前端学习总结(九)MongoDB——最出色的文档型数据库
说到MongoDB,就必须先说清楚NoSQL,以下介绍NoSQL的部分源自百度百科。
一 NoSQL
NoSQL,泛指非关系型数据库。(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,是一项全新的数据库革命性运动,早期就有人提出,发展至2009年趋势越发高涨。NoSQL的拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
虽然NoSQL流行语火起来才短短一年的时间,但是不可否认,现在已经开始了第二代运动。尽管早期的堆栈代码只能算是一种实验,然而现在的系统已经更加的成熟、稳定。不过现在也面临着一个严酷的事实:技术越来越成熟——以至于原来很好的NoSQL数据存储不得不进行重写,也有少数人认为这就是所谓的2.0版本。这里列出一些比较知名的工具,可以为大数据建立快速、可扩展的存储库。
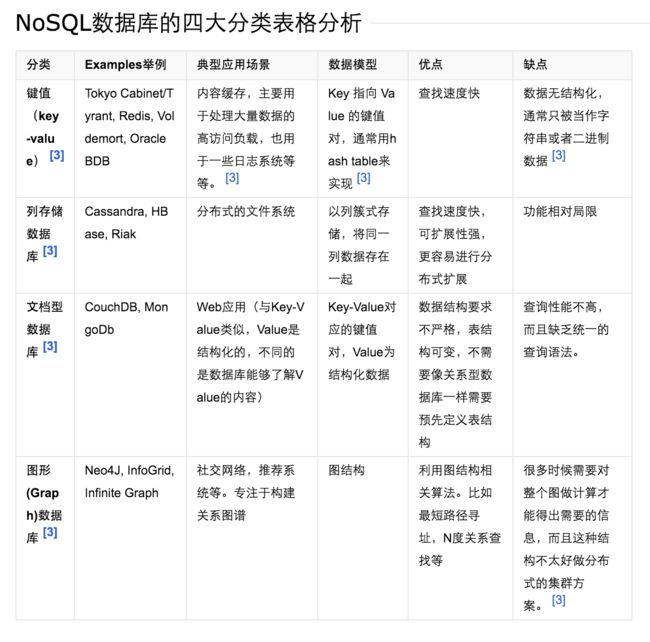
NoSQL数据库的四大分类
1 键值(Key-Value)存储数据库
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说的优势在于简单、易部署。但是如果DBA只对部分值进行查询或更新的时候,Key/value就显得效率低下了。举例如:Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB.
2 列存储数据库
这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。如:Cassandra, HBase, Riak.
3 文档型数据库
文档型数据库的灵感是来自于Lotus Notes办公软件的,而且它同第一种键值存储相类似。该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可 以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。如:CouchDB, MongoDb. 国内也有文档型数据库SequoiaDB,已经开源。
4 图形(Graph)数据库
图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。 如:Neo4J, InfoGrid, Infinite Graph.
因此,总结NoSQL数据库在以下的这几种情况下比较适用:1、数据模型比较简单;2、需要灵活性更强的IT系统;3、对数据库性能要求较高;4、不需要高度的数据一致性;5、对于给定key,比较容易映射复杂值的环境。
下面给出一张对比图:
二 MongoDB简介
MongoDB的优点(为什么使用MongoDB):
“宽松”的数据存储形式非常灵活,MongoDB不限制每个key对应的values的数目。比如一个博客系统,有的文章没有评论,则它的值就是一个空集,有的文章评论很多,也可以无限制地插入。更灵活的是,MongoDB不要求同一个集合(collection,相当于SQL的table)里面的不同document有相同的key,比如除了上述这种文档组织,有的文档所代表的文章可能没有likes这个项目,再比如有的文章可能有更多的项目,比如可能还有dislikes等等。这些不同的文档都可以灵活地存储在同一个集合下,而且查询起来也异常简单,因为都在一个文档里,不用进行各种跨文档查询。而这种MongoDB式的存储也方便了数据的维护,对于一篇博客文章来说,所有的相关数据都在这个document里面,不用去考虑一个数据操作需要involve多少个表格。
当然,除了上述的优点,MongoDB还有不少别的优势,比如:MongoDB的数据是用JSON(Javascript Object Notation)存储的(就是上面的这种key-value的形式),而几乎所有的web应用都是基于Javascript的。因此,存储的数据和应用的数据的格式是高度一致的,不需经过转换。更多的优点可以查看:http://www.tutorialspoint.com/mongodb/mongodb_advantages.htm。
mongodb是文档型数据库,集合相当于关系型数据库的表,对象相当于关系型数据库的行。
三 MongoDB常用操作
(这里借鉴了StevenSLXie的MongoDB 极简实践入门一文:https://github.com/StevenSLXie/Tutorials-for-Web-Developers/blob/master/MongoDB%20%E6%9E%81%E7%AE%80%E5%AE%9E%E8%B7%B5%E5%85%A5%E9%97%A8.md,向原作者表示感谢!)
