Redis 一种主主复制解决方案及其实现
问题的提出
redis(特指2.8.14及以下)replication仅支持主从复制。在实际生产环境中,这种单向主从复制,没有办法做高可用(当然,如果允许数据丢失的话,可以采用keepalived,采用其notify_master/notify_slave机制,强制实现主从的角色互换,这种方式对主从强行互换的过程中,如果存在未同步的数据,将会彻底丢失,是一种极其危险的方案,用于生产环境是不可取的)。所谓他山之石,可以攻玉。mysql提供成熟的主主复制,结合keepalived动态IP,可以做到两个结点同时准备(ready)提供服务,任何一台挂掉的时候,另一台立刻无缝接管。当挂掉的那台启动之后,未同步的数据还会继续同步过来,最大限度保证数据不丢失。当然这种方案也并非100%一致,因为当挂掉结点起来之后可能存在操作续列的先后顺序问题从而造成数据少量不一致,未同步的数据越多,不一致的可能性越大,但在生产应用中,这种方案已经可以最大限度保证高可用性,而且对一致性影响并非特别严重,因此该方案被广泛采用。
借鉴MYSQL的经验,要实现redis的高可用,首先要解决主主复制问题。Gleasy最初实现了一种基于代理机制的redis集群方案,用于解决这个问题,可以参考这篇文章 《Gleasy的NOSQL数据库集群Cloudredis》。这个集群方案在生产环境中工作一段时间,就暴露出了一个问题,集群内的结点,无法做到数据完全一致,不一致的地方存在于那些已经过期的key(设置了expire,并且到期)。redis的key失效机制分为主动失效和被动失效,而主动失效每次仅随机失效很小一部分,当过期的KEY数量庞大时,在相当长的时间内,这些过期的KEY会一直存在,而集群内所有结点都会随机失效一部分,从而导致这些结点失效的KEY不一样,最终反映出来的结果就是数据不一致,而这种不一致,会对运维工作造成极大的困惑,因为不知道到底是由于同步机制异常还是由于KEY失效引起,从而令到运维人员时时如履薄冰,坐立不安。最终决定,另外提供一种机制实现真正的redis主主复制。
实现原理
1. 概述在每个redis结点上安装一个模块(我们称之为集群模块),它可以获取该redis结点所有的写操作命令序列;
集群模块获取redis结点的所有写操作序列,并将之写入binlog文件;
从结点的集群模块定时向主结点的集群模块请求binlog块,并记录上次请求的位置,下次请求的时候,接着上次的位置获取;
从结点的集群模块拿到binglog块,分析出写操作序列命令,在从结点redis中执行。
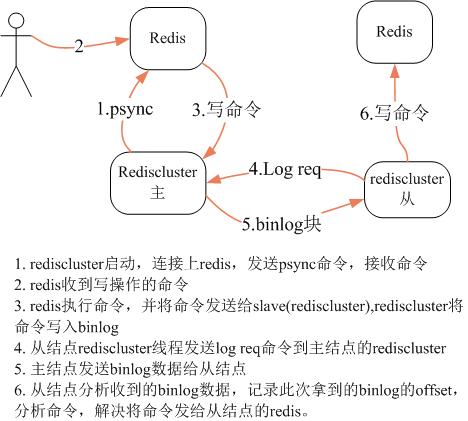
下面是单向复制的结构图(双向复制其实就是两对单向复制a->b,b->a):

2. 具体实现
集群模块以一个独立的应用存在,取名为rediscluster(之所以做成独立的进程,一是为了性能更好,避免加入redis的单线程事件机制中,二是避免过多修改redis源码从而导致升级不便);
rediscluster监听独立的端口,rediscluster之间通过访问互相之间的独立端口进行通信;
每个redis结点对应一个rediscluster,rediscluster启动后,作为redis的slave,实时接收所有写操作命令序列;
rediscluster启动一个独立的线程,定期访问主结点rediscluster的端口,获取binlog数据;
一些技术关键点
1 一致性保证及技术实现通过以下约束来保证一致性:
a. rediscluster未准备就绪的情况下(即未能正确接收操作命令并写入binlog),redis不能接受写操作.即binlog写不成功,就不提供写操作服务。
实现 :设置redis的min-slaves-to-write参数为1,将保证了至少有一个slave工作良好情况下才允许写入
b.从结点的redis不开启过期key的主动失效功能,只有主结点才开启过期key的主动失效功能
实现:rediscluster接收到binlog,则关闭redis的主动失效功能;rediscluster接收到来自redis的写命令,则开启redis的主动失效功能;
c. 主结点和从结点不允许同时写(一方写,另一方自动变成只读)
实现: rediscluster接收到binlog,则屏蔽redis的写操作;
d. slave收到的主结点的写命令,不再发送给rediscluter。
实现:rediscluster发送binlog off命令给redis,之后接收到binlog,写入redis,redis将不会发送给slave。
e. 所有命令加上服务器唯一标识,避免死循环。
实现:rediscluster写入binlog文件时,加上本服务器的唯一标识。当形成主从环时,根据该唯一标识,忽略自己生成的binlog,只消费别人生成的binlog.
2 对redis的改造
a. 开启/关闭主动失效功能
引入命令 backup on/off来关闭/开启该功能
b. 屏蔽写操作
引入命令 lock on/off来屏蔽/解除屏蔽写操作
c. 开启/关闭该连接的binlog功能
引入命令binlog on/off来开启/关闭当前连接的binlog功能(关闭后,由该连接发出的所有写操作,将不会发给slave)
c. 特殊连接无视lock功能
引入命令cluster来开启当前连接的无视lock功能(开启后,由该连接发出的所有写操作,将无视lock,即不管lock=on还是off,都可写)
问题的解决
此方案真正实现了redis的主-主复制,配合keepalived,可以很好地实现高可用。此方案由于采用binlog的方式进行数据同步,断线后,或者重启后,都可以从上次的位置继续同步,完全规避了redis主从首次全量同步的方式,从而也规避了海量数据时,redis主从同步导致IO,CPU,带宽狂升的问题。
经笔者实测,此方案开启主主复制情况下,对redis性能无明显影响(10次对比性能差异几乎可以忽略不计【差异小于3%,考虑到测试的精确度,几乎可以忽略】);
rediscluster为单独应用,自主升级;源码暂不开放。
redis源码修改不超过20行,日后redis升级无障碍;源码在此 redis-2.8.14; 也可以通过github下载,地址为 redis-2.8.14 gleasy master-master
运行截图

binlogs示例

rediscluster配置文件

rediscluster运行时信息
本文为Gleasy原创文章,转载请指明引自Gleasy团队博客。