Spark SQL系列------1. Spark SQL 物理计划的Shuffle实现
Spark SQL物理计划要到Spark-core执行,需要将Spark SQL物理计划转化成RDD,并且建立RDD之间的依赖关系。这个过程可以通过如下图大概表示:
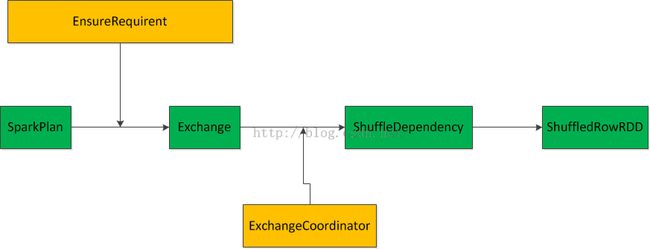
上图中绿色部分指Spark物理计划到RDD过程中数据结构的变迁过程。黄色部分表示变迁过程中,起加工作用的数据结构。
一:从SparkPlan到Exchange
优化后的Spark SQL物理计划对数据Distribution有一定的要求。当当前物理计划的Child输出数据的Distribution达不到要求的时候需要进行Shuffle,使得Child物理计划输出数据Distribution达到要求,Exchange就是如何进行Shuffle的描述。Exchange中会描述ShuffleDependency如何创建,以及如何根据ShuffleDependency创建ShuffledRowRDD。
EnsureRequirement.ensureDistributionAndOrdering描述了如何将Spark物理计划加工成Exchange.
物理计划需要转换成Exchange有一下几个原因:
1.child物理计划的输出数据分布不satisfies当前物理计划的数据分布要求。比如说child物理计划的数据输出分布是UnspecifiedDistribution,而当前物理计划的数据分布要求是ClusteredDistribution
2.对于包含2个Child物理计划的情况,2个Child物理计划的输出数据有可能不compatile。因为涉及到两个Child物理计划采用相同的Shuffle运算方法才能够保证在本物理计划执行的时候一个分区的数据在一个节点,所以2个Child物理计划的输出数据必须采用compatile的分区输出算法。如果不compatile需要创建Exchange替换掉Child物理计划。
二:从Exchange到ShuffledRowRDD
从Exchange到ShffleDependency有2中方式:
1.直接执行Exchange.prepareShuffleDependency,创建ShuffleDependency,然后根据ShuffleDependency创建ShuffledRowRDD。这种情况下的ShuffledRowRDD每个分区id和Exchange1和Exchange2 Shuffle后数据分区之间是一一对应的映射关系。如下例图所示:
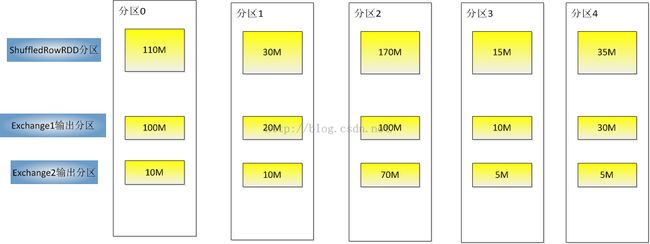
2.如果需要ExchangeCoordinator协调ShuffledRowRDD的分区,则需要先提交ExchangeCoordinator对应的所有Exchange到spark-core执行Shuffle,得到Shuffle后数据分区情况,确定ShuffledRowRDD的分区和Exchange产生的分区的映射关系,可能是1对多的映射关系。
假设规定ShuffledRowRDD一个分区最小为128M,则ShuffledRowRDD的分区情况如下例图所示:
关于物理计划的Shuffle实现的几个问题:
Q:什么时候会使用ExchangeCoordinator协调ShuffledRowRDD的分区?
A:需要满足如下条件之一,
1. spark.sql.adaptive.enabled配置为true(默认为false) ,当前物理物理有2个Child,每个Child物理计划都不是Exchange类型,每个Child的输出Distribution是ClusteredDistribution(HashPartitioning分区算法实现)。
2.spark.sql.adaptive.enabled配置为true(默认为false) ,当前物理计划中存在至少一个Child是Exchange类型,那么所有的Child的输出分区算法都是HashPartitioning