EMNLP2013_RNTN论文翻译:基于情绪树库的语义组合性递归深度模型
Richard Socher, Alex Perelygin, Jean Y. Wu, Jason Chuang,
Christopher D. Manning, Andrew Y. Ng and Christopher Potts
Stanford University, Stanford, CA 94305, USA
[email protected],{aperelyg,jcchuang,ang}@cs.stanford.edu
{jeaneis,manning,cgpotts}@stanford.edu
摘要:语义词空间已经非常有用,但不能用有原则的方式来表达较长词组的含义。进一步的工作是,在情绪检测这类任务中理解语义的组合性,这需要更丰富的监督训练、评估资源和更强大的组合模型。为了解决这个问题,我们引入了情绪树库。在11855个句子组成的解析树中它为215154个短语设置了细粒度 情绪标签并提出了情绪组合性的新挑战。为了解决这些问题,我们引进了递归神经张量网络。当在新的树库基础上训练了之后,该模型的几个指标明显优于以前的所有方法。它推动了单句正/负分类领域的状态指标从80%到85.4%。预测所有短语情感标签细粒度的准确率达到了80.7%,特征基准包有了9.7%的改善。最后,它是唯一的一种可以准确地捕捉否定的影响的模型并且其范围遍历了包含肯定和否定短语的多级别树。
一、引言
单个单词的语义向量空间已被广泛的用作特征(Turney and Pantel, 2010)。因为它们不能正确地捕捉较长的词组的含义,组合性语义向量空间最近受到了很多关注(Mitchell和Lapata,2010; Socher等,2010;Zanzotto等人,2010; Yessenalina和Cardie,2011;Socher等,2012; Grefenstette等,2013)。然而,由于目前缺乏用来捕获这些数据呈现的基本现象的大型和已标记的组合型资源和模型,进展遇到了很大的阻碍。为了满足这一需求,我们引进了斯坦福情绪树库和一个强大的递归神经张量网络,能够准确预测目前在这个新主体的组成语义的影响。
斯坦福情绪树库是第一个完全标记分析的树主体,允许对语言中情绪的组合性影响进行全面分析。语料库是基于Pang and Lee (2005)引入的数据集,由11,855个从电影评论中提取的单句组成。它经由斯坦福分析器(Klein and Manning, 2003)分析,并且包括了来自那些解析树的总共215154个独特的短语,每个词语由三个人人工标注。这个新的数据集允许我们分析情绪的复杂性和捕捉复杂的语言现象。
图一展示了一种清晰组成结构的例子,该数据集的粒度和大小将让团队用来训练基于监督和结构化机器学习技术的组成模型。虽然有多种数据集文件和块标签可供使用,但是仍然有必要更好地从短评中(如Twitter数据,其每篇文档提供较少的总信号)捕获情绪数据。为了获取更高的精度组成性的影响,我们提出了一个被称为递归神经张量网络(RNTN)新模式。递归神经张量网络采取任何长度的输入词组。它们通过单词向量和一个解析树来代表一个短语,之后利用使用相同张量基础的组合性功能的树来计算更高的节点向量。我们比较几个监督、组成性模型,如标准递归神经网络(RNN)(Socher等人 2011B),矩阵向量RNNs(Socher等,2012),和一些基准例如忽略了词序的神经网络,Naive Bayes (NB), bi-gram NB and SVM。当通过新的数据集训练之后,所有的模型都得到显著的提升,但是当预测所有节点的细分类情绪的时候,RNTN以80.7%的准确率获得了最高表现性能。最后,我们使用包括积极和消极的句子的一组测试集,它们的求反结果表明,不像单词集合包,RNTN能准确地捕捉到情绪的变化和否定的范围。RNTNs也学习那些对比结合但是却占主导地位的短语的情绪。完整的训练和测试代码,在线演示和斯坦福情绪树库数据集可在http://nlp.stanford.edu/sentiment 上获取。
