java集合类深入分析之TreeMap/TreeSet篇
TreeMap和TreeSet算是java集合类里面比较有难度的数据结构。和普通的HashMap不一样,普通的HashMap元素存取的时间复杂度一般是O(1)的范围。而TreeMap内部对元素的操作复杂度为O(logn)。虽然在元素的存取方面TreeMap并不占优,但是它内部的元素都是排序的,当需要查找某些元素以及顺序输出元素的时候它能够带来比较理想的结果。可以说,TreeMap是一个内部元素排序版的HashMap。这里会对TreeMap内部的具体实现机制和它所基于的红黑树做一个详细的介绍。另外,针对具体jdk里面TreeMap的详细实现,这里也会做详细的分析。
TreeMap和TreeSet之间的关系
和前面一篇文章类似,这里比较有意思的地方是,似乎有Map和Set的地方,Set几乎都成了Map的一个马甲。此话怎讲呢?在前面一篇讨论HashMap和HashSet的详细实现讨论里,我们发现HashSet的详细实现都是通过封装了一个HashMap的成员变量来实现的。这里,TreeSet也不例外。我们先看部分代码:
里面声明了成员变量:
- private transient NavigableMap<E,Object> m;
这里NavigableMap本身是TreeMap所实现的一个接口。我们再看下面和构造函数相关的实现:
- TreeSet(NavigableMap<E,Object> m) {
- this.m = m;
- }
- public TreeSet() { // 无参数构造函数
- this(new TreeMap<E,Object>());
- }
- public TreeSet(Comparator<? super E> comparator) { // 包含比较器的构造函数
- this(new TreeMap<>(comparator));
- }
- public TreeSet(Collection<? extends E> c) {
- this();
- addAll(c);
- }
- public TreeSet(SortedSet<E> s) {
- this(s.comparator());
- addAll(s);
- }
- public boolean addAll(Collection<? extends E> c) {
- // Use linear-time version if applicable
- if (m.size()==0 && c.size() > 0 &&
- c instanceof SortedSet &&
- m instanceof TreeMap) {
- SortedSet<? extends E> set = (SortedSet<? extends E>) c;
- TreeMap<E,Object> map = (TreeMap<E, Object>) m;
- Comparator<? super E> cc = (Comparator<? super E>) set.comparator();
- Comparator<? super E> mc = map.comparator();
- if (cc==mc || (cc != null && cc.equals(mc))) {
- map.addAllForTreeSet(set, PRESENT);
- return true;
- }
- }
- return super.addAll(c);
- }
这里构造函数相关部分的代码看起来比较多,实际上主要的构造函数就两个,一个是默认的无参数构造函数和一个比较器构造函数,他们内部的实现都是使用的TreeMap,而其他相关的构造函数都是通过调用这两个来实现的,故其底层使用的就是TreeMap。既然TreeSet只是TreeMap的一个马甲,我们就只要重点关注一下TreeMap里面的实现好了。