1 在后台启动mongodb服务:
# mongod --dbpath=/data/db --port=27017 --fork --logpath=var/log/mongd.log日志记录在var/log/mongd.log。
2.退出mongodb服务:
#db.shutdownServer() 或者 kill (forked process id)3. 命令行工具
本地:
$ mongo特定ip和端口:
$ mongo ip:port执行mongo命令后:
4.查看当前有哪些数据库:
> show dbsshow 命令也可以用来跟集合或对象来看它们包含哪些内容。
5.使用某数据库(没有会创建,当在集合中加入数据后才算真正创建成功,对象也是,只有掺入数据后才算创建成功)
> use dbname6 添加一个集合(collection),如:author (MongoDB里的集合和SQL里面的表格类似):
> db.createCollection('author')7 删除一个集合(collection),如:author
> db.author.drop()8.插入数据(无集合时会创建集合)
在use具体数据库后,通过以下命令插入数据:
> db.collectionName.insert({})比如:
db.movie.insert(
{
title: ‘Forrest Gump’,
directed_by: ‘Robert Zemeckis’,
stars: [‘Tom Hanks’, ‘Robin Wright’, ‘Gary Sinise’],
tags: [‘drama’, ‘romance’],
debut: new Date(1994,7,6,0,0),
likes: 864367,
dislikes: 30127,
comments: [
{
user:’user1’,
message: ‘My first comment’,
dateCreated: new Date(2013,11,10,2,35),
like: 0
},
{
user:’user2’,
message: ‘My first comment too!’,
dateCreated: new Date(2013,11,11,6,20),
like: 0
}
]
}
)
请注意,这里插入数据之前,并不需要先声明movie这个集合里面有哪些项目。直接插入就可以了~这一点和SQL不一样,SQL必须先声明一个table里面有哪些列,而MongoDB不需要。
insert操作有几点需要注意:
- 不同key-value需要用逗号隔开,而key:value中间是用冒号;
- 如果一个key有多个value,value要用[]。哪怕当前只有一个value,也加上[]以备后续的添加;
- 整个“数据块”要用{}括起来;
如果在insert之后看到WriteResult({ “nInserted” : 1 }),说明写入成功。
9 插入多条数据:
db.movie.insert([ { title: 'Fight Club', directed_by: 'David Fincher', stars: ['Brad Pitt', 'Edward Norton', 'Helena Bonham Carter'], tags: 'drama', debut: new Date(1999,10,15,0,0), likes: 224360, dislikes: 40127, comments: [ { user:'user3', message: 'My first comment', dateCreated: new Date(2008,09,13,2,35), like: 0 }, { user:'user2', message: 'My first comment too!', dateCreated: new Date(2003,10,11,6,20), like: 14 }, { user:'user7', message: 'Good Movie!', dateCreated: new Date(2009,10,11,6,20), like: 2 } ] }, { title: 'Seven', directed_by: 'David Fincher', stars: ['Morgan Freeman', 'Brad Pitt', 'Kevin Spacey'], tags: ['drama','mystery','thiller'], debut: new Date(1995,9,22,0,0), likes: 134370, dislikes: 1037, comments: [ { user:'user3', message: 'Love Kevin Spacey', dateCreated: new Date(2002,09,13,2,35), like: 0 }, { user:'user2', message: 'Good works!', dateCreated: new Date(2013,10,21,6,20), like: 14 }, { user:'user7', message: 'Good Movie!', dateCreated: new Date(2009,10,11,6,20), like: 2 } ] } ]) 顺利的话会显示:
BulkWriteResult({
“writeErrors” : [ ],
“writeConcernErrors” : [ ],
“nInserted” : 2,
“nUpserted” : 0,
“nMatched” : 0,