二、相关工作
这项工作与自然语言理解的五个不同领域相关联,对于给定的空间限制,我们不能做出充分的正确判断,所以每个都有自己大量的相关工作。
Semantic Vector Spaces.(语义向量空间) 语义向量空间的主导方法是使用的单个单词相似分布。通常,一个字和它的空间上下文共同出现被用来描述每个单词(Turney and Pantel, 2010; Baroniand Lenci, 2010),例如tf-idf。这种思想的变体使用更复杂的频率,诸如在一个特定句法的上下文中一个单词是如何经常出现的(Pado and Lapata, 2007; Erk and Pado, 2008)。但是,分布式向量往往不能正确捕获反义词的差异,因为这些往往有相似的上下文。一个可能的补救方法是利用神经子向量(Bengio et al., 2003)。这些向量可以通过无监督的方式进行训练来捕捉相似分布(Collobert and Weston, 2008; Huang et al., 2012),但是还可以进行微调和训练如情绪检测特定的任务(Socher et al., 2011b)。本文的模型能够使用纯粹的监督字表示。这些监督字是完全在新的语料上学习到的。
Compositionality in Vector Spaces. (向量空间的组合性) 大多数的组合性算法和相关数据集捕获两个字的组合。Mitchell and Lapata (2010)使用两个字的短语,通过计算向量加法和向量乘法等等来分析相似性。一些相关的模型,如全息减缩表示(Plate,1995年),量子逻辑(Widdows,2008年),离散连续模型(Clark和Pulman,2007年)以及最近组成矩阵空间模型(Rudolph和Giesbrecht,2010年)还没有被实验证实有更大的语料库。Yessenalina和Cardie(2010)为较长的词组计算矩阵表示,定义组成矩阵乘法,并且还评估了情绪因素。Grefenstette和Sadrzadeh(2011)分析了主、动、宾语三元素,并找到一个与人的判断很相似的以矩阵为基础的分类模型。我们就监督组成模型比较了近期的工作进展。特别是,我们将描述并且用实验比较我们的新RNTN模型与递归神经网络(RNN)(Socher等人,2011B)和矩阵向量RNNs(Socher等人,2012),这两种已应用于单词包情绪语料库。
Logical Form. (逻辑形式)一个非常不同的角度铲球组合性的相关领域,它是试图映射句子的逻辑形式(Zettlemoyer和Collins,2005)。虽然这些模型是非常有趣的,在封闭的领域运作和离散集合方面表现良好,但是他们用不同的机制只能捕捉情绪的分布,这超出了目前使用的逻辑形式。
Deep Learning. (深度学习) 除了针对RNNs的上述工作,涉及到神经网络的几种组合性观点已经由Bottou (2011) and Hinton (1990)讨论过,Pollack (1990)已经试验测试过例如递归自动联想记忆的第一个模型。涉及到互三元输入的想法,由一个张量设计的参数已经由关系分类器所提出(Sutskever et al., 2009; Jenatton et al., 2012),延伸限制波尔兹曼机器(Ranzato和Hinton,2010年)和作为语音识别的特殊层(Yu等,2012)。
