IAR的介绍
《IAR EWARM V5 嵌入式系统应用编程与开发》[ 2010-8-17 3:03:00 | By: 32446975 ]
《IAR EWARM V5 嵌入式系统应用编程与开发》![]() http://www.iartools.com/Art_Xue_ChaptShow.asp?Id=285.1.1基本选项配置
http://www.iartools.com/Art_Xue_ChaptShow.asp?Id=285.1.1基本选项配置
在工作区(Workspace)中选定一个项目,单击Project下拉菜单中的Options…选项,弹出选项配置对话框,从左边Category列表框内选择General Options进入基本选项配置。
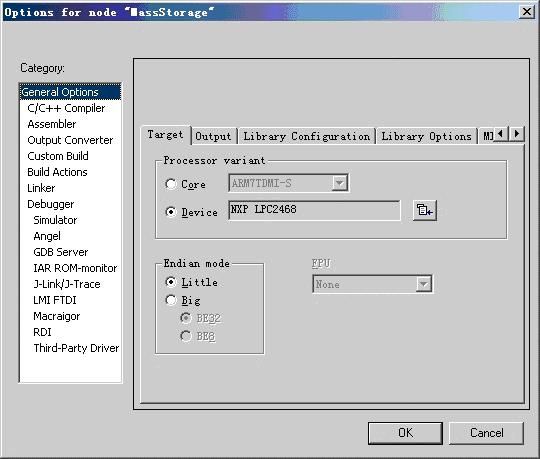
图5.1 基本选项配置中的Target选项卡
图5.1所示为基本选项配置中的Target选项卡,Processor variant(处理器类型)选项区域中的Core复选框用于设置ARM核,默认为ARM7TDMI,也可以从其左边的下拉列表框中选择其它ARM核,例如ARM9、ARM11或Xscal等。建议使用时尽可能根据当前所用ARM芯片,选中Device复选框,点击其右边的 按钮,从弹出的文本框内选择所用器件,这样IAR EWARM会根据所选芯片自动设置器件描述文件,以便于调试。如果所选ARM芯片含有浮点数协处理器,可在FPU下拉列表框内选取合适的浮点处理单元。Endian mode选项区域用于选择大小端模式,默认为Little。
图5.2所示为基本选项配置中的Output选项卡。Output file选项区域用于设置编译后生成的输出文件类型,可选择Executable(生成执行代码)或Library(生成库文件)。Output directories选项区域用于设置输出文件目录,默认执行代码文件目录为Debug\Exe,目标文件目录为Debug\Obj,列表文件目录为Debug\List,也可设置其它目录。
图5.2基本选项配置中的Output选项卡
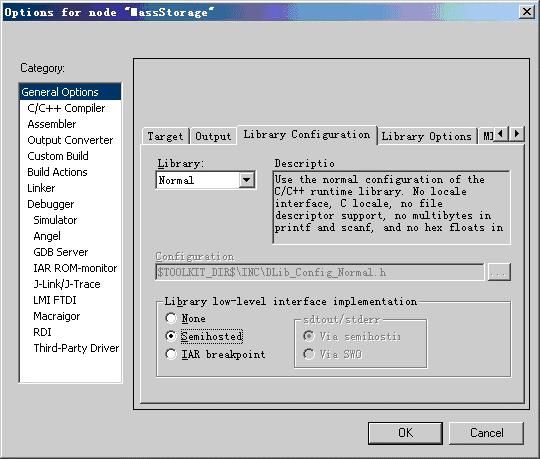
图5.3基本选项配置中的Library Configuration选项卡
图5.3所示为基本选项配置中的Library Configuration选项卡。IAR C/C++编译器提供了DLIB库,支持ISO/ANSI C和C++以及IEEE754标准的浮点数。通过Library下拉列表框选择希望采用的运行库。选择None表示应用程序不链接运行库;选择Normal表示链接普通运行库,其中没有locale接口和C locale,不支持文件描述符,printf and scanf不支持多字节操作,strtod不支持十六进制浮点数操作。