“nModified” : 0,
“nRemoved” : 0,
“upserted” : [ ]
表明成功地插入了两个数据。注意批量插入的格式是这样的:db.movie.insert([{ITEM1},{ITEM2}])。几部电影的外面需要用[]括起来。
请注意,虽然collection的插入不需要先声明,但表达相同意思的key,名字要一样,比如,如果在一个文档里用directed_by来表示导演,则在其它文档也要保持同样的名字(而不是director之类的)。不同的名字不是不可以,技术上完全可行,但会给查询和更新带来困难。
10 简单数据查询:
> db.movie.find().pretty()这里find()里面是空的,说明不做限制和筛选,类似于SQL没有WHERE语句一样。而pretty()输出的是经格式美化后的数据。
仔细观察find()的结果,会发现多了一个叫’_id’的东西,这是数据库自动创建的一个ID号,在同一个数据库里,每个文档的ID号都是不同的。
11 深度数据查询
在上面已经接触到最简单的查询db.movie.find().pretty()MongoDB支持各种各样的深度查询功能。
a 单个条件查询
先来一个最简单的例子,找出大卫芬奇(David Fincher)导演的所有电影:
db.movie.find({'directed_by':'David Fincher'}).pretty()这种搜索和SQL的WHERE语句是很相似的。
b 多个条件查询
比如找出大卫芬奇导演的, 摩根弗里曼主演的电影:
db.movie.find({'directed_by':'David Fincher', 'stars':'Morgan Freeman'}).pretty()这里两个条件之间,是AND的关系,只有同时满足两个条件的电影才会被输出。同理,可以设置多个的条件,不赘述。
条件之间也可以是或的关系,比如找出罗宾怀特或摩根弗里曼主演的电影:
db.movie.find(
{
$or:
[ {'stars':'Robin Wright'},
{'stars':'Morgan Freeman'}
]
}).pretty()注意这里面稍显复杂的各种括号。
c 范围查询
比如找出50万人以上赞的电影:
db.movie.find({'likes':{$gt:500000}}).pretty()同样要注意略复杂的括号。注意,在这些查询里,key的单引号都是可选的,也就是说,上述语句也可以写成:
db.movie.find({likes:{$gt:500000}}).pretty()类似地,少于二十万人赞的电影:
db.movie.find({likes:{$lt:200000}}).pretty()类似的运算符还有:$let:小于或等于;$get:大于或等于;$ne:不等于。
d 对于包含多个值的key,同样可以用find来查询。
比如:
db.movie.find({'tags':'romance'})将返回《阿甘正传》,虽然其标签既有romance,又有drama,但只要符合一个就可以了。
e 需要确切地知道返回的结果只有一个,用findOne:
db.movie.findOne({'title':'Forrest Gump'})如果有多个结果,则会按磁盘存储顺序返回第一个。请注意,findOne()自带pretty模式,所以不能再加pretty(),将报错。
f 只想显示结果中的一部分数据
可以用limit()和skip(),前者指明输出的个数,后者指明从第二个结果开始数。比如:
db.movie.find().limit(2).skip(1).pretty()则跳过第一部,从第二部开始选取两部电影。
g 局部查询
find对于符合条件的条目,都是返回整个JSON文件的。类似于SQL里面的SELECT *。有时我们需要的,仅仅是部分数据,这个时候,find的局部查询的功能就派上用场了。
先来看一个例子,返回tags为drama的电影的名字和首映日期。
db.movie.find({'tags':'drama'},{'debut':1,'title':1}).pretty()数据库将返回:
{
“_id” : ObjectId(“549cfb42f685c085f1dd47d4”),
“title” : “Forrest Gump”,
“debut” : ISODate(“1994-08-05T16:00:00Z”)
}
{
“_id” : ObjectId(“549cff96f685c085f1dd47d6”),
“title” : “Fight Club”,
“debut” : ISODate(“1999-11-14T16:00:00Z”)
}
{
“_id” : ObjectId(“549cff96f685c085f1dd47d7”),
“title” : “Seven”,
“debut” : ISODate(“1995-10-21T16:00:00Z”)
}
这里find的第二个参数是用来控制输出的,1表示要返回,而0则表示不返回。默认值是0,但_id是例外,因此如果你不想输出_id,需要显式地声明:
db.movie.find({'tags':'drama'},{'debut':1,'title':1,'_id':0}).pretty()12. 数据更新
a 直接更新
很多情况下需要更新数据库,比如有人对《七宗罪》点了个赞,而它本来的赞的个数是134370,那么就需要更新到134371。可以这样操作:
db.movie.update({title:'Seven'}, {$set:{likes:134371}})第一个大括号里表明要选取的对象,第二个表明要改动的数据。
