FAST-ER角点检测算法详解(改良的FAST算法)
FAST-ER是FAST算法原作者在2010年提出的,它在原来算法里提高特征点检测的重复度,重复意味着第一张图片内的检测的点,也可以在第二张图片上的相应位置被检测出来,重复度可以由如下式子定义:
这里的Nrepeated指第一张图片内的检测点有多少能在第二张被检测到,而Nuseful定义为有用的特征点数。这里计算的一组图像序列的总的重复度,所以Nrepeated和Nuseful是图像序列中所以图像对的和。
在衡量检测的特征点是否能在第二张图像上被检测到,这也是一个大问题,通常的方法先将第一张图像内的点进行变形,使其能匹配第二张,然后再将变换的特征点位置同第二张对应位置比较,看是否被再次检测到,这里也允许一定误差,一般会在3*3的窗口去寻找(也就是说大概只允许一个像素的误差)。
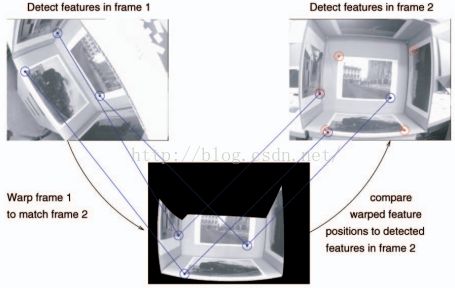
然后实际上,由于视点变化等形变较大因素造成的形变,很有可以使角点检测偏移到不同位置,所以这个邻近区域搜索,找到匹配的特征点是很难确定的,如果搜索范围大太,一方面容易把不匹配的点检测到,另一方面计算量也增大。而如果搜索范围太小,则容易把本来匹配点给忽视了,从面减少重复率。
由于一些形变较大因素造成的形变,很难通过简单且固定的模板将所以的角点检测出来,而原来的FAST算法其决策树的结构是固定的三层树,并不能最优的实现区分角点(实现最优的重复率)。FAST-ER就是针对这样的问题而提出的,其主要是通过模拟退火(也有通过最速下降法的)优化原先决策树的结构,从而提高重复率。
一、引入角点检测的不变性
原先一个像素点及其附近的点送往决策树进行比较时,只需要比较两个位置的点,如果这个点被检测出是角点,但在其区域发生一定旋转、变形或强度反转(白变黑,黑变白)之后,再次重新判定,很有可能被认为是非角点。
在这种情况下,为了使角点检测具有旋转、反射、强度倒转等不变性,最简单的办法就是将所以变化后的结果都计算,即不同的变换建立不同树,只要有一个树能检测出角点,即是角点。不过这样的话,计算量太大,为了减少计算复杂率,每次树被评估时,一般只需要应用16种变换:四个旋转方向变化(各相差90度),并结合反射(对左右对称及上下对称)同强度倒转,共16个变换操作。如果一个点能被6种变换中任一种的决策树视为角点,那么这个点就是角点。
由此以来我们建立了16棵对应不同变换的决策树。
二、决策树的结构优化
对于FAST算法来说,原来的三层决策树太过简单,不能达到最好得重复度,而重复度是关于决策树结构的非凸函数,这涉及到非凸函数的优化问题,这里许多方法,而FAST-ER则是通过模拟退火方法来优化决策树的。
(1)退火温度
首先考虑建立树的总成本如下:
这里的r定义为重复率,di定义为第i帧检测的角点数,而N定义为总共的帧数,s是决策树的大小(树共有多少个节点),ws,wn,wr指影响因子。注意,为了提高计算效率,重复率以一个固定的阈值t和每帧固定数量的特征点来计算。
因为每次迭代过程,我们都需要对原树进行随机调整(启发式随机寻找最优),这些调整可以通过波尔兹曼接受准则来实施,其在第I次迭代中接受调整概率为P:
![]()
这里的是接受标准之后的成本,而T是退火温度:
这里的Imax是最大的迭代次数。
(2)扩大的判定位置
通过随机调整决策树,从而找到最优的重复率,而这个调整涉及到两个方面,一个是树节点选择分类的x位置,另一个是整个树的结构。
每个树的叶子确定分类(如果为1,则是角点,而为0,则不是),而每个节点都有一个对应的判断位置x,FAST是圆环上的其中一点,而在引入退火方法,我们需要给这个位置引入一个相对于中心点的随机偏移,进一步扩大判断位置的选择范围。随机偏移如下定义(共有48个选择位置):

(3)决策树的调整
通过模拟退火的方式来随机调整树,首先选择树中的一个节点(不能是根结点),然后调整它(调整概率P,上面定义过了,随着迭代次数,其越来越趋于稳定),如果:
A)如果挑选的点是叶节点,那么其有相等的概率做如下:
Ø 用一个深度为1随机子树节点代替,将其下继续分成三个叶结点
Ø 翻转叶子的分类(由角点变为非角点,或相反),如果叶子的类被严格限制就不进行此操作(如s子树的叶节点被限制为非角点,因为已经有两个位置检测为同中心相似,这样的点肯定是非角点,可以保证在阈值t增加时,其角点数将通常会减少)
B)如果节点,那么其也有相等概率做如下操作:
Ø 将偏移位置用新的随机偏移位置[0,47]代替,并更新下面的叶结点,前面B)有说明。
Ø 将节点用随机叶节点代替(也要满足以上限制条件)
Ø 移除节点随机选择的分支,并用该节点下另一随机选择的分支拷贝到其位置,比如,b分支可以由s分支代替。
(4)迭代过程的终止
通过对决策树的这些随机调整,树最后很可能不是原来FAST的简单三层树了。树调整后,再对结果应用FAST-9,进一步确定角点,计算新的重复率,如果重复率比原来的重复率高,那么我们就将当前结果视为我们目前最优树,继续应用上面决策树调整,最终在达到一定程度重复率或迭代次数时,停止迭代过程。这个优化也可以通过不同的多个随机种子来运行。我们包含了这些调整可以让FAST-ER更容易地学习到相似的结构。
三、其作用和总结
因为每个迭代过程中,都需要对重新应用新的决策树进行检测,而且16个变换中每一个都需要对应一个候选树,所以这样的检测算法并不十分有效,因此,从效率上考虑,上述的算法一般用于产生训练数据,之后获得较为精确的角点检测结果,我们就可以通过原来的FAST算法来产生单个树。
参考文献:
Faster and Better : A Machine Learning Approach to Corner Detection (提出FAST-ER的论文)
Machine Learning for High-Speed Corner Detection (FAST的原文,上面的论文也是这个作者写的)
FAST角点检测方法详解 (本人关于FAST算法的博文)