Sentiment Analysis. (情感分析) 除上述工作,大多数方法在情感分析中使用单词包的形式来表示((Pang and Lee, 2008)。Snyder和Barzilay(2007)通过分析更广泛的评价更详细地分析了餐馆的多个方面,比如食品或气氛中的情绪。一些工作通过特征的谨慎工程设计或者基于句法结构建立的极性转移规则来探索了情感组合性(Polanyi and Zaenen, 2006; Moilanen and Pulman, 2007; Rentoumi et al., 2010; Nakagawa et al., 2010)。
三、斯坦福情绪树库
单词分类包通过依赖几个具有强烈情绪性的单词‘awesome’或者‘exhilarating’可以在长文档中工作的更好。然而,甚至由单个句子的二元正负分类问题的情绪精度已经有连续几年没有超过80%。在包括中性类单词的这种更困难的情况下,twitter上的短消息的分析准确率往往低于60%(Wang et al., 2012)。从语言或认知的角度来看,在语义任务处理中忽略语序是不合理的,而且,我们将证明,它不能准确分类难的消极的例子。正确的预测这些困难的情况对进一步提高性能是很有必要的。
在本节中,我们对新的情绪树将进行介绍并提供一些分析。这个情绪树包括上千个句子中的那些似是而非短语的标签,这使我们能够训练和评价组成模型。
在这里,我们考虑电影评论的语料库,该语料库是从rottentomatoes.com网站摘录下来的,是由Pang and Lee (2005).最初收集和发表的。原始数据集包括10,662个句子,其中一半被认为是积极的,另一半则是消极的。每个标签是从一个较长的电影评论中提取并体现了作者对本条评价的整体意向。归一化的、小写的文本首先用于从原来的网站回收资本化的文本。剩下的那些不是英文的HTML标记或者句子会被删除。斯坦福大学的解析器(Klein and Manning, 2003)被用来分析所有10,662个句子。在约1100种情况下,它将片段分割成多个句子。然后,我们使用亚马逊的Mechanical Turk去标记所产生的215154个短语。图3展示了界面注解器。滑块有25个不同的值,并初始化为中性。在每个匹配里的短语是随机从该组所有短语中采样的,以防止标签受下文的影响。有关数据采集的详细信息,请参见补充材料。
图2列举了以n-gram长度为单位的归一化标签分布。再以20单位长度起步时,大多数会是完整的句子。对一个基于读者感知的标签句子的调查结果是,他们当中不少被认为是中性的。我们也注意到,更强的情绪往往存在于较长的词组当中而广大较短的短语往往是中性的。另一个观察是,大多数的注解将滑块移动到以下五个位置之一:消极,有点负面,中性,积极或是比较正面。极端值情况很少出现,滑块也并不经常停留在刻度线之间。因此,即使这些类别被分成5类,依然能捕捉到标签主要的变异性。我们将其命名为细分类的情感分类,我们的实验将为所有长度的句子回收这五类标签。
四、递归神经模型
本节中的模型为可变长度的短语和句法类型计算组成矢量表示。然后这些表示将被用来作为特征对每个短语进行分类。图4展示了这种方法。当组成模型中考虑了一个n-gram时,它被解析成二元树,每个叶结点对应于一个字,表示为一个矢量。递归神经模型将使用不同类型的组合性功能g计算以自下而上方式的父向量。父向量会作为特性来赋予到分类器中。为了便于说明,我们在这个图中将使用tri-gram来解释所有的模型。