红黑树(Red-Black Tree)
红黑树本质上是一棵一定程度上相对平衡的二叉搜索树。为什么这么说呢?我们从前面讨论二叉搜索树的文章中可以看到。一棵二叉搜索树理想情况下的搜索和其他元素操作的时间复杂度是O(logn)。但是,这是基于一个前提,即二叉搜索树本身构造出来的树是平衡的。如果我们按照普通的插入一个元素就按照二叉树对应关系去摆的话,在一些极端的情况下会失去平衡。比如说我们通过插入一个顺序递增或者递减的一组元素,那么最后的结构就相当于一个双向链表。对其中元素的访问也不可能达到O(logn)这样的级别。
所以,在这样的情况下,我们就希望有那么一种机制或者数据结构能够保证我们既能构造出一棵二叉搜索树来,而且它天生就是平衡的。这样就有了红黑树。当然,为了同时达到这两个目标,红黑树设定了一些特定的属性限制,也使得它本身的实现比较复杂。我们在下面的定义中就可以看到。
红黑树的官方定义如下:
红黑树是一种二叉树,同时它还满足下列5个特性:
1. 每个节点是红色或者黑色的。
2. 根节点是黑色的。
3. 每个叶节点是黑色的。(这里将叶节点的左右空子节点作为一个特殊的节点对待,设定他们必须是黑色的。)
4. 如果一个节点是红色的,则它的左右子节点都必须是黑色的。
5. 对任意一个节点来说,从它到叶节点的所有路径必须包含相同数目的黑色节点。
这部分的定义看得让人有点不知所云,我们先看一个红黑树的示例:
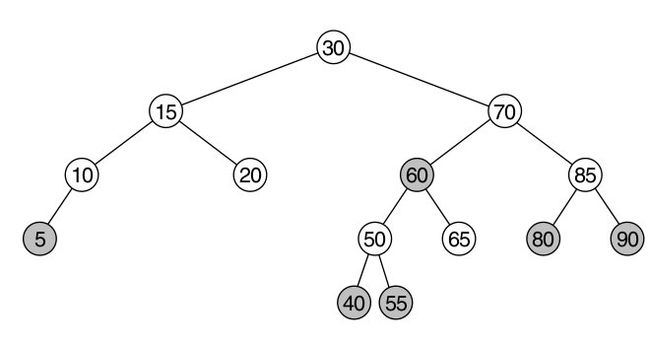
假定其中带阴影的节点为红色节点,则上图为一棵红黑树。假定我们取根节点来考察,它到任意一个叶节点要走过3个黑色的节点。这样,从任意一个节点到叶节点只需要经历过的黑色节点相同就可以了,可以说这是一个放松了的平衡衡量标准。
节点定义
现在,结合我们前面对平衡二叉搜索树的讨论和TreeMap里面要求的特性我们来做一个分析。我们要求设计的TreeMap它的本质上也是一个Map,那么它意味着对任意一个名值对,我们都需要保存在数据结构里面。对于一个名值对来说,key的作用就是用来寻址的。在HashMap里面,key是通过hash函数运算直接映射到对应的slot,这里则是通过查找比较放到一棵二叉树里一个合适的位置。这个位置则相当于一个slot。所以我们的节点里面必须有一个key,一个value。
另外,考虑到这里将节点定义成了红色和黑色,所以需要有一个保存节点颜色的属性。前面我们讨论二叉搜索树的时候讨论元素的插入和删除等操作的时候提到过,如果给每个元素增加一个指向父节点的引用,会带来极大的便利。既然红黑树也是其中一种,这种引用肯定就应该考虑了。
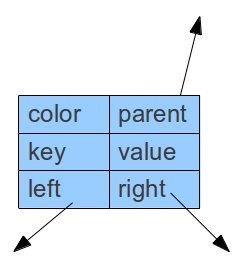
综上所述,我们的节点应该包含以下6个部分:
1. 左子节点引用
2. 右子节点引用
3. 父节点引用
4. key
5. value
6. color
这一个结构相当于一个如下的图:
在jdk的实现里,它的定义如下:
- static final class Entry<K,V> implements Map.Entry<K,V> {
- K key;
- V value;
- Entry<K,V> left = null;
- Entry<K,V> right = null;
- Entry<K,V> parent;
- boolean color = BLACK;
- /**
- * Make a new cell with given key, value, and parent, and with
- * {@code null} child links, and BLACK color.