b 增量更新
上述的操作不太现实,因为首先要知道之前的数字是多少,然后加一,但通常不读取数据库的话,是不会知道这个数(134370)的。
MongoDB提供了一种简便的方法,可以对现有条目进行增量操作。假设又有人对《七宗罪》点了两个赞,则可以:
db.movie.update({title:'Seven'}, {$inc:{likes:2}})如果你查询的话,会发现点赞数变为134373了,这里用的是$inc。除了增量更新,MongoDB还提供了很多灵活的更新选项,具体可以看:http://docs.mongodb.org/manual/reference/operator/update-field/ 。
c 多个符合要求的对象都更新
注意如果有多部符合要求的电影。则默认只会更新第一个。如果要多个同时更新,要设置{multi:true},像下面这样:
db.movie.update({}, {$inc:{likes:10}},{multi:true})所有电影的赞数都多了10.
d 保留原有值基础上增加一个值
注意,以上的更新操作会替换掉原来的值,所以如果你是想在原有的值得基础上增加一个值的话,则应该用$push,比如,为《七宗罪》添加一个popular的tags。
db.movie.update({'title':'Seven'}, {$push:{'tags':'popular'}})操作后可以发现《七宗罪》现在有四个标签:
"tags" : [
"drama",
"mystery",
"thiller",
"popular"
],
13. 数据删除
a 删除符合条件的所有数据
删除的句法和find很相似,比如,要删除标签为romance的电影,则:
db.movie.remove({'tags':'romance'})考虑到当前数据库条目异常稀少,不建议执行这条命令~
b 删除符合条件的第一条数据
上面的例子会删除所有标签包含romance的电影。如果你只想删除第一个,则
db.movie.remove({'tags':'romance'},1)c 删除集合下的所有文档
如果不加任何限制:
db.movie.remove()会删除movie这个集合下的所有文档。
14. 索引和排序
为文档中的一些key加上索引(index)可以加快搜索速度。
这一点不难理解,假如没有没有索引,要查找名字为Seven的电影,就必须在所有文档里逐个搜索。而如果对名字这个key加上索引值,则电影名这个字符串和数字建立了映射,这样在搜索的时候就会快很多。排序的时候也是如此,不赘述。
MongoDB里面为某个key加上索引的方式很简单,比如我们要对导演这个key加索引,则可以:
> db.movie.ensureIndex({directed_by:1})这里的1是升序索引,如果要降序索引,用-1。
MongoDB支持对输出进行排序,比如按名字排序:
> db.movie.find().sort({'title':1}).pretty()同样地,1是升序,-1是降序。默认是1。
> db.movie.getIndexes()将返回所有索引,包括其名字。
而
> db.movie.dropIndex('index_name')将删除对应的索引。
15 聚合
MongoDB支持类似于SQL里面的GROUP BY操作。比如当有一张学生成绩的明细表时,我们可以找出每个分数段的学生各有多少。为了实现这个操作,我们需要稍加改动我们的数据库。执行以下三条命令:
> db.movie.update({title:'Seven'},{$set:{grade:1}})
> db.movie.update({title:'Forrest Gump'},{$set:{grade:1}})
> db.movie.update({title:'Fight Club'},{$set:{grade:2}})这几条是给每部电影加一个虚拟的分级,前两部是归类是一级,后一部是二级。
这里你也可以看到MongoDB的强大之处:可以动态地后续添加各种新项目。
我们先通过聚合来找出总共有几种级别。
> db.movie.aggregate([{$group:{_id:'$grade'}}])输出:
{ “_id” : 2 }
{ “_id” : 1 }
注意这里的2和1是指级别,而不是每个级别的电影数。这个例子看得清楚些:
> db.movie.aggregate([{$group:{_id:'$directed_by'}}])这里按照导演名字进行聚合。输出:
{ “_id” : “David Fincher” }
{ “_id” : “Robert Zemeckis” }
接着我们要找出,每个导演的电影数分别有多少:
> db.movie.aggregate([{$group:{_id:'$directed_by',num_movie:{$sum:1}}}])将会输出:
{ “_id” : “David Fincher”, “num_movie” : 2 }
{ “_id” : “Robert Zemeckis”, “num_movie” : 1 }
注意$sum后面的1表示只是把电影数加起来,但我们也可以统计别的数据,比如两位导演谁的赞比较多:
> db.movie.aggregate([{$group:{_id:'$directed_by',num_likes:{$sum:'$likes'}}}])输出:
{ “_id” : “David Fincher”, “num_likes” : 358753 }
{ “_id” : “Robert Zemeckis”, “num_likes” : 864377 }
注意这些数据都纯属虚构啊!
