Java并发
转载请注明:http://blog.csdn.net/hel_wor/article/details/50841032
这边博客是基于前几天读的《Java并发编程的艺术》一书,但内容不限于此书,自己做了一些扩展和源码阅读,以求能尽可能理解java并发的相关类
从CountDownLatch,CyclicBarrier,Semaphore,Exchanger展开
CountDownLatch和CyclicBarrier都可以用来实现线程的同步。虽然Thread.join()方法也能实现线程的同步,但在源代码里来看,CountDownLatch,CyclicBarrier和Thread.join()都是不同的实现原理。
Thread.join()的源码:
我们调用Thread.join()时实际上调用的是
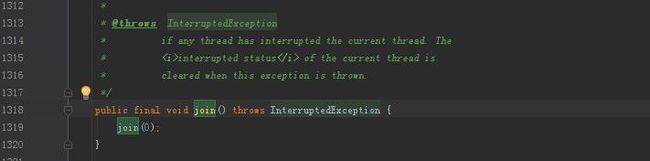
参考Join的源码,可以看见对于给定时间的join,执行到Join内部的那个线程将被阻塞给定的时间后自动唤醒继续执行,但对于未给定等待时间,会被默认等待wait(0);当等待的timeout为0时,则表示一直阻塞,直到被其他线程唤醒。
那么谁来唤醒被join的线程?可以看看这篇博客:JOIN的线程谁来唤醒。
对于被阻塞的这个线程而言,其要等待join()函数的实例线程退出,当实例线程退出时:
static void ensure_join(JavaThread* thread) {
Handle threadObj(thread, thread->threadObj());
assert(threadObj.not_null(), "java thread object must exist");
ObjectLocker lock(threadObj, thread);
thread->clear_pending_exception();
java_lang_Thread::set_stillborn(threadObj());
java_lang_Thread::set_thread_status(threadObj(), java_lang_Thread::TERMINATED);
java_lang_Thread::set_thread(threadObj(), NULL);
lock.notify_all(thread);
thread->clear_pending_exception();退出的实例线程会调用lock.notify_all(thread);唤醒被阻塞的线程。
在读源码有个地方没想明白,也就是给定了等待时间后的那段逻辑,对于那段逻辑,用以下代码也能实现功能:
while(isAlive())
{
wait(millis);
break;
}源代码那样书写是出于什么目的,一直没有想清楚,如果哪位读到这里明白是怎么回事,不妨指点以下。
另外对于Thread.Interrupt(),之前正好在知乎上看到有人说了这个函数,简单来说就是Interrupt()这个函数,不是说调用后线程直接就中断了,因为一个线程的是否中断不应该由其他线程来决定,因此调用了这个函数只是表明这个线程上的isInterrupted这个布尔值被置为了True,具体的操作应该有代码人员加以控制,另外对于一个线程,最好的处理方式是让其在run()方法内执行完,以适应其对资源的释放,而不是中途打断。
所以可以在run()方法体内加一个判断,当发现线程被调用了Interrupt()方法,就不执行run()内具体的逻辑部分。
对于中断,顺便提起下线程的3个被废弃的函数,suspend(),stop(),resume(),
对于三者被废弃的原因:
suspend(): 暂停这个线程,但这个线程在进入睡眠期间并不会释放自己手头占用的资源,所以可以造成出现死锁。
