Wireshark与设备解析字节不一致问题
本文可以在我的资源里免积分下载:http://download.csdn.net/detail/shizhixin/9406103
一、 问题
对于一个PCAP包,用Wireshark的Conversions统计的包字节数(图1),与设备解析得到的字节数(图2)不一致,设备解析后的字节数比Wireshark的字节数要少,但是包数是相同的。
图1:原始数据包wireshark 会话统计截图
图2:设备抓取数据包wireshark 会话统计截图
二、 问题的原因
不是丢失包而导致的字节问题,因为包数并没有减少,只是字节减少了。具体原因是用Wireshark抓包抓出来的数据会对不满60字节的数据都做了填充,保证满60字节,如下图:
而设备的流量引擎将这些填充数据数据都去掉了,统计的是真实数据的字节数,所以会少了填充的字节数。即Wireshark抓包的字节数 = 设备解析的字节数 + 有填充的字节数。
三、 实验验证
我们随机找了两个包进行了实验,具体过程如下:
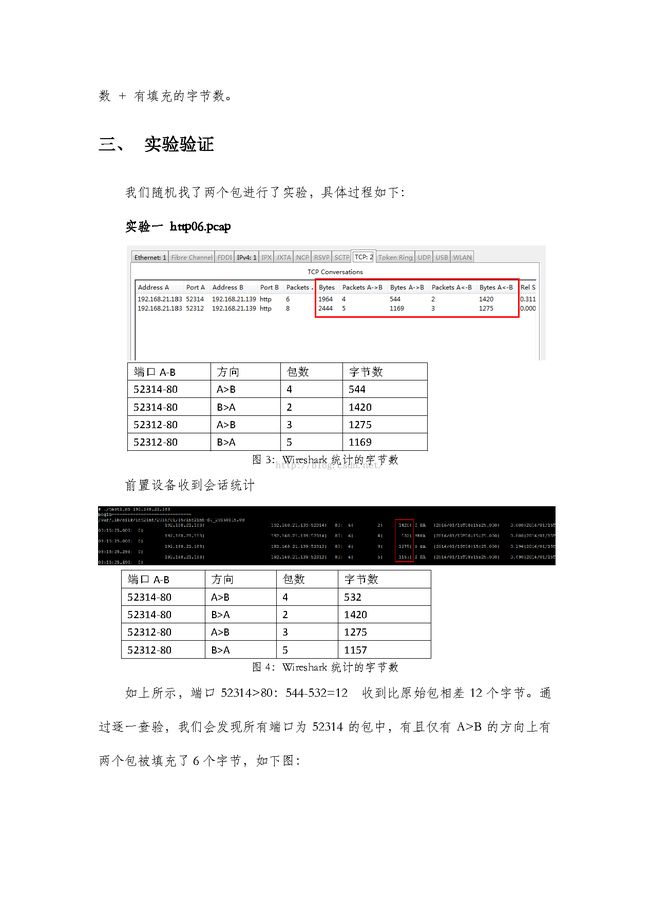
实验一 http06.pcap
| 端口A-B |
方向 |
包数 |
字节数 |
| 52314-80 |
A>B |
4 |
544 |
| 52314-80 |
B>A |
2 |
1420 |
| 52312-80 |
A>B |
3 |
1275 |
| 52312-80 |
B>A |
5 |
1169 |
图3:Wireshark统计的字节数
前置设备收到会话统计
| 端口A-B |
方向 |
包数 |
字节数 |
| 52314-80 |
A>B |
4 |
532 |
| 52314-80 |
B>A |
2 |
1420 |
| 52312-80 |
A>B |
3 |
1275 |
| 52312-80 |
B>A |
5 |
1157 |
图4:Wireshark统计的字节数
如上所示,端口52314>80:544-532=12 收到比原始包相差12个字节。通过逐一查验,我们会发现所有端口为52314的包中,有且仅有A>B的方向上有两个包被填充了6个字节,如下图:
52312>80:Wireshark抓的包字节数1169 – 设备解析的字节数1157 = 12个字节。同理,在端口52312也出现了同样的状况,有两个包被填充了6个字节,如下图:
实验2:request_http_server_baidu_115.115.115.129.pcap
| 端口A-B |
方向 |
包数 |
字节数 |
| 1165-80 |
A>B |
5 |
564 |
| 1165-80 |
B>A |
3 |
320 |
| 端口A-B |
方向 |
包数 |
字节数 |
| 1165-80 |
A>B |
5 |
564 |
| 1165-80 |
B>A |
3 |
318 |
逐一查验数据包,发现有一个包被填充了两个字节,如图所示:
因而,1165>80:Wireshark抓取的包字节数320 – 设备解析的包字节数318= 2 填充了2个字节。
四、 包在什么情况下会被填充字节
要理解包在什么情况下会被填充,首先从帧的格式说起。
以太网(IEEE 802.3)帧格式:
1、前导码:7字节0x55,一串1、0间隔,用于信号同步
2、帧起始定界符:1字节0xD5(10101011),表示一帧开始
3、DA(目的MAC):6字节
4、SA(源MAC):6字节
5、类型/长度:2字节,0~1500保留为长度域值,1536~65535保留为类型域值(0x0600~0xFFFF)
6、数据:46~1500字节
7、帧校验序列(FCS):4字节,使用CRC计算从目的MAC到数据域这部分内容而得到的校验和。