- */
- Entry(K key, V value, Entry<K,V> parent) {
- this.key = key;
- this.value = value;
- this.parent = parent;
- }
- // ... Ignored
- }
它是被定义为Entry的内部类。
添加元素
添加元素的过程可以大致的分为两个步骤。和前面的二叉搜索树类似,我们添加元素也是需要通过比较元素的值,找到添加元素的地方。这部分基本上没有什么变化。第二步则是一个调整的过程。因为红黑树不一样,当我们添加一个新的元素之后可能会破坏它固有的属性。主要在于两个地方,一个是要保证新加入元素后,到所有叶节点的黑色节点还是一样的。另外也要保证红色节点的子节点为黑色节点。
还有一个就是,结合TreeMap的map特性,我们添加元素的时候也可能会出现新加入的元素key已经在数中间存在了,那么这个时候就不是新加入元素,而是要更新原有元素的值。
结合前面提到的这几个大的思路,我们来看看添加元素的代码:
- public V put(K key, V value) {
- Entry<K,V> t = root;
- if (t == null) {
- compare(key, key); // type (and possibly null) check
- root = new Entry<>(key, value, null);
- size = 1;
- modCount++;
- return null;
- }
- int cmp;
- Entry<K,V> parent;
- // split comparator and comparable paths
- Comparator<? super K> cpr = comparator;
- if (cpr != null) {
- do {
- parent = t;
- cmp = cpr.compare(key, t.key);
- if (cmp < 0)
- t = t.left;
- else if (cmp > 0)
- t = t.right;
- else
- return t.setValue(value);
- } while (t != null);
- }
- else {
- if (key == null)
- throw new NullPointerException();
- Comparable<? super K> k = (Comparable<? super K>) key;
- do {
- parent = t;
- cmp = k.compareTo(t.key);
- if (cmp < 0)
- t = t.left;
- else if (cmp > 0)
- t = t.right;
- else
- return t.setValue(value);
- } while (t != null);
- }
- Entry<K,V> e = new Entry<>(key, value, parent);
- if (cmp < 0)
- parent.left = e;
- else
- parent.right = e;
- fixAfterInsertion(e);
- size++;
- modCount++;
- return null;
- }
上述的代码看起来比较多,不过实际上并不复杂。第3到9行主要是判断在根节点为null的情况下,我们的put方法相当于直接创建一个节点并关联到根节点。后面的两个大的if else块是用来判断是否设定了comparator的情况下的比较和加入元素操作。对于一些普通的数据类型,他们默认实现了Comparable接口,所以我们用compareTo方法来比较他们。而对于一些自定义实现的类,他们的比较关系在一些特殊情况下需要实现Comparator接口,这就是为什么前面要针对这两个部分要进行区分。在这两个大的块里面主要做的就是找到要添加元素的地方,如果有相同key的情况,则直接替换原来的value。
第42行及后面的部分需要处理添加元素的情况。如果在前面的循环块里面没有找到对应的Key值,则说明已经找到了需要插入元素的位置,这里则要在这个地方加入进去。添加了元素之后,基本上整个过程就结束了。
这里有一个方法fixAfterInsertion(),在我们前面的讨论中提到过。每次当我们插入一个元素的时候,我们添加的元素会带有一个颜色,而这个颜色不管是红色或者黑色都可能会破坏红黑树定义的属性。所以,这里需要通过一个判断调整的过程来保证添加了元素后整棵树还是符合要求的。这部分的过程比较复杂,我们拆开来详细的一点点讲。
在看fixAfterInsertion的实现之前,我们先看一下树的左旋和右旋操作。这个东西在fixAfterInsertion里面用的非常多。
旋转
树的左旋和右旋的过程用一个图来表示比较简单直观:

从图中可以看到,我们的左旋和右旋主要是通过交换两个节点的位置,同时将一个节点的子节点转变为另外一个节点的子节点。具体以左旋为例,在旋转前,x是y的父节点。旋转之后,y成为x的父节点,同时y的左子节点成为x的右子节点。x原来的父节点成为后面y的父节点。这么一通折腾过程就成为左旋了。同理,我们也可以得到右旋的过程。
左旋和右旋的实现代码如下:
- private void rotateLeft(Entry<K,V> p) {
- if (p != null) {
- Entry<K,V> r = p.right;
- p.right = r.left;
- if (r.left != null)
- r.left.parent = p;
- r.parent = p.parent;
- if (p.parent == null)
- root = r;
- else if (p.parent.left == p)
- p.parent.left = r;
- else
- p.parent.right = r;
- r.left = p;
- p.parent = r;
- }
- }
- private void rotateRight(Entry<K,V> p) {
- if (p != null) {
- Entry<K,V> l = p.left;
- p.left = l.right;
- if (l.right != null) l.right.parent = p;
- l.parent = p.parent;
- if (p.parent == null)
- root = l;
- else if (p.parent.right == p)
- p.parent.right = l;
- else p.parent.left = l;
- l.right = p;
- p.parent = l;
- }
- }
这部分的代码结合前面的图来看的话就比较简单。主要是子节点的移动和判断父节点并调整。有点像双向链表中间调整元素。
调整过程
我们知道,在红黑树里面,如果加入一个黑色节点,则导致所有经过这个节点的路径黑色节点数量增加1,这样就肯定破坏了红黑树中到所有叶节点经过的黑色节点数量一样的约定。所以,我们最简单的办法是先设置加入的节点是红色的。这样就不会破坏这一条约定。但是,这样的调整也会带来另外一个问题,如果我这个要加入的节点它的父节点已经是红色的了呢?这岂不是又破坏了原来的约定吗?是的,在这种情况下,我们就要通过一系列的调整来保证最终它成为一棵合格的红黑树。但是这样比我们加入一个黑色节点然后去调整相对来说范围要狭窄一些。现在我们来看看怎么个调整法。
我们假设要添加的节点为N。
场景1: N节点的父节点P以及P的兄弟节点都是红色,而它的祖父节点G为黑色
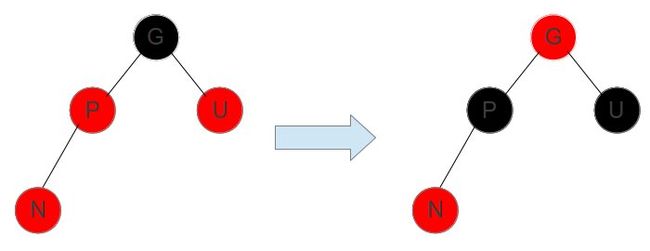
在这种情况下,只要将它的父节点P以及节点U设置为黑色,而祖父节点G设置为红色。这样就保证了任何通过G到下面的叶节点经历的黑色节点还是和原来一样,为1.而且也保证了红色节点的子节点不为红色。这种场景的一个前提是只要保证要添加的节点和它的父节点以及父节点的兄弟节点都是红色,则通过同样的手法进行转换。这和加入的节点是父节点的左右子节点无关。
场景2: N节点的父节点P是红色,但是它的祖父节点G和它父节点的兄弟节点U为黑色。
这种情形实际上还取决于要插入的元素N的位置,如果它是P的右子节点,则先做一个左旋操作,转换成右边的情形。这样,新加入的节点保证成为父节点的左子节点。

在上图做了这么一种转换之后,我们还需要做下一步的调整,如下图:
这一步是通过将P和G的这一段右旋,这样G则成为了P的右子节点。然后再将P的颜色变成黑色,G的颜色变成红色。这样就保证新的这一部分子树还是包含相同的黑色子节点。
前面我们对这两种情况的讨论主要涵盖了这么一种大情况,就是假设我们新加入节点N,它的父节点P是祖父节点G的左子节点。在这么一个大前提下,我们再来想想前面的这几种场景是否已经足够完备。我们知道,这里需要调整的情况必然是新加入的节点N和父节点P出现相同颜色也就是红色的情况。那么,在他们同时是红色而且父节点P是祖父节点G的左子节点的情况下,P的兄弟节点只有两种可能,要么为红色,要么为黑色。这两种情况正好就是我们前面讨论的图所涵盖的。
如果父节点P作为祖父节点G的右子节点,则情况和作为左子节点的情况对称。我们可以按照类似的方法来处理。
- private void fixAfterInsertion(Entry<K,V> x) {
- x.color = RED;
- while (x != null && x != root && x.parent.color == RED) {
- if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
- Entry<K,V> y = rightOf(parentOf(parentOf(x))); // 取当前节点的叔父节点
- if (colorOf(y) == RED) { //叔父节点也为红色,则满足第一种情况: 将父节点和叔父节点设置为黑色,祖父节点为红色。
