Class-Specific Hough Forests for Object Detection
Hough forest可以看作classification forest和Regression forest的结合体,
即具有classification forest的特性也具有Regression forest的特性,在节点分列时同时考虑了分类与回归,在本文中就是class-label uncertainty与offset uncertainty
1、Building
Sample
Training each tree on a random subset of the training data
Binary test
A random subset of possible binary tests
Choose the best one
Leaf node
depth of the node is equal to the maximal
the number of patches is small
训练森林最核心的部分就是节点分裂,抽样以及分裂的终止条件都比较简单,这里主要介绍Binary test
节点分裂的确定这里是通过像素值的比较来实现的(pixel-based tests):
即随机在一个patch中选取两个像素点(p,q)、(r,s)进行灰度值比较,以此来确定分裂
分裂时我们要尽可能的使uncertainty小,这里提出了两种uncertainty
1、class-label uncertainty-----对应着classification forest的的特性
这里用
![]()
来代替所有patch的集合
class-label uncertainty 定义为下面的形式
![]()
其中c是所有class-label的平均值,class-label的取值范围是1或0,1代表对应的patch是属于object,0代表patch属于background
c的取值范围是0到1
2、offset uncertainty------对应着regression forest的特性
offset uncertainty定义为
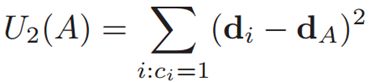
dA是所有偏移量的平均值
之后就是确定最优的分裂方式
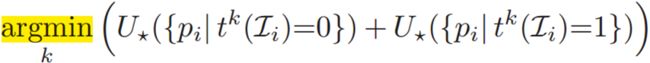
where * =1 or 2(depending on our random choice)
2、Object Detection
首先是做些规定,前提假设神马的,下面是我自己做的ppt上的截图。。。。偷个懒

下面就是要求得这个概率P(E(x)|I(y))
首先对于一个patch,最终来到某棵树的某个叶结点

然后扩展到一个patch在一棵树中的情况以及扩展到整个森林的情况:

最后就是所有path在森林中的结果:

每个像素点的V(x)值各不相同,其值越大,就是获得vote最多,最终利用meanshift就可以获得object的中心
论文原文及我的一些注释 和 ppt已上传 有兴趣可以看看。。。。。。。可能有错的。。。求指出!
注:对于训练森林其实可看作训练一个函数y=f(x)---参见随机森林那篇
在这里输入的x相当于里面的![]() ,输出的y其实就相当于和
,输出的y其实就相当于和![]()