Hadoop单机安装测试
1 设置为普通用户
安装hadoop最好在普通用户下,不要用超级用户。(第一步:useradd -d /home/john john,第二部:passwd john 123456)
2 配置本机的hosts
方便后续使用,这个hosts,root用户才可以改。
增加: 127.0.0.1 hagrid01
3 一定要安装好了jdk
4 下载解压编译好的hadoop
查看本机的位数,下载对应的hadoop的版本
getconf LONG_BIT测试版本:2.6.2
http://hadoop.apache.org/releases.html
找一个镜像:
一个是源码包,一个是编译好的包
wget http://apache.fayea.com/hadoop/common/hadoop-2.6.2/hadoop-2.6.2-src.tar.gz
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.6.2/hadoop-2.6.2.tar.gz如果你嫌麻烦,可以一键安装版本:
http://115.28.73.167/software/cloudera-cdh5/RPMS/x86_64/
下载CDH5 开源发行版
hadoop-2.6.0+cdh5.4.8+669-1.cdh5.4.8.p0.5.el6.x86_64.rpm
解压编译好的包就行了,如果是32位机器的话,需要通过源码包再编译一个出来,效果比较好,不过不编译的话也能用,就是有时会发警告而已。
tar -zxvf hadoop-2.6.2.tar.gz
5 修改Hadoop配置
5.1 首先修改:
./etc/hadoop/hadoop-env.sh
默认:
export JAVA_HOME=${JAVA_HOME}改为:
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.7.0_45-cloudera默认是按系统的JAVA_HOME 环境变量配置的,如果你没有配置,建议配置一下,或者不配的话一定要把这个地方直接改为java安装目录的绝对路径!如果不是root用户下安装,也需要配置为绝对路径?
查看是否已经配置了JAVA_HOME:
$JAVA_HOME
bash: /usr/java/jdk1.7.0_45-cloudera: is a directory5.2 修改mapred-site.xml,如果没有则直接创建!
增加:
表明我们的hadoop要集成yarn
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5.3 修改core-site.xml
增加property,这样就能够指定通过web访问hdfs的地址了
<property>
<name>fs.defaultFS</name>
<value>hdfs://hagird01:8020</value>
</property>5.4 修改 hdfs-site.xml
dfs.replication 指定每个block的副本数量,作为单机测试,我们只指定为一个,默认情况下是三个
dfs.namenode.name.dir 和 dfs.datanode.data.dir 指定 节点信息存放的目录,如果你用模拟器的话需要改这两个地方,默认是temp目录,如果用模拟器的话每次重启会清空temp目录,如果是服务器环境,可以保留默认值。
<property>
<name>dfs.namenode.name.dir</name>
<value>/mnt/dfs_name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/mnt/dfs_data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>要确保你部署Hadoop的用户具有/mnt的读写权限!
如果没有,则需要改别的目录了!一定要有读写权限!不然执行后续命令时,如果格式化时:
namenode format的时候相当于先执行了mkdir /mnt/dfs_name 这样一个命令
5.4 修改yarn-site.xml
这个是什么原因呢,还不清楚~~~
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>5.5 修改slaves
这个文件保存了slave节点的hosts
默认只有一个localhost ,因此单机测试可以不修改
6 启动hadoop服务
启动服务的脚本全部在 ./sbin 目录下
start-all.sh 可以启动全部的服务,不建议!这样做!
start-dfs.sh 启动DFS中的namenode 和 datanode 全部启动,不建议!这样做!
对于hdfs的启动建议一步一步的来!
6.0 注意!只有第一次配置的时候才有这一步!
格式化dfs:bin/hadoop namenode -format
成功信息:
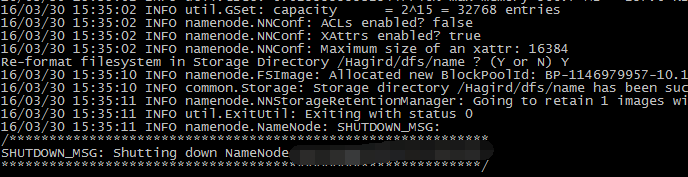
6.1 先启动namenode
~/hadoop-2.6.2/sbin/hadoop-daemon.sh start namenode用 jps 命令查看是否有namenode 的进程
如果没有,查看
vi ~/hadoop-2.6.2/logs/hadoop-Hagrid01-namenode-nxxx01.log看到log记录
或者稍等一会,因为启动的可能比较慢!
6.2 启动datanode
~/hadoop-2.6.2/sbin/hadoop-daemon.sh start datanode用 jps 命令查看是否有datanode 的进程
然后就可以通过Web浏览器查看dfs了!
记住默认端口号是50070
http://localhost:50070localhost可以改为外网地址,就可以通过公网访问了!
6.2.1 玩玩dfs
创建文件:
bin/hadoop fs -mkdir /home上传文件:
bin/hadoop fs -put README.txt /home6.3 启动Yarn
yarn虽然也可以一步步启动,但是没有必要,因为只要我们的hdfs启动成功,yarn一般没什么问题,
所以直接启动:
sbin/start-yarn.sh启动过程中需要输入用户的密码。
现在可以通过Web浏览器来查看yarn了!
记住默认端口号是8088
http://localhost:80886.3.1 玩玩yarn!
让hadoop计算π值!
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.2.jar pi 2 100
这是使用蒙托卡罗模拟采用算法计算π值,有兴趣的可以找找相关资料!
7 关闭
hdfs 和 yarn 的关闭顺序没有关系
sbin/stop-yarn.shsbin/stop-dfs.sh8 再次启动
下次再用时,就不用再配置一遍了,直接启动
sbin/start-dfs.sh //但是这样会启动 secondary namenodes, 因此不想启动的话,还是单步来吧!
sbin/start-yarn.sh就行了!
9 SSH免密码登录
本地Linux用ssh-keygen创建密钥对。
然后使用
ssh-copy-id -i /root/.ssh/id_rsa.pub root@<aliyun机器ip> 将公钥同步过去即可。