- setColor(parentOf(x), BLACK);
- setColor(y, BLACK);
- setColor(parentOf(parentOf(x)), RED);
- x = parentOf(parentOf(x));
- } else {
- if (x == rightOf(parentOf(x))) { // 第二种情况中,节点是父节点的右子节点,所以先左旋一下
- x = parentOf(x);
- rotateLeft(x);
- }
- setColor(parentOf(x), BLACK); // 第二种情况,父节点和祖父节点做一个右旋操作,然后父节点变成黑色,祖父节点变成红色
- setColor(parentOf(parentOf(x)), RED);
- rotateRight(parentOf(parentOf(x)));
- }
- } else {
- Entry<K,V> y = leftOf(parentOf(parentOf(x)));
- if (colorOf(y) == RED) {
- setColor(parentOf(x), BLACK);
- setColor(y, BLACK);
- setColor(parentOf(parentOf(x)), RED);
- x = parentOf(parentOf(x));
- } else {
- if (x == leftOf(parentOf(x))) {
- x = parentOf(x);
- rotateRight(x);
- }
- setColor(parentOf(x), BLACK);
- setColor(parentOf(parentOf(x)), RED);
- rotateLeft(parentOf(parentOf(x)));
- }
- }
- }
- root.color = BLACK;
- }
前面代码中while循环的条件则是判断当前节点是否有父节点,而且父节点的颜色和它是否同样为红色。我们默认加入的元素都设置成红色。我在代码里把父节点是祖父节点左孩子的情况做了注释。另外一种情况也可以依葫芦画瓢的来分析。
删除元素
删除元素的过程和普通二叉搜索树的搜索过程大体也比较类似,首先是根据待删除节点的情况进行分析:
1. 待删除节点没有子节点, 则直接删除该节点。如下图:

2. 待删除节点有一个子节点,则用该子节点替换它的父节点:

3. 待删除节点有两个子节点,则取它的后继节点替换它,并删除这个后继节点原来的位置。它可能有两种情况:


这几种情况就是二叉搜索树里面删除元素的过程。这里就不再赘述。我们主要看红黑树有些不一样的地方。下面是删除方法实现的主要代码:
- private void deleteEntry(Entry<K,V> p) {
- modCount++;
- size--;
- // If strictly internal, copy successor's element to p and then make p
- // point to successor.
- if (p.left != null && p.right != null) {
- Entry<K,V> s = successor(p);
- p.key = s.key;
- p.value = s.value;
- p = s;
- } // p has 2 children
- // Start fixup at replacement node, if it exists.
- Entry<K,V> replacement = (p.left != null ? p.left : p.right);
- if (replacement != null) {
- // Link replacement to parent
- replacement.parent = p.parent;
- if (p.parent == null)
- root = replacement;
- else if (p == p.parent.left)
- p.parent.left = replacement;
- else
- p.parent.right = replacement;
- // Null out links so they are OK to use by fixAfterDeletion.
- p.left = p.right = p.parent = null;
- // Fix replacement
- if (p.color == BLACK)
- fixAfterDeletion(replacement);
- } else if (p.parent == null) { // return if we are the only node.
- root = null;
- } else { // No children. Use self as phantom replacement and unlink.