stop(): 这个方法并不会给线程释放手头资源的机会,会导致程序运行在不确定的状态下。
在线程池里使用了shutDown和shutDownNow来关闭线程池,对于shutDown(),其实现原理是为每一线程调用interrupt()方法,然后遍历线程做处理。shutDownNow是直接调用Stop方法,因此会导致资源的来不及释放。
对于CountDownLatch类,其两个主要方法时countdown()和await()方法,await方法有重载使其可以定义超时时间,类的实现是基于AbstractQueuedSynchronizer。具体的源码解析可见这里。
对于countdown()和await(),在其实现里使用到了共享锁,即所有线程线程共享一个锁,当锁被打开后所有的线程都被唤醒,在CountDownLatch中出现了Latch,表明其是一个闭锁,即这个锁一旦被打开后就不能被关闭了,这点与CyclicBarrier是不同的,CountDownLatch实现大致原理是构造函数CountDownLatch(int count)中的count描述了当前的状态值,对应源码里的state变量值,state是一个private volatile long的变量,这个值描述得是有多少个线程可以同时拿到这个共享锁,而获得这个共享锁的条件就是state变为0,当state不为0时:

这段代码保证了线程无法拿到共享锁,于是调用await()方法时,其会进入doAcquireSharedInterruptibly方法。
在循环中判断:
1,是否共享锁可用,以进入setHeadAndPropagate()方法最终调用LockSupport.unpark(s.thread);唤醒线程。
2,否则进入shouldParkAfterFailedAcquire()和parkAndCheckInterrupt()最终调用LockSupport.park(this);使线程等待。
直到某一个线程拿到共享锁后,其他被阻塞的线程均被唤醒。
因此提前使用await()方法线程将被阻塞,直到我们的定义的state个数的线程在每次调用countdown()导致进入tryReleaseShared():
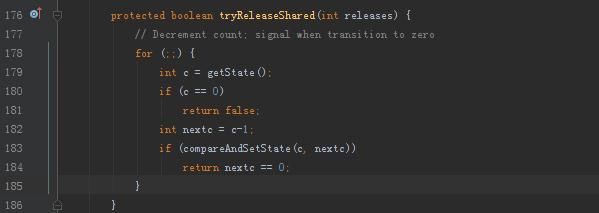
并使得state减1直至到0后,这个时候不管是await()方法的线程还是countdown()方法的线程获得了共享锁,其他被阻塞的线程就都被唤醒。唤醒的大致流程在如上的代码。
在上面提到了volatile ,其能否实现每次都能获取到最新的变量值得原因:
当写一个volatile变量时,JMM会把该线程对应的本地内存的共享变量刷新到主内存中。
当读一个volatile变量时,JMM会把该线程对应的本地内存的共享变量置为无效,线程从主内存中读取共享变量。
CyclicBarrier类作为同步屏障,用于保证线程同步,和CountDownLatch一样,其在构造的时候也需要传入需要同步的线程的数量,但其另一个重载的构造函数作用更大:
当等待的parties个线程都调用了await()方法,即表明其这几个线程全都到达了代码编写人员指定的几个逻辑同步点了,这个时候就可以唤醒线程继续执行了,但在唤醒之前,线程会优先执行的barrierAction,即我们传入的一个实现了Runnable()接口的类。
Semaphore类,用来做资源控制。
假设一个场景,100个人要过一座桥,但这座桥最多只能承受10个人的质量,那如何控制这个过程?
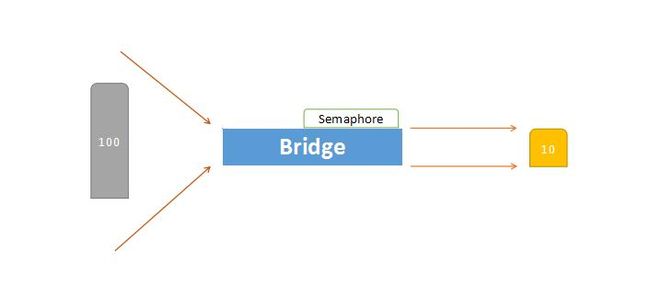
换一个说法,对应于书中的一个场景,把这100个人当做100个线程在抓取数据准备存库,但数据库一次最多允许10个连接,如果超过10个就会报错,该如何控制这个过程?