选择Full表示链接完整运行库,其中包含locale接口,C locale,支持文件描述符,printf and scanf支持多字节操作,strtod支持十六进制浮点数操作。选择Custom表示链接用户自定义库,此时应在Configuration文本框内指定用户自己的库配置文件。若选择Library low-level interface implementaion选项区域中的None复选框,则在应用程序调试过程中不使用DLIB库提供的底层调试接口;若选择Semihosted或IAR breakpoint复选框,则在应用程序调试过程中使用DLIB库提供的底层调试接口,如通过Terminal I/O窗口实现输入输出等。
图5.4所示为基本选项配置中的Library Options选项卡。通过Printf formatter和Scanf formatter选项区域中的下拉列表框,可以分别设置Printf和scanf函数支持的输出和输入格式,可用格式包括Full、Large、Small和Tiny。
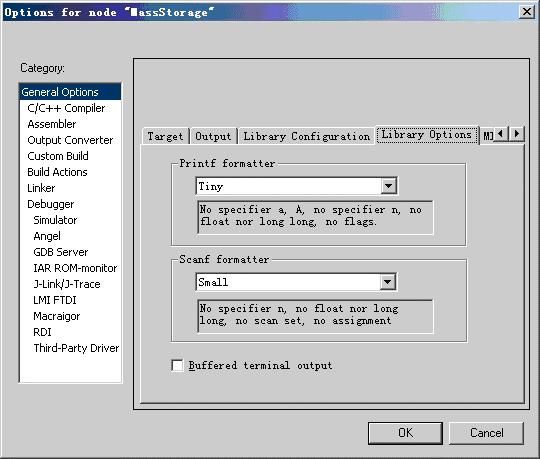
图5.4基本选项配置中的Library Options选项卡
图5.5所示为基本选项配置中的MISRA C选项卡。选择Enable MISRA C复选框后,点击All按钮选择所有MISRA C规则校验模块,点击Required按钮选择必须的MISRA C规则校验模块,点击None按钮将不选择MISRA C规则校验模块。用户还可以通过Set Active MISRA C Rules选项区域内的复选框增选或删除MISRA C规则校验模块。
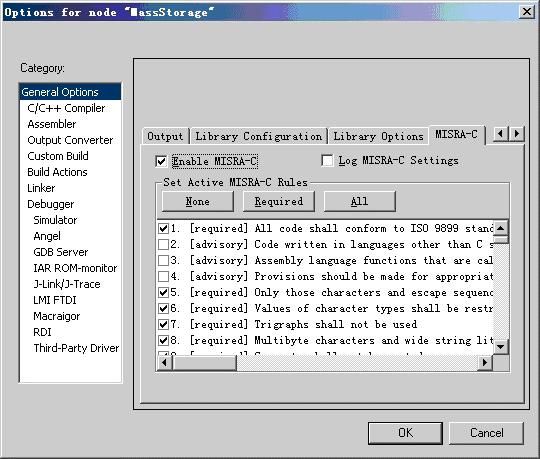
图5.5 基本选项配置中的MISRA C选项卡
5.1.2 C/C++编译器选项配置点击选项配置窗口左边Category列表框内的C/C++ Compiler选项,进入C/C++编译器选项配置,对应有多个选项卡,用于设定不同的配置选项。每个编译器选项卡的右上角都有一个Factory Settings按钮,单击该按钮将自动设置默认选项。每个编译器选项卡中还都有一个Multi-file Compilation复选框,选择该复选框,允许编译器将多个文件作为一个编译单元进行编译,从而实现各程序文件之间的交互优化,例如内联、交叉调用、交叉跳转等,若同时选择下面的Discard Unused Publics选项,则将丢弃未使用的公共变量及公共函数。
图5.6所示为编译器选项配置中的Language选项卡,其中各选项的含义及用法如下:
? Language选项区域用于设置希望采用的编程语言,默认为C。如果选择Automatic复选框,则根据源程序文件的扩展名自动选择,扩展名为“.C”时作为C源程序进行编译,扩展名为“.CPP”时作为扩展嵌入式C++源程序进行编译。?