- if (p.color == BLACK)
- fixAfterDeletion(p);
- if (p.parent != null) {
- if (p == p.parent.left)
- p.parent.left = null;
- else if (p == p.parent.right)
- p.parent.right = null;
- p.parent = null;
- }
- }
- }
第7到12行代码就是判断和处理待删除节点如果有两个子节点的情况。通过找到它的后继节点,然后将后继节点的值覆盖当前节点。这一步骤完成之后,后续的就主要是将原来那个后继节点删除。第15行及以后的代码主要就是处理删除这个节点的事情。当然,考虑到红黑树的特性,这里有两个判断当前待删除节点是否为黑色的地方。我们知道,如果当前待删除节点是红色的,它被删除之后对当前树的特性不会造成任何破坏影响。而如果被删除的节点是黑色的,这就需要进行进一步的调整来保证后续的树结构满足要求。这也就是为什么里面需要调用fixAfterDeletion这个方法。
删除后的调整
删除元素之后的调整和前面的插入元素调整的过程比起来更复杂。它不是一个简单的在原来过程中取反。我们先从一个最基本的点开始入手。首先一个,我们要进行调整的这个点肯定是因为我们要删除的这个点破坏了红黑树的本质特性。而如果我们删除的这个点是红色的,则它肯定不会破坏里面的属性。因为从前面删除的过程来看,我们这个要删除的点是已经在濒临叶节点的附近了,它要么有一个子节点,要么就是一个叶节点。如果它是红色的,删除了,从上面的节点到叶节点所经历的黑色节点没有变化。所以,这里的一个前置条件就是待删除的节点是黑色的。
在前面的那个前提下,我们要调整红黑树的目的就是要保证,这个原来是黑色的节点被删除后,我们要通过一定的变化,使得他们仍然是合法的红黑树。我们都知道,在一个黑色节点被删除后,从上面的节点到它所在的叶节点路径所经历的黑色节点就少了一个。我们需要做一些调整,使得它少的这个在后面某个地方能够补上。
ok,有了这一部分的理解,我们再来看调整节点的几种情况。
1. 当前节点和它的父节点是黑色的,而它的兄弟节点是红色的:

这种情况下既然它的兄弟节点是红色的,从红黑树的属性来看,它的兄弟节点必然有两个黑色的子节点。这里就通过节点x的父节点左旋,然后父节点B颜色变成红色,而原来的兄弟节点D变成黑色。这样我们就将树转变成第二种情形中的某一种情况。在做后续变化前,这棵树这么的变化还是保持着原来的平衡。
2. 1) 当前节点的父节点为红色,而它的兄弟节点,包括兄弟节点的所有子节点都是黑色。
在这种情况下,我们将它的兄弟节点设置为红色,然后x节点指向它的父节点。这里有个比较难以理解的地方,就是为什么我这么一变之后它就平衡了呢?因为我们假定A节点是要调整的节点一路调整过来的。因为原来那个要调整的节点为黑色,它一旦被删除就路径上的黑色节点少了1.所以这里A所在的路径都是黑色节点少1.这里将A的兄弟节点变成红色后,从它的父节点到下面的所有路径就都统一少了1.保证最后又都平衡了。
当然,大家还会有一个担忧,就是当前调整的毕竟只是一棵树中间的字数,这里头的节点B可能还有父节点,这么一直往上到根节点。你这么一棵字数少了一个黑色节点,要保证整理合格还是不够的。这里在代码里有了一个保证。假设这里B已经是红色的了。那么代码里那个循环块就跳出来了,最后的部分还是会对B节点,也就是x所指向的这个节点置成黑色。这样保证前面亏的那一个黑色节点就补回来了。
2) 当前节点的父节点为黑色,而它的兄弟节点,包括兄弟节点的所有子节点都是黑色。
这种情况和前面比较类似。如果接着前面的讨论来,在做了那个将兄弟节点置成红色的操作之后,从父节点B开始的所有子节点都少了1.那么这里从代码中间看的话,由于x指向了父节点,仍然是黑色。则这个时候以父节点B作为基准的子树下面都少了黑节点1. 我们就接着以这么一种情况向上面推进。
3. 当前节点的父节点为红色,而它的兄弟节点是黑色,同时兄弟节点有一个节点是红色。

这里所做的操作就是先将兄弟节点做一个右旋操作,转变成第4种情况。当然,前面的前提是B为红色,在B为黑色的情况下也可以同样的处理。
4. 在当前兄弟节点的右子节点是红色的情况下。

这里是一种比较理想的处理情况,我们将父节点做一个左旋操作,同时将父节点B变成黑色,而将原来的兄弟节点D变成红色,并将D的右子节点变成黑色。这样保证了新的子树中间根节点到各叶子节点的路径依然是平衡的。大家看到这里也许会觉得有点奇怪,为什么这一步调整结束后就直接x = T.root了呢?也就是说我们一走完这个就可以把x直接跳到根节点,其他的都不需要看了。这是因为我们前面的一个前提,A节点向上所在的路径都是黑色节点少了一个的,这里我们以调整之后相当于给它增加了一个黑色节点,同时对其他子树的节点没有任何变化。相当于我内部已经给它补偿上来了。所以后续就不需要再往上去调整。
