数据结构和算法06 之2-3-4树
本文为博主原创文章,转载请注明出处: http://blog.csdn.net/eson_15/article/details/51140009
从第4节的分析中可以看出,二叉搜索树是个很好的数据结构,可以快速地找到一个给定关键字的数据项,并且可以快速地插入和删除数据项。但是二叉搜索树有个很麻烦的问题,如果树中插入的是随机数据,则执行效果很好,但如果插入的是有序或者逆序的数据,那么二叉搜索树的执行速度就变得很慢。因为当插入数值有序时,二叉树就是非平衡的了,它的快速查找、插入和删除指定数据项的能力就丧失了。
2-3-4树是一个多叉树,它的每个节点最多有四个子节点和三个数据项。2-3-4树和红-黑树一样,也是平衡树,它的效率比红-黑树稍差,但是编程容易。2-3-4树名字中的2、3、4的含义是指一个节点可能含有的子节点的个数。对非叶节点有三种可能的情况:
·有一个数据项的节点总是有两个子节点;
·有两个数据项的节点总是有三个子节点;
·有三个数据项的节点总是有四个字节点。
简而言之,非叶节点的子节点总是比它含有的数据项多1。如下图所示:
为了方便起见,用0到2给数据项编号,用0到3给子节点链编号。树的结构中很重要的一点就是它的链与自己数据项的关键字值之间的关系。二叉树所有关键字值比某个节点值小的都在这个节点的左子节点为根的子树上,所有关键字值比某个及诶的那值大的节点都在这个节点右子节点为根的子树上。2-3-4树中规则是一样的,还加上了以下几点:
·根是child0的子树的所有子节点的关键字值小于key0;
·根是child1的子树的所有子节点的关键字值大于key0并且小于key1;
·根是child2的子树的所有子节点的关键字值大于key1并且小于key2;
·根是child3的子树的所有子节点的关键字值大于key2。
这种关系如下图所示,2-3-4树中一般不允许出现重复关键字值,所以不用考虑比较相同的关键字值的情况。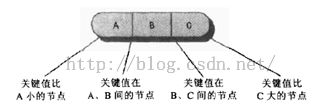
2-3-4树中插入节点有时比较简单,有时比较复杂。当没有碰到满节点时插入很简单,找到合适的叶节点后,只要把新数据项插入进去即可,插入可能会涉及到在一个节点中移动一个或两个其他的数据项,这样在新的数据项插入后关键字值仍保持正确的顺序。如下图:
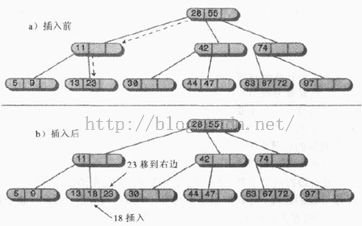
如果往下寻找要插入的位置的路途中,节点已经满了,插入就变得复杂了。这种情况下,节点必须分裂。正是这种分裂过程保证了树的平衡。设要分裂节点中的数据项为A、B、C,下面是分裂时的情况(假设分裂的节点不是根节点):
·创建一个新的空节点,它是要分裂节点的兄弟,在要分裂节点的右边;
·数据项C移到新节点中;
·数据项B移动到要分裂节点的父节点中;
·数据项A保留在原来的位置;
·最右边的两个子节点从要分裂节点处断开,连接到新节点上。
下图显示了一个节点分裂的过程。另一种描述节点分裂的方法是说4-节点变成了两个2-节点。
如果一开始查找插入点时就碰到满根时,插入过程就更复杂一点:
·创建新的根。它是要分裂节点的父节点;
·创建第二个新的节点。它是要分裂节点的兄弟节点;
·数据项C移动到新的兄弟节点中;
·数据项B移动到新的根节点中;
·数据项A保留在原来的位置上;
·要分裂节点最右边的两个子节点断开连接,连接到新的兄弟节点中。
下图是根分裂的过程。过程中创建新的根,比旧的高一层,因此整个树的高度就增加了一层。
下面是2-3-4树的代码:
public class Tree234 {
private Node2 root = new Node2();
public int find(long key) {
Node2 currentNode = root;
int childNumber;
while(true) {
if((childNumber = currentNode.findItem(key)) != -1) {
return childNumber;
}
else if(currentNode.isLeaf()) {
return -1;
}
else {
currentNode = getNextChild(currentNode, key);
}
}
}
//insert a DataItem
public void insert(long data) {
Node2 currentNode = root;
DataItem tempItem = new DataItem(data);
while(true) {
if(currentNode.isFull()) {
split(currentNode); //if node is full, split it
currentNode = currentNode.getParent(); //back up
currentNode = getNextChild(currentNode, data); //search once
}
else if(currentNode.isLeaf()) { //if node if leaf
break; //go insert
}
else {
currentNode = getNextChild(currentNode, data);
}
}
currentNode.insertItem(tempItem);
}
//display tree
public void displayTree() {
recDisplayTree(root, 0, 0);
}
public Node2 getNextChild(Node2 currentNode, long key) {
int j;
//assumes node is not empty, not full and not leaf
int numItems = currentNode.getNumItems();
for(j = 0; j < numItems; j++) {
if(key < currentNode.getItem(j).dData) {
return currentNode.getChild(j);
}
}
return currentNode.getChild(j);
}
public void split(Node2 currentNode) {
//assumes node is full
DataItem itemB, itemC; //存储要分裂节点的后两个DataItem
Node2 parent, child2, child3; //存储要分裂节点的父节点和后两个child
int itemIndex;
itemC = currentNode.removeItem();
itemB = currentNode.removeItem(); //remove items from this node
child2 = currentNode.disconnectChild(2);
child3 = currentNode.disconnectChild(3); //remove children from this node
Node2 newRight = new Node2(); //make a new node
if(currentNode == root) {
root = new Node2(); //make a new root
parent = root; //root is our parent
root.connectChild(0, currentNode);//connect currentNode to parent
}
else {
parent = currentNode.getParent();
}
//deal with parent
itemIndex = parent.insertItem(itemB); //insert B to parent