? Require Prototypes复选框用于强制编译器检查所有函数是否具有合适的原型。调用未声明过的函数、定义未声明原型的公共函数、采用未包含原型的函数指针进行直接函数调用等都将导致编译出错。
? Language Conformance选项区域用于设置是否允许IAR C/C++语言扩展,默认为允许。选择Relaxed ISO/ANSI复选框将禁止IAR C/C++语言扩展,但并不要求严格符合ISO/ANSI标准。选择Strict ISO/ANSI将禁止IAR C/C++语言扩展,且要求严格符合ISO/ANSI标准。
? Plain ‘char’ is选项区域用于设置char类型数据的符号。通常编译器将char作为无符号类型对待,若选择Signed复选框则作为带符号类型对待。需要注意的是运行库是按无符号类型编译的,因此链接运行库时选择Signed复选框可能导致类型不匹配错误。
? 选择Enable multibyte surport复选框允许在C或C++源程序文件中使用多字节字符,默认状态下不允许在C或C++源程序文件中使用多字节字符。
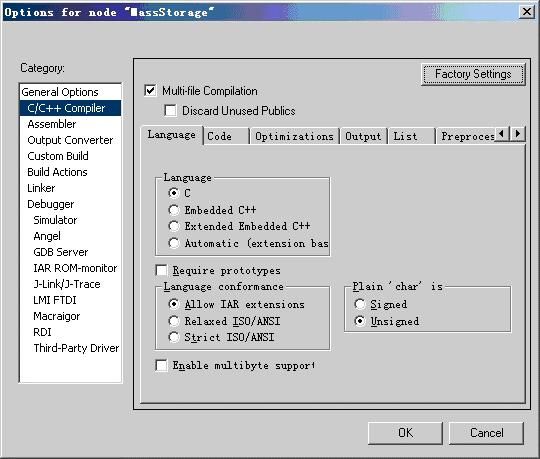
图5.6 编译器选项配置中的Language选项卡
图5.7所示为编译器选项配置中的Code选项卡,选择Generate interwork code复选框可在编译时生成ARM及Thumb混合代码,并且可以调用混合库函数。Processor mode选项区域用于选择处理器模式,默认为Thumb模式。
图5.7 编译器选项配置中的Code选项卡
图5.8所示为编译器选项配置中的Optimization选项卡,用于设置编译器的优化方法和优化级别。通过Level选项区域可选择不同的优化级别:None(不优化,对调试支持最好)、Low(低级优化)、Medium(中级优化)和High(高级优化);若选择的优化级别为High,还可通过下拉列表框选择Balanced(平衡)、Size(代码大小)或Speed(运行速度),来决定高级优化方法。根据所选择的优化级别,Enabled选项框内将自动选择不同的优化项目。
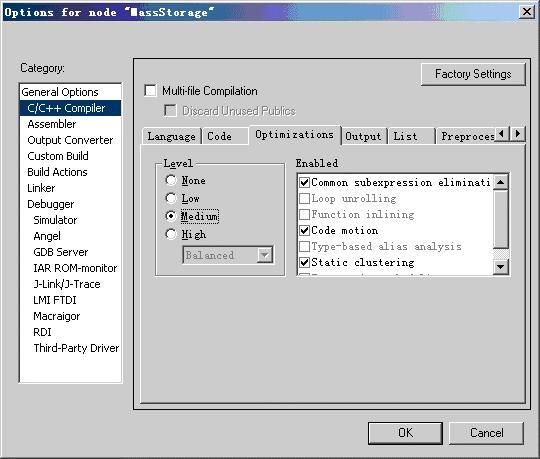
图5.8 编译器选项配置中的Optimizations选项卡
图5.9所示为编译器选项配置中的Output选项卡。选择Generate debug information复选框,将使编译器在生成的目标代码中包含适用于C-SPY和其它调试器所需要的附加信息,这会使目标代码的长度增加,若不想要这些附加信息,请不要选中该复选框。
图5.9 编译器选项配置中的Output选项卡
IAR C/C++编译器将函数代码放入指定的存储器段中,供ILINK链接器使用。默认情况下函数代码被放置在名为“.text”的存储器段中。如果不想使用默认的存储器段,可在Code section name文本框内输入以点号“.”开头的其它存储器段名,这对于希望将应用程序代码放置在不同地址范围时特别有用。采用非默认存储器段名时应特别小心,避免与编译器或链接器的默认设置发生冲突而产生错误,通常修改存储器段名之后还需要修改相应的链接器配置文件。
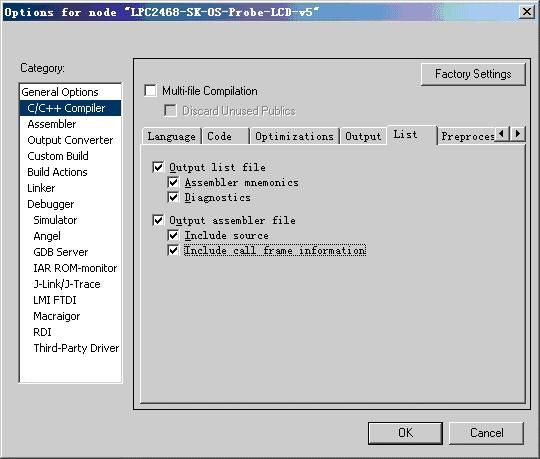
图5.10 编译器选项配置中的List选项卡
图5.10所示为编译器选项配置中的List选项卡,用于设置是否生成列表文件,以及列表文件所包含的信息。编译器默认为不生成列表文件。选择Output list file方形复选框将生成输出列表文件,Assembler mnemonics圆形复选框规定列表文件中包含汇编指令助记符,Diagnostics圆形复选框规定列表文件中包含诊断信息。
选择Output assembler file方形复选框将生成输出汇编文件,Include source圆形复选框规定汇编文件中包含源代码,Include call information圆形复选框规定汇编文件中包含编译器生成的运行模块属性、调用帧以及帧大小等信息。
