搜索引擎项目
搜索引擎
1. 程序开发环境
Server端
Linux: centos6.0
G++: version 4.4
Client端
Php
2. 系统目录结构
src :存放系统的源文件(.cpp) 。
include:存放系统的头文件(.h) 。
bin: 存放系统的可执行程序。
conf:存放系统程序中所需的相关配置信息。
lib: 存放系统程序中所使用的库文件。
data: 存放系统程序所需的数据。
3.系统运行图
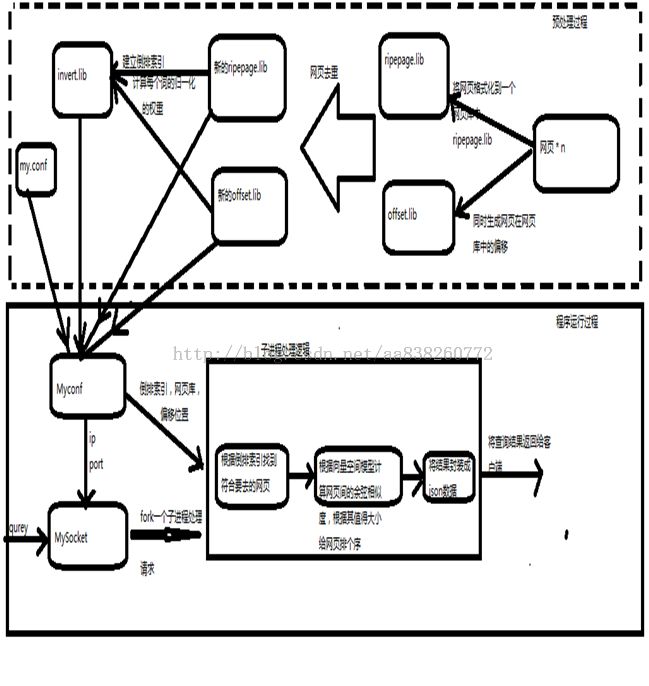
3. 系统总体概述
预处理过程:
预处理过程主要是事先生成程序在运行过程中可能用到的数据,以便提高处理时间。预处理的过程主要生成程序所需的三个文件:网页库文件,网页位置信息文件和倒排索引文件。其中网页库文件ripepage.lib主要是以格式化的数据存储大量的网页信息,每个网页的格式化数据为:<doc><docid>id</docid><docurl>url</docurl><doctitle>title</doctitle><doccontent>content</doccontent><></doc>。
网页位置信息文件offset.lib主要是存放网页在网页库中的偏移位置,以便程序能快速的取出指定的网页,该文件每一行存储一个网页文件在网页库中的位置信息,每一行的格式为:docid offset size, 其中docid为网页的id(此id具有全局唯一性),offset为文档在网页库中距离文件起始位置的字节数,size为文档的大小。
倒排索引文件invert.lib为网页库中的所有词(经过分词,去停用词)与包含这些词的文档的一种关联关系。每个词的倒排索引在该文件中占一行,每一行的格式为:
Word docid1 frequency1 weight1 … docidi frequencyi weighti…
其中word为网页库中的词, 后面接着的是每三个为一组,docidi 为包含该词的网页,frequencyi为该次在该文档中的词频,weighti为该次在该文档中的权重(归一化后的)。
程序运行过程:
程序首先从offset.lib中读取网页位置信息,然后根据这些信息从rippage.lib中读取网页信息,然后从invert.lib读取倒排索引信息
程序循环不断地通过socket接受来自客户端的请求,一旦受到请求就fork一个子进程负责处理该请求而主进程则继续监听。子进程接受来自客户端的查询语句,根据查询语句查找结果并将结果返回给客户端。
4.详细设计(参考源代码,都有非常详细的注释)
① 生成网页库ripepage.lib
②生成网页的位置偏移文件offset.lib
以上请参考make_ripepage_offset下的代码
③网页去重生成新的offset.lib文件
参考pagedup_remove\src下的test.cpp及其相关文件
④建立倒排索引文件invert.lib
参考pagedup_remove\src下的test.cpp及其相关文件
⑤程序查询逻辑
参考pagedup_remove\src下的test_qurey.cpp及其相关文件
⑥服务器框架
参考pagedup_remove\src下的test_main.cpp及其相关文件