Hadoop学习8:hdfs文件操作
Hadoop学习8:hdfs文件操作
标签(空格分隔): hadoop
- Hadoop学习8hdfs文件操作
- 一hdfs文件流读操作
- 三合并文件上传到
一,hdfs文件流读操作
读文件流程
(1)打开分布式文件
调用 分布式文件 DistributedFileSystem.open()方法
(2)从 NameNode 获得 DataNode 地址
DistributedFileSystem 使用 RPC 调用 NameNode,NameNode 返回存有该副本的 DataNode 地址,DistributedFileSystem 返 回一个输入流 FSDataInputStream对象,该对象封存了输入流 DFSInputStream
(3)连接到DataNode
调用 输入流 FSDataInputStream 的 read() 方法,从而 输入流 DFSInputStream 连接 DataNodes
(4)读取DataNode
反复调用 read()方法,从而将数据从 DataNode 传输到客户端
(5)读取另外的DataNode直到完成
到达块的末端时候,输入流 DFSInputStream 关闭与DataNode 连接, 寻找下一个 DataNode
(6)完成读取,关闭连接
即调用输入流 FSDataInputStream.close()
1,从hdfs读取文件
package org.apache.hadoop.studyhdfs;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HdfsApi {
public static FileSystem getFs() throws IOException{
//获取配置文件
Configuration conf = new Configuration();
//获取文件系统
FileSystem fs = FileSystem.get(conf);
return fs;
}
public static void readFile(String src) throws IOException{
// Get FileSystem
FileSystem fs = getFs();
//读的路径
Path readPath = new Path(src);
FSDataInputStream inStream = null;
try {
//打开输入流
inStream = fs.open(readPath);
IOUtils.copyBytes(inStream, System.out, 4096, false);
} catch (Exception e) {
e.printStackTrace();
}finally{
IOUtils.closeStream(inStream);
}
}
public static void main(String[] args) throws IOException {
}
}2,从hdfs上下载文件
package org.apache.hadoop.studyhdfs;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HdfsApi {
public static FileSystem getFs() throws IOException{
//获取配置文件
Configuration conf = new Configuration();
//获取文件系统
FileSystem fs = FileSystem.get(conf);
return fs;
}
public static void downLoad(String src,String dst) throws IOException{
FileSystem fs = getFs();
fs.copyToLocalFile(new Path(src), new Path(dst));
fs.close();
}
public static void main(String[] args) throws IOException {
}
}3,重命名hdfs上的文件
package org.apache.hadoop.studyhdfs;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HdfsApi {
public static FileSystem getFs() throws IOException{
//获取配置文件
Configuration conf = new Configuration();
//获取文件系统
FileSystem fs = FileSystem.get(conf);
return fs;
}
public static void renameMV(String src,String dst) throws IOException{
FileSystem fs = getFs();
fs.rename(new Path(src), new Path(dst));
fs.close();
}
public static void main(String[] args) throws IOException {
}
}4,删除hdfs上的文件
package org.apache.hadoop.studyhdfs;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HdfsApi {
public static FileSystem getFs() throws IOException{
//获取配置文件
Configuration conf = new Configuration();
//获取文件系统
FileSystem fs = FileSystem.get(conf);
return fs;
}
public static void delete(String fileName) throws IOException{
FileSystem fs = getFs();
fs.deleteOnExit(new Path(fileName));
}
public static void main(String[] args) throws IOException {
}
}5,获取hdfs目录下的文件列表
package org.apache.hadoop.studyhdfs;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HdfsApi {
public static FileSystem getFs() throws IOException{
//获取配置文件
Configuration conf = new Configuration();
//获取文件系统
FileSystem fs = FileSystem.get(conf);
return fs;
}
public static void listFile(String dirName) throws IOException{
FileSystem fs = getFs();
FileStatus[] fileStatuses = fs.listStatus(new Path(dirName));
