Hadoop-2.6.2集群配置安装
Hadoop-2.6.2集群安装
- Hadoop-262集群安装
- 环境说明
- 基础环境搭建
- CentOS 7安装
- 新建用户hadoop
- 配置hosts
- 关闭防火墙
- 安装jdk180_40
- ssh配置
- 安装配置hadoop-262
- hadoop环境变量
- hadoop参数文件配置
- 格式化文件系统
- 验证安装
- 本机网页管理
- 出现的问题
环境说明
- 主机Windows 10, 12g内存, i5-3337U
- VMware 12下的4台虚拟CentOS 7系统最小化安装
- 每台虚拟机中配置安装好jdk1.8.0_40
- 配置安装好hadoop-2.6.2
- 用到的工具,xmanager5
基础环境搭建
CentOS 7安装
由于是用来进行实验的,先最小化安装一个1G内存,40G磁盘的CentOS x64。这个不用来实验,放到base文件夹中。
然后克隆出一个CentOS x64 hadoop0,这个是作为master机
对这个master完成基础的配置(jdk环境和环境变量配置)后,再克隆出三个slaves机:CentOS x64 hadoop1,CentOS x64 hadoop2,CentOS x64 hadoop3。
上网方式采用的是NAT上网
IP地址采用的是dhcp动态分配。四台机ip如下:
| 主机 | ip地址 |
|---|---|
| CentOS x64 hadoop0 | 192.168.248.148 |
| CentOS x64 hadoop1 | 192.168.248.149 |
| CentOS x64 hadoop2 | 192.168.248.150 |
| CentOS x64 hadoop3 | 192.168.248.151 |
当然,为了ip地址的稳定,可以采用静态ip地址分配:
#vi /etc/sysconfig/network-scripts/ifcfg-eno16777736
修改如下:
BOOTPROTO="static"
IPADDR=192.168.248.148
GATEWAY=192.168.248.2
DNS1=114.114.114.114
注意,每台的IPADDR不一样,而且一定要配置DNS1,否者无法域名解析,即ping不通网址,只能ping同ip地址。网关是多少,可以在VMware 12 的 编辑 -> 虚拟网络编辑器 -> NAT设置 查看
新建用户hadoop
为了实验的方便,创建一个用户组为hadoop,密码为hadoop的用户hadoop
#useradd hadoop
#passwd hadoop
输入密码hadoop
切换到用户hadoop
$su hadoop
配置hosts
这里是配置主机映射
#vi /etc/hosts
添加如下内容
192.168.248.148 hadoop0
192.168.248.149 hadoop1
192.168.248.150 hadoop2
192.168.248.151 hadoop3
修改本机hostname
#vi /etc/sysconfig/network
添加如下(这里的HOSTNAME需要在之后的克隆子机中修改)
NETWORKING=yes
HOSTNAME=hadoop0关闭防火墙
虽然关闭防火墙是不安全的,倒是为了实验的方便就关闭了,当然也可以用iptables来代替
关闭防火墙
#systemctl stop firewalld.service
禁止firewall开机启动
#systemctl disable firewalld.service
关闭SELINUX
#vi /etc/selinux/config
修改为SELINUX=disabled
安装jdk1.8.0_40
启动虚拟机后,用xshell和xftp连接到CentOS x64 hadoop0。xftp把下载好的jdk-8u40-linux-x64.tar.gz上传到虚拟机中的hadoop用户目录中。之后的所有的命令操作都是通过xshell远程终端操作。
卸载CentOS 7自带的openjdk(最小化安装可不用)
#yum autoremove java
解压jdk安装包
$tar -zxvf jdk-8u40-linux-x64.tar.gz
#mkdir /usr/local/java
配置环境变量
#vi /etc/profile
添加内容如下
export JAVA_HOME=/usr/local/java/jdk1.8.0_40
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH:$JRE_HOME/bin使配置生效
#source /etc/profile
验证jdk
$java -version
java version “1.8.0_40”
Java(TM) SE Runtime Environment (build 1.8.0_40-b26)
Java HotSpot(TM) 64-Bit Server VM (build 25.40-b25, mixed mode)
说明:这里修改的是/etc/profile文件,作用是所有的用户,而~/.bashrc作用的是当前用户
ssh配置
到了这里,已经可以把master主机克隆出三个slaves主机,为了让四台机能互相免密登陆,配置ssh密钥
每台机进行如下操作(在hadoop用户下)
$ssh-keygen -t rsa
之后一路确认,因为是实验,所以不设口令
生成ssh密钥在~/.ssh/目录中,文件如下:
id_rsa
id_rsa.pub
在每台slave子机中通过如下命令把公钥复制到master机(命令最后的x须不同,否则会互相覆盖)
$scp id_rsa.pub hadoop0:~/.ssh/id_rsa.pubx
这条命令的格式为:
scp filename username@hostname:filePath
现在,在master机上~/.ssh/目录中有四个公钥,根据这四个公钥生成认证用的公钥