据RFC894的说明,以太网封装IP数据包的最大长度是1500字节,也就是说以太网最大帧长应该是以太网首部加上1500,再加上7字节的前导同步码和1字节的帧开始定界符,具体就是:7字节前导同步吗+1字节帧开始定界符+6字节的目的MAC+6字节的源MAC+2字节的帧类型+1500+4字节的FCS。
按照上述,最大帧应该是1526字节,但是实际上我们抓包得到的最大帧是1514字节,为什么不是1526字节呢?原因是当数据帧到达网卡时,在物理层上网卡要先去掉前导同步码和帧开始定界符,然后对帧进行CRC检验,如果帧校验和错,就丢弃此帧。如果校验和正确,就判断帧的目的硬件地址是否符合自己的接收条件(目的地址是自己的物理硬件地址、广播地址、可接收的多播硬件地址等),如果符合,就将帧交“设备驱动程序”做进一步处理。这时我们的抓包软件才能抓到数据,因此,抓包软件抓到的是去掉前导同步码、帧开始分界符、FCS之外的数据,其最大值是6+6+2+1500=1514。
以太网规定,以太网帧数据域部分最小为46字节,也就是以太网帧最小是6+6+2+46+4=64字节。除去4个字节的FCS,因此,抓包时就是60字节。当数据字段的长度小于46字节时,MAC子层就会在数据字段的后面填充以满足数据帧长不小于64字节,即减去FCS为Wireshark抓的包不小于60个字节。
这就能解释为什么设备抓出来的包个数和Wireshark的包数一致,也就是没有丢包现象,而字节数会有所差别。不同的Pcap包丢失的字节总数取决于这个Pcap包样本中被填充的包数和字节数,最终的结论是:
Wireshark抓取的包字节数 = 设备解析的包字节数(即真实数据字节数)+ MAC子层填充的字节数。
我们很多次实验也验证了这一结论。
需要注意的是:
填充(如果需要的话)是数据链路层协议自动完成的,由MAC子层负责,也就是设备驱动程序。不同的抓包程序和设备驱动程序所处的优先层次可能不同,抓包程序的优先级可能比设备驱动程序更高,也就是说,我们的抓包程序可能在设备驱动程序还没有填充不到64字节的帧的时候,抓包程序已经捕获了数据。因此不同的抓包工具抓到的数据帧的大小可能不同。
参考文献:
[1] 以太网最大帧和最小帧、MTU,http://blog.chinaunix.net/uid-20620288-id-3521720.html
[2]浅谈以太网帧格式,http://support.huawei.com/ecommunity/bbs/10154435.html
[3] IP数据包长度问题总结,
http://www.360doc.com/content/14/0726/11/1073512_397162229.shtml
[4] 为什么以太网无法接收大于1500字节的数据包?
https://www.zhihu.com/question/21524257/answer/18501433
[5] 当IP数据包小于46字节时为啥网卡没有自动填充, http://bbs.csdn.net/topics/370129808
[6] wireshark抓包怎么54字节也行,不是最少60吗,http://bbs.csdn.net/topics/390590266
-----------------------------------------------------
由于在WORD写的,图无法复制粘贴,试了在编辑框单独复制图片,能看到,但是发出来看不到了,也试了从WORD发布博客到CSDN也没有发成功,所以转成图片发过来,如果需要清晰版本,方便的话可以在我的资源里免积分下载:http://download.csdn.net/detail/shizhixin/9406103