int n = parent.getNumItems(); //total items
for(int j = n-1; j > itemIndex; j--) {
Node2 temp = parent.disconnectChild(j);
parent.connectChild(j+1, temp);
}
parent.connectChild(itemIndex+1, newRight);
//deal with newRight
newRight.insertItem(itemC);
newRight.connectChild(0, child2);
newRight.connectChild(1, child3);
}
public void recDisplayTree(Node2 thisNode, int level, int childNumber) {
System.out.print("level = " + level + " child = " + childNumber + " ");
thisNode.displayNode();
//call ourselves for each child of this node
int numItems = thisNode.getNumItems();
for(int j = 0; j < numItems+1; j++) {
Node2 nextNode = thisNode.getChild(j);
if(nextNode != null) {
recDisplayTree(nextNode, level+1, j);
}
else
continue;
}
}
}
//数据项
class DataItem {
public long dData;
public DataItem(long data) {
dData = data;
}
public void displayItem() {
System.out.print("/" + dData);
}
}
//节点
class Node2 {
private static final int ORDER = 4;
private int numItems; //表示该节点存有多少个数据项
private Node2 parent;
private Node2 childArray[] = new Node2[ORDER]; //存储子节点的数组,最多四个子节点
private DataItem itemArray[] = new DataItem[ORDER-1];//该节点中存放数据项的数组,每个节点最多存放三个数据项
//连接子节点
public void connectChild(int childNum, Node2 child) {
childArray[childNum] = child;
if(child != null) {
child.parent = this;
}
}
//断开与子节点的连接,并返回该子节点
public Node2 disconnectChild(int childNum) {
Node2 tempNode = childArray[childNum];
childArray[childNum] = null;
return tempNode;
}
public Node2 getChild(int childNum) {
return childArray[childNum];
}
public Node2 getParent() {
return parent;
}
public boolean isLeaf() {
return (childArray[0] == null);
}
public int getNumItems() {
return numItems;
}
public DataItem getItem(int index) {
return itemArray[index];
}
public boolean isFull() {
return (numItems == ORDER-1);
}
public int findItem(long key) {
for(int j = 0; j < ORDER-1; j++) {
if(itemArray[j] == null) {
break;
}
else if(itemArray[j].dData == key) {
return j;
}
}
return -1;
}
public int insertItem(DataItem newItem) {
//assumes node is not full
numItems++;
long newKey = newItem.dData;
for(int j = ORDER-2; j >= 0; j--) { //start on right
if(itemArray[j] == null) { //item is null
continue; //get left one cell
}
else { //not null
long itsKey = itemArray[j].dData; //get its key
if(newKey < itsKey) { //if it's bigger
itemArray[j+1] = itemArray[j]; //shift it right
}
else {
itemArray[j+1] = newItem; //insert new item
return j+1; //return index to new item
}
}
}
itemArray[0] = newItem;
return 0;
}
public DataItem removeItem() {
//assumes node not empty
DataItem tempItem = itemArray[numItems-1]; //save item
itemArray[numItems-1] = null; //disconnect it
numItems--;
return tempItem;
}
public void displayNode() {
for(int i = 0; i < numItems; i++) {
itemArray[i].displayItem();
}
System.out.println("/");
}
}
和红-黑树一样,2-3-4树同样要访问每层的一个节点,但2-3-4树有比相同数据项的红-黑树短(层数少)。更特别的是,2-3-4树中每个节点最多可以有4个子节点,如果每个节点都是满的,树的高度应该和log4N成正比。以2为底的对数和以4为底的对数底数相差2,因此,在所有节点都满的情况下,2-3-4树的高度大致是红-黑树的一般。不过它们不可能都是满的,2-3-4树的高度就大致在log2(N+1)和log2(N+1)/2之间。
另一方面,每个节点要查看的数据项就更多了,这会增加查找时间。因为节点中用线性搜索来查看数据项,使查找时间增加的倍数和M成正比,即每个节点数据项的平均数量。总的查找时间和M*log4N成正比。有些节点有1个数据项,有些有2个,有些有3个,如果按照平均两个来计算,查找时间和2*log4N成正比。
因此,2-3-4树中增加每个节点的数据项数量可以抵偿树的高度的减少。2-3-4树中的查找时间与平衡二叉树(如红-黑树)大致相等,都是O(logN)。
2-3-4树就讨论到这,如果有问题欢迎留言指正~
_____________________________________________________________________________________________________________________________________________________
-----更多文章请看:http://blog.csdn.net/eson_15