前面讨论的这4种情况是在当前节点是父节点的左子节点的条件下进行的。如果当前节点是父节点的右子节点,则可以对应的做对称的操作处理,过程也是一样的。
具体调整的代码如下:
- private void fixAfterDeletion(Entry<K,V> x) {
- while (x != root && colorOf(x) == BLACK) {
- if (x == leftOf(parentOf(x))) {
- Entry<K,V> sib = rightOf(parentOf(x));
- if (colorOf(sib) == RED) {
- setColor(sib, BLACK);
- setColor(parentOf(x), RED);
- rotateLeft(parentOf(x));
- sib = rightOf(parentOf(x));
- }
- if (colorOf(leftOf(sib)) == BLACK &&
- colorOf(rightOf(sib)) == BLACK) {
- setColor(sib, RED);
- x = parentOf(x);
- } else {
- if (colorOf(rightOf(sib)) == BLACK) {
- setColor(leftOf(sib), BLACK);
- setColor(sib, RED);
- rotateRight(sib);
- sib = rightOf(parentOf(x));
- }
- setColor(sib, colorOf(parentOf(x)));
- setColor(parentOf(x), BLACK);
- setColor(rightOf(sib), BLACK);
- rotateLeft(parentOf(x));
- x = root;
- }
- } else { // symmetric
- Entry<K,V> sib = leftOf(parentOf(x));
- if (colorOf(sib) == RED) {
- setColor(sib, BLACK);
- setColor(parentOf(x), RED);
- rotateRight(parentOf(x));
- sib = leftOf(parentOf(x));
- }
- if (colorOf(rightOf(sib)) == BLACK &&
- colorOf(leftOf(sib)) == BLACK) {
- setColor(sib, RED);
- x = parentOf(x);
- } else {
- if (colorOf(leftOf(sib)) == BLACK) {
- setColor(rightOf(sib), BLACK);
- setColor(sib, RED);
- rotateLeft(sib);
- sib = leftOf(parentOf(x));
- }
- setColor(sib, colorOf(parentOf(x)));
- setColor(parentOf(x), BLACK);
- setColor(leftOf(sib), BLACK);
- rotateRight(parentOf(x));
- x = root;
- }
- }
- }
- setColor(x, BLACK);
- }
其他
TreeMap的红黑树实现当然也包含其他部分的代码实现,如用于查找元素的getEntry方法,取第一个和最后一个元素的getFirstEntry, getLastEntry方法以及求前驱和后继的predecesor, successor方法。这些方法的实现和普通二叉搜索树的实现没什么明显差别。这里就忽略不讨论了。这里还有一个有意思的方法实现,就是buildFromSorted方法。它的实现过程并不复杂,不过经常被作为面试的问题来讨论。后续文章也会针对这个小问题进行进一步的讨论。
总结
在一篇文章里光要把红黑树的来龙去脉折腾清楚就挺麻烦的,如果还要针对它的一个具体jdk的实现代码进行分析的话,这个话题就显得比较大了。不过一开始就结合优秀的实现代码来学习这个数据结构的话,对于自己体会其中的思想和锻炼编程的功力还是很有帮助的。TreeMap里面实现得最出彩的地方还是红黑树的部分,当然,还有其他一两个比较有意思的方法,其问题还经常被作为一些面试的问题来讨论,后续的文章也会针对这部分进行一些分析。