列表文件以“.lst”作为扩展名,存放在List目录下。用户可以通过工作区窗口的Output目录打开列表文件。
图5.11所示为编译器选项配置中的Preprocessor选项卡,用于符号定义以及规定包含文件所在的目录路径。选项卡中各项的含义及用法如下:
? 若选择Ignore standard include directory复选框,在对项目进行创建时将不使用标准包含文件。
? Additional include directories文本框用于添加包含文件路径。添加时应输入包含文件所在的完整路径名,可以采用参数变量,当前项目所在路径为“$PROJ_DIR$”,IAR EWARM软件的安装目录路径为“$TOOLKIT_DIR$”。
? Preinclude文本框用于指定编译器读入源文件之前的包含文件,这对于源代码中某处的整体修改特别有用,如定义某个新符号等。
? Defined symbols文本框用于指定原本应在源程序文件中定义的符号,直接在文本框内输入希望定义的符号即可,该选项的作用与在源程序文件开始处使用#define语句相同。
默认状态下编译器不生成预处理器输出文件,若希望生成预处理器输出文件可以选择Preprocessor output to file复选框,同时可通过其下面的preserve comments复选框和generate #line directives复选框,决定是否在生成的预处理器输出文件中保留注释或产生行号。
图5.11 编译器选项配置中的Preprocessor选项卡
图5.12 编译器选项配置中的Diagnostics选项卡
图5.12所示为编译器选项配置中的Diagnostics选项卡,用于规定诊断信息的分类和显示。编译过程中可能产生三种错误诊断信息:remark(注意)、waining(警告)和error(错误)。remark是一种次要的诊断信息,表明按源程序结构生成的代码可能出现不正常。warning表示源程序中存在错误,但编译过程不会停止。error表示源程序中存在违反C/C++语言规则的现象,将导致无法生成目标代码。error信息不能被禁止,也不能重新分类。Diagnostics选项卡中各项的含义及用法如下:
? 编译器在默认状态不产生remark诊断信息,若选择Enable remarks复选框则允许编译器产生remark诊断信息。
? Suppress these diagnostics文本框用于设定禁止输出诊断信息的标签记号,例如希望禁止waining信息Pe117和Pe177,直接在文本框内输入“Pe117,Pe177”即可。
? Treat these as remarks文本框用于将一些诊断信息作为remark处理,例如希望将waining信息Pe177作为remark处理,直接在文本框内输入“Pe177”即可。
? Treat these as wainings文本框用于将一些诊断信息作为waining处理,例如希望将remark信息Pe826作为waining处理,直接在文本框内输入Pe826即可。
? Treat these as errors文本框用于将一些诊断信息作为error处理,例如希望将waining信息Pe117作为error处理,直接在文本框内输入Pe117即可。
? 若选中Treat all warnings as errors复选框,编译器将所有waining都作为error处理。
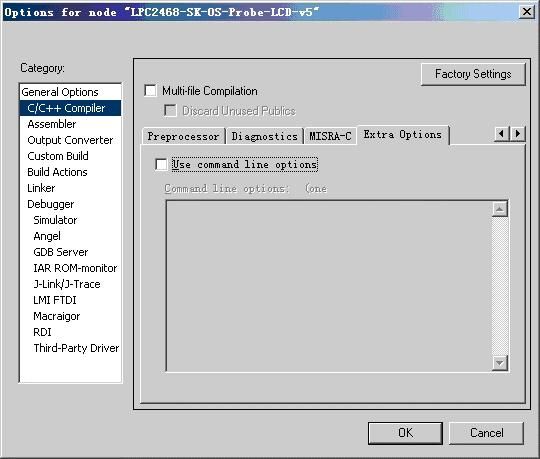
图5.13 编译器选项配置中的Extra Options选项卡
IAR C/C++编译器的大多数命令都可以通过前面介绍的配置选项卡直接设置,还有一些命令则需要通过如图5.13所示的Extra Options选项卡进行设置。先在选项卡中选择Use command line options复选框,然后直接在下面文本框内逐行输入命令选项。
命令选项可以使用短名或长名,某些选项同时使用短名和长名。短名选项由1个短划线开始,后面跟一个单字符组成,如-e、-z等。长名选项由2个短划线开始,后面跟单个字符或多个字符组成,如--char_is_signed。