for(FileStatus fileName:fileStatuses){
System.out.println(fileName.getPath().getName());
}
}
public static void main(String[] args) throws IOException {
}
}二,hdfs文件流写操作
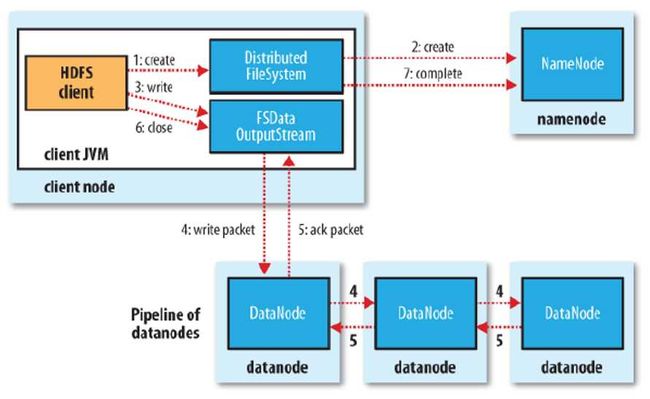
(1)发送创建文件请求:调用分布式文件系统DistributedFileSystem.create()方法 (2)NameNode中创建文件记录:分布式文件系统DistributedFileSystem 发送 RPC 请求给namenode,namenode 检查权限后创建一条记录,返回输出流 FSDataOutputStream,封装了输出流 DFSOutputDtream (3)客户端写入数据:输出流 DFSOutputDtream 将数据分成一个个的数据包,并写入内部队列。DataStreamer 根据 DataNode 列表来要求 namenode 分配适合的新块来存储数据备份。一组DataNode 构成管线(管线的 DataNode 之间使用 Socket 流式通信) (4)使用管线传输数据:DataStreamer 将数据包流式传输到管线第一个DataNode,第一个DataNode 再传到第二个DataNode ,直到完成。 (5)确认队列:DataNode 收到数据后发送确认,管线的DataNode所有的确认组成一个确认队列。所有DataNode 都确认,管线数据包删除。 (6)关闭:客户端对数据量调用close()方法。将剩余所有数据写入DataNode管线,并联系NameNode且发送文件写入完成信息之前等待确认。 (7)NameNode确认 (8)故障处理:若过程中发生故障,则先关闭管线, 把队列中所有数据包添加回去队列,确保数据包不漏。为另一个正常DataNode的当前数据块指定一个新的标识,并将该标识传送给NameNode, 一遍故障DataNode在恢复后删除上面的不完整数据块. 从管线中删除故障DataNode 并把余下的数据块写入余下正常的DataNode。NameNode发现复本两不足时,会在另一个节点创建一个新的复本1,往hdfs上写文件
package org.apache.hadoop.studyhdfs;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HdfsApi {
public static FileSystem getFs() throws IOException{
//获取配置文件
Configuration conf = new Configuration();
//获取文件系统
FileSystem fs = FileSystem.get(conf);
return fs;
}
public static void writeFile(String src,String dst) throws IOException{
FileSystem fs = getFs();
File inFile = new File(src);
Path outFile = new Path(dst);
FileInputStream inStream = null;
FSDataOutputStream outStream = null;
try {
//打开输入流
inStream = new FileInputStream(inFile);
//打开输出流
outStream = fs.create(outFile);
IOUtils.copyBytes(inStream, outStream,4096, false);
} catch (Exception e) {
// TODO: handle exception
}finally{
IOUtils.closeStream(inStream);
IOUtils.closeStream(outStream);
}
}
public static void main(String[] args) throws IOException {
}
}
三,合并文件上传到hdfs
实现方式:
1,现在本地合并然后上传
2,在上传的过程中进行合并
–2.1:获取文件系统
–2.2:列举需要合并的文件
–2.3:打开文件,打开输入流
–2.4:打开输出流
–2.5:关闭流
1,shell命令和并文件
[hadoop002@hadoop002 hadoop-2.5.0]$ bin/hdfs dfs -getmerge /core-site.xml /hdfs-site.xml ./1.xml 2,代码实现
package org.apache.hadoop.studyhdfs;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
/** * 上传过程中进行文件合并 * a、获取文件系统(LocalFileSystem和FileSystem) * b、列举需要合并的文件 * c、打开文件,打开输入流 * d、打开输出流 * e、关闭流 * */
public class PutMerge {
public static void main(String[] args) throws IOException {
//step 1 : Get FileSyste
Configuration conf = new Configuration();
LocalFileSystem localFs = FileSystem.getLocal(conf);
FileSystem dfs = FileSystem.get(conf);
//step 2 : in/out Path
Path inPath = new Path("/opt/app/hadoop-2.5.0/etc/hadoop");
Path outPath = new Path("/data2/putmerge.xml");
FileStatus[] fileStatuses = localFs.listStatus(inPath);
OutputStream outStream = null;
InputStream inStream = null;
try {
//step 4 : 打开输出流
outStream = dfs.create(outPath);
for(FileStatus fileName:fileStatuses){
//step 3 : 打开输入流
inStream = localFs.open(fileName.getPath());
IOUtils.copyBytes(inStream, outStream, 4096, false);
IOUtils.closeStream(inStream);
System.out.println(fileName.getPath());
}
} catch (Exception e) {
e.printStackTrace();
}finally{
IOUtils.closeStream(outStream);
System.out.println("PutMerge Success");
}
}
}