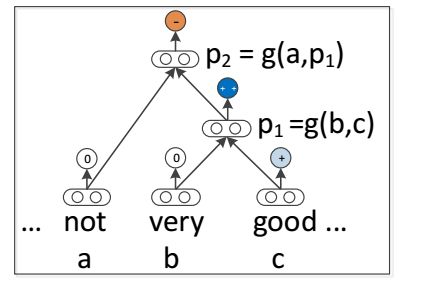
我们首先描述下文递归神经模型具有的共同的操作:字矢量表示和分类。接着是两个先前RNN模型的描述和我们的RNTN。
每个字被表示为d维矢量。我们通过随机抽取来自均匀分布的每个值初始化所有的文字向量:U(-r,r),其中r =0.0001。所有的字向量都被堆叠在矩阵L当中,L∈R^(d*|V| ), 其中,| V |是词汇的大小。最初字向量将是随机的,但L矩阵被看作是一个参数,这个参数是由组合性模型共同训练的。
我们可以立即使用字向量作为参数来优化或者使字向量作为特征输入来做一个SOFTMAX分类。为了分为五类,我们计算了给定的字矢量标签的后验概率:
y^a=softmax(W_s a),
其中W_S∈R^(5*d)是情感分类矩阵,对于给定的tri-gram,该矩阵进行反复的运算来求得向量b和向量c。该模型的主要任务和模型之间的差距将是以自下而上的方式计算隐式向量p_i∈R^d。
4.1 RNN:递归神经网络
神经网络模型族中最简单的成员是标准的递归神经网络(Goller and Kuchler, 1996; Socher et al.,2011a)。首先,确定父类已经拥有了所有的子类计算。在上面的树例子中,因为两者都是字,p_1有两个子向量。RNNs使用下面的公式来计算的父载体:
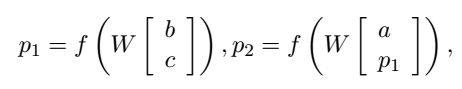
其中f=tanh是标准的非线性点积,W∈R^(d*2d)是学习的主要参数,这里我们忽略了简单的偏置。如果一个附加的1加到串联的输入矢量中,则该偏置可以添加一个额外的列到矩阵W中。每个父向量 p_i 是用来计算该等式相同的softmax分类器。1用来计算其标签的概率。
该模型使用相同的组合性函数作为递归自编码(Socher et al.,2011b)和递归自动关联存储器(Pollack, 1990)。与之前模型中的唯一的区别是,我们固定了树的结构,并忽略了重建损失。在最初的实验中,我们发现训练数据的附加量和在每个节点处重建损失都没有必要获得很高的性能。
4.2 MV-RNN:Matrix-Vector RNN(矩阵向量RNN)
MV-RNN受语言学的激励,因为大部分参数是与单词还有每个组合函数相关联的,为更长的短语计算向量取决于被合并的实际单词。MV-RNN的主要思想是将解析树中的每个单词和短语表示成向量和矩阵。当两种元素结合起来的时候,一个矩阵和另外一个向量相乘,反之亦然。因此,组成函数是由参与它的词语来参数化。
每个单词矩阵被初始化为d*d的单位矩阵并且掺有少量的高斯噪声。和随机单词向量相似,这些矩阵的参数将被训练,以此来尽量减少在各节点的分类错误。对于这个模型,每个n-gram和解析树一起被表示为(矢量,矩阵)对的列表,对于(向量,矩阵)节点树:
MV-RNN通过两个等式来计算第一个父向量和它的矩阵:
其中,W_M∈R^(d*2d)和结果也是d*d阶矩阵。同样的,第二父节点是使用之前计算的(矢量,矩阵)对(p_1,P_1)和(a,A)。像等式(1)一样,借助相同的softmax分类器,向量被用来给每个短语分类。
4.3 RNTN:Recursive Neural Tensor Network(递归神经网络的张量)
MV-RNN一个问题是,参数的数量变得非常大,而且依赖于词汇的规模。
如果成分函数具有固定数量的参数且单一功能强大,这将更为合理。标准RNN对于这样的函数来讲是一个很好的候选。然而在标准RNN中,输入向量只是和非线性函数进行隐性的交互。更直接的,可能是乘法,相互作用将允许模型在输入向量之间有更大的相互作用。
