。同样也使得函数的执行类似于原子操作。每个函数调用的执行独立于任何其他函数的调用。
函数式并行里面最难的是确定需要并行的那个函数调用。跨CPU协调函数调用需要一定的开销。某个函数完成的工作单元需要达到某个大小以弥补这个开销。如果函数调用作用非常小,将它并行化可能比单线程、单CPU执行还慢。原文地址:
http://ifeve.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B%E6%A8%A1%E5%9E%8B/