机器学习基石第四讲:feasibility of learning
博客已经迁移至Marcovaldo’s blog (http://marcovaldong.github.io/)
刚刚完成机器学习基石的第四节,这一节讨论机器学习的可行性,用到了Hoeffding’s inequality等概率的知识,需要仔细揣摩。笔记整理在下面。
Learning is Impossible?
前面的课程中曾提到过说学习可能是不可行的,为此我们还通过推导来证明PLA算法是否会停下来。那我们再来考虑这个问题,看看学习是否可行。
我们先来用我们的’human learning’来解决一个二元分类问题,如下图示,图中给出了3个标记为-1的图案和标记为+1的图案,然后我们来猜一下下面的那个图案应该标记为什么。
其实无论你猜+1还是-1,都可能是错的,因为有不同的分类标准。我们观察一下上面的6个图案,我们可以发现标记为+1的3个图案都是对称的,标记为-1的3个图案都是非对称的,基于这样的分类标准我们可以将下面的图案标记为+1;我们还可以发现标记为-1的3个图案的左上角均为黑色,标记为+1的3个图案的左上角均为白色,基于这样的分类标准我们可以将下面的图案标记为-1。这说明,当问题存在着两个不同的标准时,我们无法判定我们的g的正确性。
下面再来一个例子。问题的输入是三位的二进制数字,输出是圈圈和叉叉,下图给出了训练集(其中有五组数据),我们用PLA去跑出一个g,并看看这个g跟我们理想的目标f是不是很接近。这个问题的输入只有8组数据,我们已经有了5组数据的输入,对于另外3组的输出我们可以遍历给出,也就是说另外3组数据的输出应该是下图中的1个(八选一)。
我们可以发现这个问题的目标f有着8种不同的可能。我们说,很容易找到一个g,并证明这个g和目标f在训练集上是一致的,但我们不太容易在未知的数据上去证明这个g和f也是一致的(在这个问题中,无论你猜g是8个f中哪一个,我们都可以拿另外的7个说你是错的)。机器学习的目的是从已有的数据集出发,能够正确的处理未知的数据。而在这个例子中,我们无法证明hypothesis是否和目标f一致,也就不知道hypothesis对未知数据的处理是否是正确的,就好像我们没有从数据集中学到什么有用的东西。我们称这样的一个问题叫no free lunch。
其实这一节要说的是,我们无法证明hypothesis对未知数据的处理(标记或分类)一定是正确的,欢聚话说不能证明 h(x)=f(x) 。最后是本节小测试:
Probability to the Rescue
继续讨论学习是否可行的问题,我们考虑是否存在一个东西可以对未知的东西进行一个推论。说现在有一个容器,装有大量的弹珠,有橘色,有绿色,我们想弄清橘色弹珠的比例(数量太大,不能人工一颗一颗去数)。
这里引入Hoeffding’s inequality。我们假设容器中橘色弹珠的比例为 μ (那绿色弹珠的比例就是 1−μ ),且 μ 未知。我们随机的在容器中抽取一个样本,样本容量为N,可以知道其中橘色弹珠的比例为 ν (绿色弹珠比例就是 1−ν ), ν 已知。Hoeffding’s inequality说,当N够大时, ν 和 μ 差距很大的几率是很小的,不等式如下:
现在我们可以说 ν=μ “大概差不多是对的”(probably approximatly correct, PAC)。观察Hoeffding’s inequality,可以看到不等式右侧跟 ϵ 和N有关,跟 μ 无关。这就证明了我们拿抽样得来的 ν 来估计 μ ,当样本容量N越大时, ν 越接近 μ 。
这一小节的结论是,样本容量N够大的话,我们就可以用 ν 来估计 μ ,我们会将这一结论用在下面的推导中。最后是小测试:

Connection to Learning
回到 h(x)=?f(x) 的问题,我们用一个个的弹珠来代表一个个的数据点:对于一个数据点,当 h(x)≠f(x) 时,该数据点对应弹珠被漆成橘色;当 h(x)=g(x) 时,该数据点对应弹珠被漆成绿色。现在整个输入空间就变成了一个装满橘色、绿色弹珠的容器,我们现在要做的就是估计其中橘色弹珠的比例(其实 μ 就是h(x)在整个数域空间上犯错的几率)。根据上一小节引入的Hoeffding’s inequality,在监督式学习中,我们就可以把h(x)在训练数据集上的表现当做一个抽样样本,我们就可以拿h(x)在训练样本上的犯错的几率来估计其在整个输入空间上犯错的几率。加上这些新东西,第一讲中的机器学习的流程图就变成了下面的样子:
这里引入了 Eout(h)=ϵx P[h(x)≠f(x)] 表示h(x)在整个输入空间上犯错的几率, Einh(x)=1N∑Nn=1[h(x)≠f(x)] 表示h(x)在训练数据集上犯错的几率,我们现在拿后者来估计前者,将二者套入Hoeffding’s inequality有:

注意,前面的hypothesis是特定的,其在整个输入空间上的犯错率和在训练数据集上的犯错率相当,如果其在训练数据集上的性能好,那么就可以说其在整个输入空间上是好的。但是H中包含大量的hypothesis,我们的机器学习算法往往是从中选择一个在训练数据集上犯错最小(就是 Ein 最小)的当作最终选定的hypothesis,但这样的hypothesis一定有好的泛化性能,答案是否定的。就是说,我们的算法不能保证最后拿到的hypothesis一定是前面讨论的那个特定的hypothesis。(这个地方不好理解)
关于前面的那个特定的hypothesis的讨论,下面给了一个图:
好吧,这个地方不是特别清楚,所以写得也不够透彻,欢迎指正。 最后是小测试:

Connection to Real Learning
假设现在有M个hypothesis,下图中的M个容器分别代表他们在输入空间上的表现,然后我们分别用 Ein(hi) 来估计 Eout(hi) 。现在有 hM 的 Ein(hm)=0 ,那我们要不要选它来当我们最后的hypothesis呢?我们先来讨论一个抛硬币的问题,一个班级中有150个人,每个人抛5次,假设其中一个人5次全是正面,那我们能说这个硬币很特别吗(对应前面的问题,我们能说 hM 是好的么)?其实算一下就知道,150个人里边至少有一个人5次全是正面的几率是 1−(132)150>99 。

这里的硬币就是前面的弹珠,也就是我们的取样数据集。那么对一个hypothesis来说,坏的data是这样的:hypothesis在它上面的 Ein 很小,而 Eout 很大。Hoeffding’s inequality是说我们抽到这样的坏数据的几率很小。就好比下图中,所有的 Di 加起来是整个输入空间,其中坏的 Di 是很少的。

现在我们有M个hypothesis,那我们选到坏的data的几率肯定是增大了,我们来算一下:
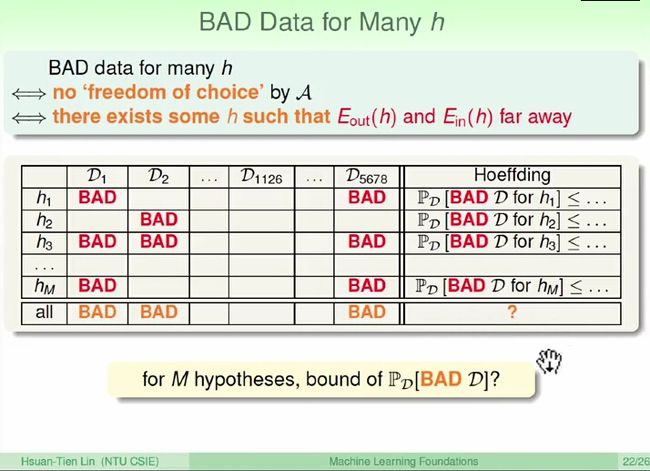
现在我们说,在M有限的前提下,原来的机器算法跑出来的g应该是一个好的hypothesis。现在的机器学习流程变成了下面的样子。其中还有些不明白的点,欢迎上过这个课程的同学指正
到这里,这一讲的结论是在hypothesis数量有限的前提下,我们的机器学习是可行的。但前面说了,hypothesis是无限多的,这又如何解释呢,请看后面的课程。
小测试:

总之,这一讲很难,以后想到什么会改正补充。