受这些思想的启发,我们提出这样的问题:一个单一的,更强大的组成函数可以更好的表现么?它能从较小的成分汇总合成一个完整的意思并且会相比许多具体的输入更准确么?为了回答这个问题,我们提出了一个被称为递归神经网络张量(RNTN)新模式。其主要思想是为所有节点使用相同的,基于张量的组成函数。
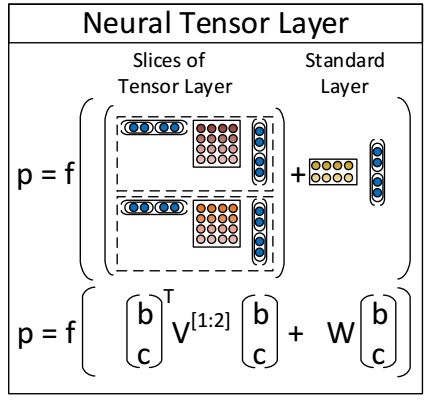
图5展示了一个单一的张量层。我们通过以下向量符号和对于每个部分都等价却更详细的符号V^[i] ∈R^(d*d)来定义一份张量积的输出h∈R^d:
其中V^[1:d] ∈R^(2d*2d*d) 是定义多个双线性形式的张量。
该RNTN使用这个公式计算P1:
其中W是如前模型中所定义。在tri-gram中的下一个父矢量p_2将用相同的权重来计算:
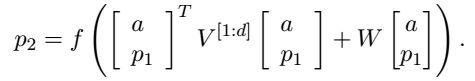
RNTN在当V被设置为0这种特殊情况下,较RNN模型的主要优势是张量可以直接关联到输入向量。直观地说,我们可以将张量的每一层面解释为捕获特定类型的组合物。
对RNTNs的一种替代可以通过添加第二个神经网络层使组合函数更加强大。然而,最初的实验表明,这个模型很难优化,并且向量的相互作用比RNTN更为确定。
4.4 Tensor Backprop through Structure(基于结构的bp神经网络向量)
我们将在本节介绍如何训练RNTN模型。如上文提到,每个节点都有一个基于它的向量表示训练的SOFTMAX分类器,来预测一个给定的基本事实或者目标矢量t。我们假设每个节点的目标分配矢量具有0-1编码。如果有是C类,则它在正确的标签上具有长度C和一个1。其他所有项目都是0。
我们希望使正确预测的概率最大化,或者是使在节点i的预测分布y^i∈R^(C*1)和在那个节点的目标分布t^i∈R^(C*1)之间的交叉熵误差最小化。这相当于使两个分布之间的KL散度最小化,对于一个句子来说,RNTN函数的误差参数θ=(V,W,W_S,L)定义为:
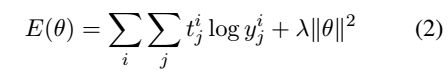
SOFTMAX分类器权重的导数是标准的并且是简单地从每个节点的错误中归纳出来的。我们把x^i 定义为在节点i上的向量(在例子trigram中,x^i∈R^(d*1)用(a,b,c,p_1,p_2来表示)。我们跳过W_s 的标准导数。每个节点反向传播它的错误直到递归使用权重V,W。让δ^(i,s) ϵR^(d*1)成为在节点i的softmax错误向量:
其中,⊗是两个向量之间的阿达玛积矢量,f ‘是f的元素级导数,f在标准情况下用f=tanh来表示,仅可以使用f(x^i )来计算。剩余的导数只能以自上而下的方式经过树的顶部节点到叶节点来计算。V和W的全部导数是每个节点导数的总和。我们将节点i完整的输入错误信息定义为δ^(p_2,com)。 顶部节点,就是我们提到的p_2,只能从顶部节点的softmax分类器中接收到错误信息。因此,δ^(p_(2,) com)=δ^(p_2,s),我们可以利用这个公式获得W的标准BP导数(Goller and Kuchler, 1996; Socher et al., 2010)。计算每个切面k=1,…,d的导数,我们得到:
δ_k^(p_2,com)是第k个单位向量。现在,我们可以计算p2两个子类的错误信息:
在这里,我们定义:
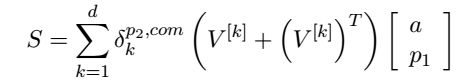