除了$sum,还有其它一些操作。比如:
db.movie.aggregate([{$group:{_id:'$directed_by',num_movie:{$avg:'$likes'}}}])统计平均的赞。
db.movie.aggregate([{$group:{_id:'$directed_by',num_movie:{$first:'$likes'}}}]返回每个导演的电影中的第一部的赞数。
其它各种操作可以参考:http://docs.mongodb.org/manual/reference/operator/aggregation/group/ 。
- All or Nothing?
MongoDB支持单个文档内的原子化操作(atomic operation),这是说,可以将多条关于同一个文档的指令放到一起,他们要么一起执行,要么都不执行。而不会执行到一半。有些场合需要确保多条执行一起顺次执行。比如一个场景:一个电商网站,用户查询某种商品的剩余数量,以及用户购买该种商品,这两个操作,必须放在一起执行。不然的话,假定我们先执行剩余数量的查询,这是假定为1,用户接着购买,但假如这两个操作之间还加入了其它操作,比如另一个用户抢先购买了,那么原先购买用户的购买的行为就会造成数据库的错误,因为实际上这种商品以及没有存货了。但因为查询剩余数量和购买不是在一个“原子化操作”之内,因此会发生这样的错误[2]。
MongoDB提供了findAndModify的方法来确保atomic operation。比如这样的:
db.movie.findAndModify(
{ query:{'title':'Forrest Gump'},
update:{$inc:{likes:10}}
}
)
query是查找出匹配的文档,和find是一样的,而update则是更新likes这个项目。注意由于MongoDB只支持单个文档的atomic operation,因此如果query出多于一个文档,则只会对第一个文档进行操作。
findAndModify还支持更多的操作,具体见:http://docs.mongodb.org/manual/reference/command/findAndModify/。
16. 文本搜索
除了前面介绍的各种深度查询功能,MongoDB还支持文本搜索。对文本搜索之前,我们需要先对要搜索的key建立一个text索引。假定我们要对标题进行文本搜索,我们可以先这样:
db.movie.ensureIndex({title:'text'})接着我们就可以对标题进行文本搜索了,比如,查找带有”Gump”的标题:
db.movie.find({$text:{$search:"Gump"}}).pretty()注意text和search前面的$符号。
这个例子里,文本搜索作用不是非常明显。但假设我们要搜索的key是一个长长的文档,这种text search的方便性就显现出来了。MongoDB目前支持15种语言的文本搜索。
17. 正则表达式查询
MongoDB还支持基于正则表达式的查询。如果不知道正则表达式是什么,可以参考Wikipedia。这里简单举几个例子。比如,查找标题以b结尾的电影信息:
db.movie.find({title:{$regex:'.*b$'}}).pretty()也可以写成:
db.movie.find({title:/.*b$/}).pretty()查找含有’Fight’标题的电影:
db.movie.find({title:/Fight/}).pretty()注意以上匹配都是区分大小写的,如果你要让其不区分大小写,则可以:
db.movie.find({title:{$regex:'fight.*b',$options:'$i'}}).pretty()$i是insensitive的意思。这样的话,即使是小写的fight,也能搜到了。
mongodb图形化管理工具
个人推荐使用Robomongo:https://robomongo.org/