$cat id_rsa.pubx >> authorized_keys
这条命令执行四次(x须略微修改),注意使用的是>>,在authorized_keys追加公钥的意思
给每一个机器分发认证公钥(hadoopx中x的取值为1、2、3)
$scp authorized_keys hadoopx:~/.ssh/authorized_keys
验证ssh是否免密互相登陆,这里我是失败的,经过如下的权限修改,就可以了(如果在hadoop用户下修改不了,可以切换到root用户)
$chmod 700 ~/.ssh/
$chmod 600 ~/.ssh/authorized_keys
安装配置hadoop-2.6.2
用xftp上传hadoop-2.6.2.tar.gz到hadoop用户目录中
由于所有的机器的配置安装hadoop相同,可以在master主机中配置,之后再通过xftp复制到各个slave子机中,再配环境变量
解压hadoop-2.6.2.tar.gz
$tar -zxvf hadoop-2.6.2.tar.gz
得到/home/hadoop/hadoop-2.6.2
hadoop环境变量
配置环境变量
$vi /etc/.bashrc
添加如下内容:
export HADOOP_HOME=/home/hadoop/hadoop-2.6.2
export PATH=$PATH:$HADOOP_HOME/binhadoop参数文件配置
需要配置hadoop的参数文件有:
- core-site.xml
- hdfs-site.xml
- mapred-site.xml(这个本来只有mapred-site.xml.template文件,改个名就好)
- yarn-site.xml
- hadoop-env.sh
- yarn-env.sh
- slaves
core-site.xml
hadoop.tmp.dir属性指定缓存目录,这个值可以自己指定
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.248.148:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
</configuration>hdfs-site.xml
dfs.namenode.name.dir属性指定节点名字目录
dfs.datanode.data.dir属性指定数据目录
dfs.replication属性指定slave子机个数
dfs.webhdfs.enabled属性指定是否开启网页版hdfs文件系统管理
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.248.148:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>mapred-site.xml
这里指定的是mapreduce服务的端口(用来任务调度等)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>192.168.248.148:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.248.148:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.248.148:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>192.168.248.148:9001</value>
</property>
</configuration>yarn-site.xml
资源管理resourcemanager
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop0</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.248.148:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.248.148:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.248.148:8031</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.248.148:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>hadoop-env.sh, yarn-env.sh
这两个可以不改,如果提示缺少jdk,则在这两个文件的前面加上
# The java implementation to use.
export JAVA_HOME=/usr/local/java/jdk1.8.0_40
修改slaves
这个文件说的是有哪些slave子机,也就是说,添加一台新机,只需要把hadoop-2.6.2程序包复制到新机,并配置环境变量和修改该文件就可以使用
hadoop1
hadoop2
hadoop3
格式化文件系统
每台机都进行格式化文件系统
$hadoop namenode -format
hadoop命令在~/hadoop-2.6.2/bin中
验证安装
启动进程
[hadoop@hadoop0 hadoop-2.6.2]$ sbin/hadoop-daemon.sh start namenode
[hadoop@hadoop0 hadoop-2.6.2]$ sbin/hadoop-daemon.sh start datanode
或者一次性启动
[hadoop@hadoop0 hadoop-2.6.2]$ sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [hadoop0]
hadoop0: starting namenode, logging to /home/hadoop/hadoop-2.6.2/logs/hadoop-hadoop-namenode-hadoop0.out