P2的子类,会各取该向量的一半,并把他们自身的softmax错误信息加进去,为了得到一个完整的δ。特别的,我们得到:
δ^(p_2,down) [d+1:2d]表示p1是p2的右子节点,因此取错误信息的第二部分,为了得到最终的字向量导数a,它将是δ^(p_2,down) [1:d]。
Trigram树的切面V^[k] 的全微分是每个节点的总和:
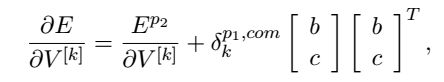
W同理。对于这种非凸最优化我们使用AdaGrad(Duchi et al., 2011)等人的方法,其在不到3小时的时间内就能收敛到局部最优。
五、实验
我们有两种类型的分析。第一类包括对测试集的几个大型量化评估。第二类把焦点集中在情绪上很重要的两个语言现象。
对于所有的模型,我们使用的是开发集和交叉验证权重的正则化,字矢量大小以及学习AdaGrad的率和minibatch大小。所有模型的最优性能,在矢量字25和35尺寸和批量20和30尺寸之间实现。性能会在更大或者更小的向量和批量尺寸上减小。这表明由于RNTN只是简单地具有多个参数,RNTN的性能并不优于标准RNN。由于字矩阵,MV-RNN具有比其他任何模型多了几个数量级的参数。RNTN通常会在训练了3-5个小时之后达到它的最佳性能。最初的实验表明,在使用线性时,该递归模型出现了显著恶化(准确度下降了超过5%)。因此在所有实验中,我们使用f=tanh。
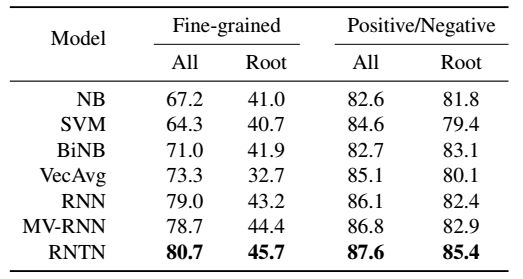
我们比较常用使用朴素贝叶斯词功能袋和支持向量机,以及朴素贝叶斯与二元特征features.We与NB,SVM和biNB缩写这些方法。我们也比较该平均神经字向量并忽略词序的模型(VEC平均)。在树库中的句子被分成训练(8544),开发(1101)和测试分裂(2210)。这些裂缝是由可用的数据获得的。我们也分析积极和消极句的性能,忽略中性类。 拥有这三个集20%数据的滤波器具有6920/872/1821个句子。
5.1 适用于所有词组的细分类情绪
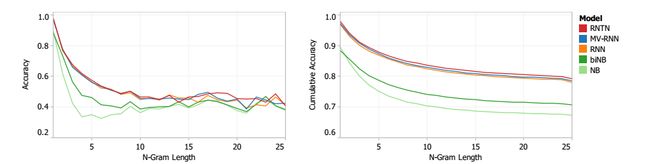
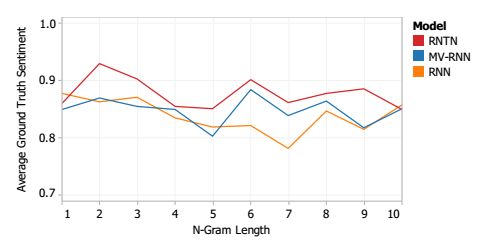
主要的新实验和评估指标分析了所有词组的细分类情感分类的准确性。图.2表明,细分类分类为5类对捕捉到大部分的数据变化是一个合理的预设。图.6展示出此新语料库的测试结果。RNTN获得最高性能,其次是MV-RNN和RNN。递归模型在消极词汇和组成关系很重要的较短短语上效果很好,而功能基线包只能用更长的句子表现良好。在大多数n-gram长度上,该RNTN精度达到了其他模型的上界。表1(左)说明了所有词组长度和所有句子的细分类预测的整体准确数量。
5.2 全句二元情绪
这部分可媲美以前在原始的烂番茄数据集上的工作,该数据集只用完整的句子标签和正/负的二元分类。因此,这些实验表明,改善,甚至是基本的方法可以通过用情绪树库来实现。表1所示为所有的短语和唯一完整的句子,还有二元分类的结果。以前的技术结果是低于80%(Socher et al., 2012)。由于有很多粗略的词袋(BOW)标注被用于训练,所以很多更复杂的现象不能被捕捉到,甚至是更强大的模型也做不到。新的情绪树库和RNTN的结合推动了短语的现有技术状态达到了85.4%。
5.3 模型分析:对比连词
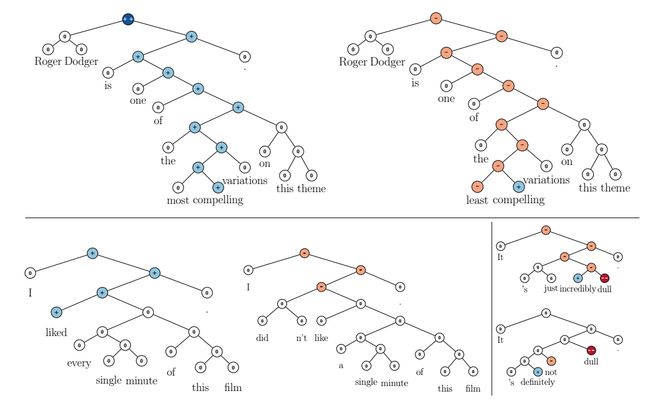
