Chars74K由theano到keras(关于keras学习以及源码阅读)
之前学习深度学习是从theano开始,官方的教程很赞,非常细致。但是也有缺点,就是太复杂了,建模十分麻烦。之前本来准备先学theano掌握基本知识然后开始用caffe的,不过让我发现了keras,很赞。
下面是一段用keras写的卷积神经网络识别MNIST手写字符的代码,可以看到代码十分简洁。
import numpy as np
np.random.seed(1337) # for reproducibility
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.utils import np_utils
'''
Train a simple convnet on the MNIST dataset.
Run on GPU: THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python mnist_cnn.py
Get to 99.25% test accuracy after 12 epochs (there is still a lot of margin for parameter tuning).
16 seconds per epoch on a GRID K520 GPU.
'''
batch_size = 128
nb_classes = 10
nb_epoch = 12
# the data, shuffled and split between tran and test sets
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28)
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28)
X_train = X_train.astype("float32")
X_test = X_test.astype("float32")
X_train /= 255
X_test /= 255
print('X_train shape:', X_train.shape)
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
model = Sequential()
model.add(Convolution2D(32, 1, 3, 3, border_mode='full'))
model.add(Activation('relu'))
model.add(Convolution2D(32, 32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(poolsize=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(32*196, 128))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(128, nb_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adadelta')
model.fit(X_train, Y_train, batch_size=batch_size, nb_epoch=nb_epoch, show_accuracy=True, verbose=1, validation_data=(X_test, Y_test))
score = model.evaluate(X_test, Y_test, show_accuracy=True, verbose=0)
print('Test score:', score[0])
print('Test accuracy:', score[1])
keras很好用,但是感觉官方文档太少,很多功能都没有描述。这里怎么办呢,我们可以直接打开源代码来找你想要的功能,比如想要保存和读取训练到的权值,这里我翻遍了官网页没有找到,只能去看源代码。不过keras的源码还是十分规范的,而且代码量不大,很容易就能找到你想要的代码。比如读取和保存权值的代码如下:
这里我们不仅可以看到源码,而且可以根据自己的需要来修改源码,比如如果我们想把训练的权值嵌入到c++的代码中就可以保存到c++方便读写的格式和结构。
def save_weights(self, filepath, overwrite=False):
# Save weights from all layers to HDF5
import h5py
import os.path
# if file exists and should not be overwritten
if not overwrite and os.path.isfile(filepath):
import sys
get_input = input
if sys.version_info[:2] <= (2, 7):
get_input = raw_input
overwrite = get_input('[WARNING] %s already exists - overwrite? [y/n]' % (filepath))
while overwrite not in ['y', 'n']:
overwrite = get_input('Enter "y" (overwrite) or "n" (cancel).')
if overwrite == 'n':
return
print('[TIP] Next time specify overwrite=True in save_weights!')
f = h5py.File(filepath, 'w')
f.attrs['nb_layers'] = len(self.layers)
for k, l in enumerate(self.layers):
g = f.create_group('layer_{}'.format(k))
weights = l.get_weights()
g.attrs['nb_params'] = len(weights)
for n, param in enumerate(weights):
param_name = 'param_{}'.format(n)
param_dset = g.create_dataset(param_name, param.shape, dtype=param.dtype)
param_dset[:] = param
f.flush()
f.close()
def load_weights(self, filepath):
'''
This method does not make use of Sequential.set_weights()
for backwards compatibility.
'''
# Loads weights from HDF5 file
import h5py
f = h5py.File(filepath)
for k in range(f.attrs['nb_layers']):
g = f['layer_{}'.format(k)]
weights = [g['param_{}'.format(p)] for p in range(g.attrs['nb_params'])]
self.layers[k].set_weights(weights)
f.close()
还有一处比较有用的代码如下:
def predict_on_batch(self, X):
ins = standardize_X(X)
return self._predict(*ins)
def predict(self, X, batch_size=128, verbose=0):
X = standardize_X(X)
return self._predict_loop(self._predict, X, batch_size, verbose)[0]
def predict_proba(self, X, batch_size=128, verbose=1):
preds = self.predict(X, batch_size, verbose)
if preds.min() < 0 or preds.max() > 1:
warnings.warn("Network returning invalid probability values.")
return preds
def predict_classes(self, X, batch_size=128, verbose=1):
proba = self.predict(X, batch_size=batch_size, verbose=verbose)
if self.class_mode == "categorical":
return proba.argmax(axis=-1)
else:
return (proba > 0.5).astype('int32')
这里是我训练之后想得到输出结果时候用到的函数,直接在源码中搜索predict就可以找到这几个函数。
keras的预测值的保存方式稍微有点不同,记得开始调代码的时候这里出了一个bug,进入这个函数取看一下代码就知道到底是怎么回事了。 np_utils.to_categorical。
之前在做74k的识别中使用theano建模实在是做的头晕眼花,代码太乱,修改起来麻烦,所以有一个功能一直没有加,识别率一直停留在70%左右。今天用keras很快就把代码调好了。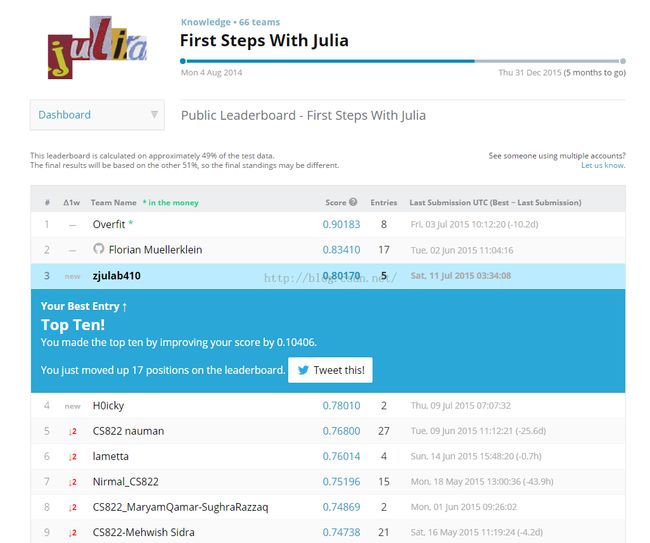 识别率提高了不少。
识别率提高了不少。
因为训练实在太慢了,在python里加入循环,可以多次执行并把权值和结果保存。不过因为技术太菜,中间显存没有及时释放,循环了几次就崩溃了。所以后来就改用shell来调用python,这里一个非常简单的脚本,循环10次调用python程序,然后将每次的权值保存为1、2、3.。。。
#!/bin/bash
for i in {1..10}
do
python my74K7.py
sleep 1m #让电脑休息会。。。
cp weight_74k ./weight74k/$i
done
说点其他的,这里的字符识别还是别人切割好的单个字符,如和从多个字符中找到想要的字符并识别。这里我们举一反三,opencv里有一个行人检测的函数hog.detectMultiScale,顺着这个函数找下去,果然很快就能找到这段代码,有些时候文章里找不到解决方法我们可以直接去源码中找。
最后说一下训练的模型和我上一次博客中的模型一样,只是又加上了扩大数据集的代码。这个代码在上上个博客里也有。还有就是调试的过程中每次的结果都有保存到文件里,而且没隔一段时间会保存一次训练的权值。