hadoop1: starting datanode, logging to /home/hadoop/hadoop-2.6.2/logs/hadoop-hadoop-datanode-hadoop1.out
hadoop3: starting datanode, logging to /home/hadoop/hadoop-2.6.2/logs/hadoop-hadoop-datanode-hadoop3.out
hadoop2: starting datanode, logging to /home/hadoop/hadoop-2.6.2/logs/hadoop-hadoop-datanode-hadoop2.out
Starting secondary namenodes [hadoop0]
hadoop0: starting secondarynamenode, logging to /home/hadoop/hadoop-2.6.2/logs/hadoop-hadoop-secondarynamenode-hadoop0.out
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.6.2/logs/yarn-hadoop-resourcemanager-hadoop0.out
hadoop3: starting nodemanager, logging to /home/hadoop/hadoop-2.6.2/logs/yarn-hadoop-nodemanager-hadoop3.out
hadoop2: starting nodemanager, logging to /home/hadoop/hadoop-2.6.2/logs/yarn-hadoop-nodemanager-hadoop2.out
hadoop1: starting nodemanager, logging to /home/hadoop/hadoop-2.6.2/logs/yarn-hadoop-nodemanager-hadoop1.out
查看运行报告
[hadoop@hadoop0 hadoop-2.6.2]$ jps
2547 DataNode
13363 SecondaryNameNode
13508 ResourceManager
13816 Jps
13183 NameNode
[hadoop@hadoop0 hadoop-2.6.2]$ hadoop dfsadmin -report
关闭
[hadoop@hadoop0 hadoop-2.6.2]$ sbin/stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [hadoop0]
hadoop0: stopping namenode
hadoop3: stopping datanode
hadoop2: stopping datanode
hadoop1: stopping datanode
Stopping secondary namenodes [hadoop0]
hadoop0: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
hadoop2: stopping nodemanager
hadoop1: stopping nodemanager
hadoop3: stopping nodemanager
no proxyserver to stop
本机网页管理
在本机浏览器输入地址:
http://192.168.248.148:8088/cluster
输入地址:
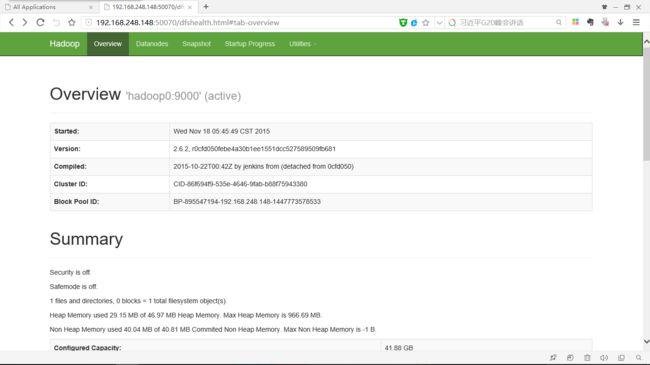
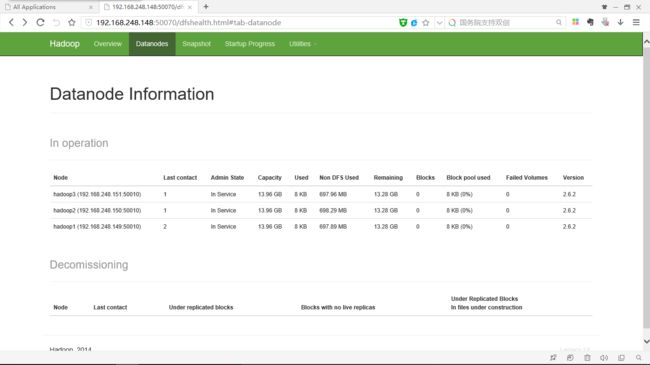
192.168.248.148:50070
出现的问题
不存在某个文件目录
这个问题是在网上的其他博客中所看到,如果出现这样的问题,使用mkdir命令创建即可
需要的目录有(在hadoop用户目录下)
~/hadoop
~/hadoop/data
~/hadoop/name
~/hadoop/tmp9000 failed on connectionexception
- 没有格式化文件系统
- name和tmp文件夹权限错误
这个问题是我自己遇到的
错误产生的原因:
在root用户下进行第一次格式化文件系统,所以导致产生的name和tmp文件夹的权限都是root用户的,以至于以后的每次格式化都是不正常的。
解决方法:
切到root用户,执行命令
#chown -R hadoop:hadoop /home/hadoop/hadoop/
参数R的意思是hadoop目录下的子目录权限也一并修改
启动hadoop时,报某个文件权限错误
产生原因:
因为我是把配置好的hadoop程序文件夹通过xftp直接复制到其他的子机中,所以导致一些文件的执行权限被修改。
解决方法:
自行添加执行权限即可,如下:
[hadoop@hadoop2 hadoop-2.6.2]$ chmod u+x /home/hadoop/hadoop-2.6.2/sbin/hadoop-daemon.sh
[hadoop@hadoop2 hadoop-2.6.2]$ chmod u+x /home/hadoop/hadoop-2.6.2/sbin/yarn-daemon.sh
[hadoop@hadoop2 hadoop-2.6.2]$ chmod u+x /home/hadoop/hadoop-2.6.2/bin/hdfs
[hadoop@hadoop2 hadoop-2.6.2]$ chmod u+x /home/hadoop/hadoop-2.6.2/bin/yar
n
参考网址:
hadoop-2.6集群安装
CentOS 下SSH无密码登录的配置
hdfs 常用端口和 hdfs-default配置文件参数的意义
Hadoop1.x完全分布模式安装