在本节中,我们使用测试集的一个子集,该子集中的句子具有’X but Y’结构:一个短语X后面跟着but,but后是一个短语Y。这个连词被解释为是第二个部分的一个借口理由,第一个部分的让步(Lakoff, 1971; Blakemore,1989; Merin, 1999)。图.7给出了一个示例。我们分析了一种严格的设置,其中X和Y是不同的情绪词组(包括中性)。若为两个短语X和Y的分类是正确的,则该例子是计为正确。此外,同时支配单词but和跨越Y的节点的最低节点也必须有相同的正确的情绪。对得到的131个例子中,RNTN获得了41%的精度,相比之下,MV-RNN获得了37%,RNN获得了36%,biNB获得了27%。
5.4 模型分析:高级否定
我们调查两种类型的否定。对于每一种类型,我们使用一个单独的数据集进行评估。
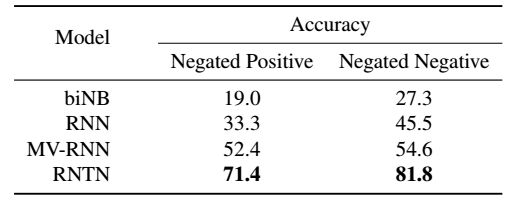
情况一:负肯定句。第一组中包含肯定句和否定句。在这组,否定改变了句子的整体情绪,使其从积极变成消极。因此,我们计算正确情绪从正到负反转的精度。图.9展示了两个RNTN正确分类的例子,这两个例子是先肯定后否定(positive negation)。甚至如果在“最”的情况下,否定也不是那么明显,RNTN还是能很好的进行分类。图.2(左)给出了21个句子应用到所有模型上的准确度,这21个句子既有肯定的句子也有否定的。RNTN有最高的反转准确度,显示出其在结构上学习肯定句子否定的能力。但是如果当否定在句子中出现的时候,模型仅仅是使句子变得特别消极,这种情况怎么办呢?下一个实验展示了本文的模型能比这个简单的否定规则捕捉到更多。
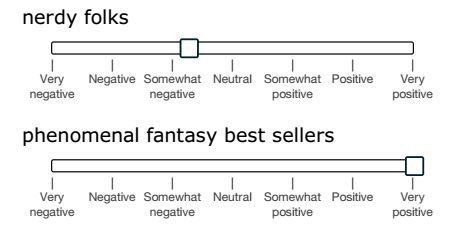
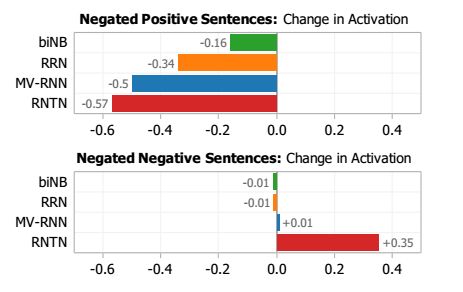
情况二:负否定句。第二组中包含否定句和它们的否定。当否定句被否定时,情树库显示,整体的情绪应该变得不那么负,但不一定阳性。例如,“这部电影太糟糕了”为否定,但“这部电影并不糟糕’只是说,相比糟糕来说,这并不是那么糟,但也不能说这是很好的(Horn, 1989; Israel, 2001)。因此,对每个模型能够多久提高负否定对句子情绪的激励,我们进行了评估。表.2(右)展示出了精确度。在整个案例中,RNTN能正确的增加肯定的激励的比例超过了81%。图.9(右下)展示了一种典型的情况。即使not和dull都是否定词,通过把主要的分类从否定转换成中性,还是能将句子的情绪变得更加肯定。图.8表示了对于两种情况激励的变化。负值表明平均来看肯定激励的减少(情况一),正值表明平均来看肯定激励的增加(情况二)。RNTN在正确的方向上有最大的转变。因此,我们能得出这样的结论:对于肯定或者否定的句子,RNTN在确定否定词影响的时候,具有最强的能力。
5.5 模型分析:大多数肯定和否定短语
我们查询了模型对最肯定和最否定的n-grams语言模型是哪个的预测,并测定为最肯定和最否定分类的最高激励。表3展示了一些来自开发集的一些短语。这个开发集是RNTN为了获得最强情绪所挑选的。 由于缺乏空间,我们不能与其他模型比较顶部短语,但是图.10展示了,相比其它模型而言,在大多数n-gram长度下,RNTN选择了更强烈的肯定短语。 对于这点还有前面的实验,请在补充材料中找额外的例子和说明。
六、结论
我们引入了递归神经张量网络和斯坦福大学情绪树库。新模型和数据的结合产生的新系统,该系统使单一的句子情绪检测现状提升了5.4%。除了这个标准设定,数据集也带来了一些新的挑战并考虑了一些新的评价指标。例如,RNTN在对所有短语的细粒度情绪的预测上获得了80.7%准确率,并捕获了不同情绪的否定,在范围上比以往的模型更加准确。