命令选项还可以带有参数,如-z3、--diagnostics_tables=文件名 等。
表5-1列出了需要通过如图5.13所示Extra Options选项卡进行设置的IAR C/C++编译器命令选项。
表5-1 需要通过Extra Options选项卡进行设置的IAR C/C++编译器命令选项
命令选项 语法 说明 --aapcs --aapcs={std|vfp} 指定调用协议。可用参数如下:
std 函数调用时的浮点参数及返回值将使用CPU寄存器。
vfp 函数调用时将使用VFP寄存器,采用vfp参数所生成的代码与AEBI代码不兼容。 --aeabi --aeabi 生成遵从AEABI协议的目标代码 --dependencies --dependencies[=[i|m]]
{文件名|目录} 生成一个输出文件,其中列出了编译过程所打开的头文件。可用参数如下:
i 仅列出文件名。
m 以makefile风格列出文件名。 --diagnostics_tables --diagnostics_tables {文件名|目录} 在指定文件中列出所有可能的诊断信息。不能与其它命令一起使用。 --enum_is_int --enum_is_int 该命令强制所有枚举类型至少为4字节。 --error_limit --error_limit=n 规定在停止编译之前允许的error数量。可用参数如下:
n 停止编译之前允许的error数量,0为无限制,默认值为100。 -f -f 文件名 使编译器从指定文件中读取命令选项,指定文件的扩展名为".xcl” --header_context --header_context 为每条诊断信息列出发生问题的源程序位置,以及该位置处的整个包含堆栈信息 --legacy --legacy={RVCT3.0} 生成可用于RVCT3.0.链接器的目标代码,可与--aeabi命令一起使用 --no_guard_calls --no_guard_calls 删除由--aeabi命令导致编译器生成的为保护静态变量不被初始化的额外库调用。若要遵从AEABI协议,则不能使用该命令 --no_path_in_file_macros --no_path_in_file_macros 在__FILE__及__BASE_FILE__预处理器符号生成的返回值中不包含路径信息 --no_typedefs_in_diagnostics --no_typedefs_in_diagnostics 该命令禁止在诊断信息中使用typedef名 --no_unaligned_access --no_unaligned_access 该命令使编译器避免对数据的非对齐访问(unaligned accesses) --no_warnings --no_warnings 禁止生成warning信息 --no_wrap_diagnostics --no_wrap_diagnostics 禁止诊断信息自动换行 -o
--output -o {文件名|目录}
--output {文件名|目录} 指定输出代码文件名。默认为源文件名+".o”扩展名 --only_stdout --only_stdout 编译器仅采用标准输出流(stdout) --predef_macros --predef_macros {文件名|目录} 在指定的文件或目录中列出预定义符号 --public_equ --public_equ symbol[=value] 该命令与汇编语言中的EQU等效,可多次应用。可用参数如下:
symbol 希望定义的汇编符号。
value 汇编符号的定义值。 --separate_cluster_for_initialized_variables --separate_cluster_for_initialized_variables 该命令使变量群中的初始化与非初始化变量分开 --silent --silent 编译器工作时不向标准输出流(屏幕)发送介绍和统计信息 --warnings_affect_exit_code --warnings_affect_exit_code 该命令将使得warnings也会产生non-zero退出代码