Hadoop教程(二)Hadoop伪集群环境安装
Hadoop教程(二)Hadoop伪集群环境安装
1 Hadoop伪分布式安装
1.1 相关下载
1、JDK下载地址:jdk-8u66-linux-x64.tar.gz
Linux安装JDK及环境变量配置,参见:http://blog.csdn.net/yuan_xw/article/details/49948285
2、Hadoop下载:hadoop-2.7.1.tar.gz
1.2 上传服务器
1、下载完成后,使用Xftp软件上传到Linux服务器上:/usr/local/software
执行命令:mkdir /usr/local/software
2、在Xshell命令行进行解压安装:
执行命令:cd /usr/local/software 切换目录

执行命令:tar -zxvf hadoop-2.7.1.tar.gz解压
3、重命名hadoop_2.7.1,执行命令:mv hadoop-2.7.1 hadoop_2.7.1
4、Hadoop目录说明:
1. bin:Hadoop最基本的管理脚本和使用脚本所在目录
2. etc:Hadoop配置文件所在的目录,包括core-site.xml、hdfs-site.xml、mapred-site.xml等
3. include:对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++语言访问HDFS或者编写MapReduce程序
4. lib:该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。
5. libexec:各个服务对应的Shell配置文件所在目录,可用于配置日志输出目录、启动参数(比如JVM参数)等基本信息。
6. sbin:Hadoop管理脚本所在目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。
7. share:Hadoop各个模块编译后的JAR包所在目录。
1.3 环境变量
1、HADOOP_HOME:环境变量它指向Hadoop的安装目录,如:/usr/local/software/hadoop_2.7.1。
2、PATH环境变量:作用是指定命令搜索路径,在shell下面执行命令时,它会到PATH变量所指定的路径中查找看是否能找到相应的命令程序。
3、修改profilie文件:执行命令:vi /etc/profile
export JAVA_HOME=/usr/local/software/jdk1.8.0_66
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/usr/local/software/hadoop_2.7.1
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
执行命令:source /etc/profile 刷新环境变量
1.4 CentOS7环境配置
1、修改HOSTNAME(主机名):
将主机名改为:Hadoop1:执行命令:vi /etc/hostname
验证:重启
2、IP与hostname绑定:
修改文件,执行命令:vi /etc/hosts
添加一行代码:192.168.10.121 Hadoop1
验证:ping Hadoop1
3、关闭防火墙:
在CentOS 7或RHEL 7或Fedora中防火墙由firewalld来管理,当然你可以还原传统的管理方式。或则使用新的命令进行管理。
新的命令管理:
1.执行命令:systemctl stop firewalld
传统的管理方式:
1.安装iptables-services命令
yum install iptables-services
2.设置开机启动:service iptables [stop|start|restart]
service iptables save
# or
/usr/libexec/iptables/iptables.initsave
验证:service iptables status
4、关闭防火墙自动运行:
执行命令:systemctl disable iptables.service
验证:systemctl list-unit-files |grep iptables
5、免密码登录:
产生密钥,执行命令:ssh-keygen -t rsa,连续按4次回车,密钥文件位于~/.ssh文件
执行命令:cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
验证:ssh localhost
1.5 修改配置文件:
1、修改hadoop-env.sh配置文件:
执行命令:
vi /usr/local/software/hadoop_2.7.1/etc/hadoop/hadoop-env.sh
修改内容:
export JAVA_HOME=/usr/local/software/jdk1.8.0_66
2、修改core-site.xml配置文件:
执行命令:
vi /usr/local/software/hadoop_2.7.1/etc/hadoop/core-site.xml
修改内容:
<configuration> <!--指定NameNode的master节点URL地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://Hadoop1:9000</value> </property> <!-- Hadoop的运行时文件存放路径,如果不存在此目录需要格式化 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/software/hadoop_2.7.1/tmp</value> </property> </configuration>
3、修改hdfs-site.xml配置文件:
执行命令:
vi /usr/local/software/hadoop_2.7.1/etc/hadoop/hdfs-site.xml
修改内容:
<configuration> <!-- 配置副本的数量 --> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
4、修改mapred-site.xml配置文件:
执行命令:
切换目录:cd /usr/local/software/hadoop_2.7.1/etc/hadoop/
重命名:mv mapred-site.xml.template mapred-site.xml
修改文件:vi mapred-site.xml
修改内容:
<configuration> <!-- 指定Hadoop的MapReduce运行在YARN环境 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
5、修改yarn-site.xml配置文件:
执行命令:
vi /usr/local/software/hadoop_2.7.1/etc/hadoop/yarn-site.xml
修改内容:
<configuration> <!-- NodeManager获取数据方式:shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--指定YARN的master节点( ResourceManager) 的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>Hadoop1</value> </property> </configuration>
1.6 格式化文件系统:
HDFS文件系统进行格式化,执行命令:。
# hadoop namenode –formate(已过时)
hdfs namenode –format推荐使用
验证:提示如下信息表示成功:
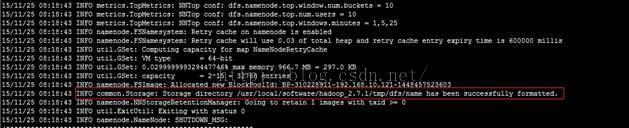
INFO common.Storage: Storagedirectory /usr/local/software/hadoop_2.7.1/tmp/dfs/name has been successfullyformatted.
1.7 启动Hadoop:
1、启动HDFS和YARN:
切换目录:cd /usr/local/software/hadoop_2.7.1/sbin/
启动HDFS和YARN,执行命令:
./start-all.sh (已过时:Thisscript is Deprecated. Instead use start-dfs.shandstart-yarn.sh)
![]()
2、验证启动HDFS和YARN:
SecondaryNameNode:它不是 namenode的冗余守护进程,而是提供周期检查点和清理任务。
DataNode:它负责管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个 datanode守护进程。
ResourceManager:接收客户端任务请求,接收和监控NodeManager(NM)的资源情况汇报,负责资源的分配与调度,启动和监控ApplicationMaster(AM)。
Jps:JDK提供查看当前java进程的小工具。
NameNode:它是Hadoop中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问。
NodeManager:NodeManager(NM)是YARN中每个节点上的代理,它管理Hadoop集群中单个计算节点,包括与ResourceManger保持通信,监督Container的生命周期管理,监控每个Container的资源使用(内存、CPU等)情况,追踪节点健康状况,管理日志和不同应用程序用到的附属服务(auxiliaryservice)。
1.8 访问Hadoop服务页面:
访问地址验证启动服务,访问地址:
HDFS管理界面:http://192.168.10.121:50070/

YARN管理界面:http://192.168.10.121:8088/
——厚积薄发(yuanxw)