实现代码:
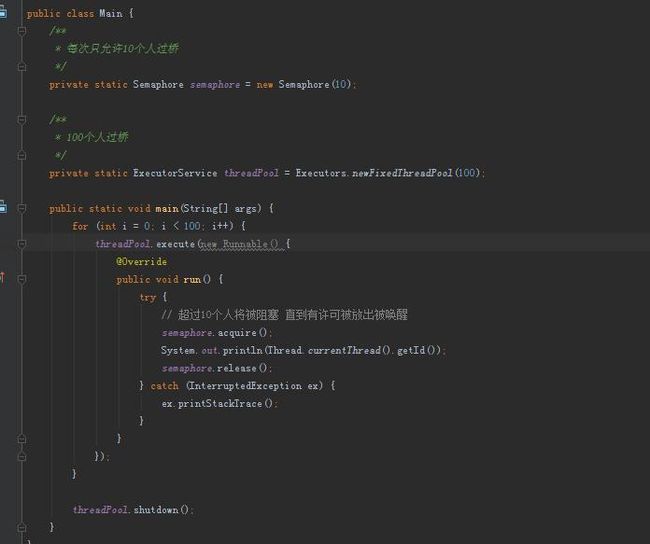
1.Semaphore的构造函数Semaphore(int permits);描述了最大允许permits个线程并发。
2.Semaphore的两个主要方法,acquire()获取许可,如果达到最大并发数导致获取失败则请求线程阻塞,release()归还一个许可。
在上面的示例代码中提到了ExecutorService类和NewFixedThreadPool,那么这里就需要扩展到Executor框架和线程池。
按照《Java7程序设计》一书中的描述,在任何时候,我们都应该尽量不用Java.Lang.Thread线程来执行Runnable任务,而应该用java.util.concurrent.Executor或者其子接口ExecutorService的一个实现来执行Runnable任务。
对于Executor框架而言,其有两个核心接口,一个是Executor,另一个是扩展了Executor接口的ExecutorService接口,由于继承自Executor接口,因此ExecutorService也可以调用Executor接口的唯一方法execute(),execute()只能执行Runnable任务,其不能有返回值,也不能抛出异常。但ExecutorService接口可以使用submit()方法执行Callable任务,其可以有返回值,且能抛出异常。对于Callable任务,重写的方法就不再是run()方法了,而是重写call()方法。
对于返回值Future对象,其方法有get(),cancel(boolean bool);
get()用于获取放回值。
cancel()传入布尔值以表示是否取消任务。
get()有重载方法来设置超时时间。
ThreadPoolExecutor是线程池的核心实现,用来执行提交的任务,而ThreadPoolExecutor和ScheduledThreadPoolExecutor实现了接口ExecutorService接口。
由此对于以下两段代码,就是Executor框架和线程池的联系方式。
private static ExecutorService threadPool = Executors.newFixedThreadPool(100); threadPool.execute(new Runnable() {
@Override
public void run() {
//// do something
}});现在来看看Executor框架和线程池ThreadPoolExecutor间的联系,线程池(包括ScheduledThreadPoolExecutor)实现了ExecutorService接口,也就是说,提交给Executor框架的任务,最终会丢给线程池处理,下图是那么之间的联系:

关于用户级线程和核心线程之间的联系。
在《程序员的自我修养-链接,装载与库》中描述了3中线程模型,分别是用户级线程和核心线程之间的一对一模型,多对一模型,多对多模型。
一对一模型:一个用户级线程对应一个核心线程,这个时候是完全的并发,每个任务对应一个CPU处理(一个CPU可以有多个核心线程)。对于计算密集型的任务,这个时候CPU的吞吐量是最大的,但是用户级线程数量有限导致对于对要求实时性,交互性的任务处理有限。
多对一模型:多个用户级线程对应一个核心线程,一个核心线程的处理时间被分摊到多个用户级线程,提高了对用户操作的响应,但某一个用户级线程的阻塞会导致核心线程的阻塞,也就相应的导致了分配到这个核心线程上的多个用户级线程也被阻塞。
多对多模型:多个用户级线程对应多个核心线程,这是上面两种模型的择优方案,能提高性能也能保证不出现多对一模型的阻塞问题。
对于线程池而言,先来看ThreadPoolExexutor的构造函数:
在Executors类中提供的几中常用线程池的静态方法如newFixedThreadPool(int numofthreads),newSingleThreadPool(),newCacheThreadPool()其原理都是对 ThreadPoolExexutor构造函数配置了相应的参数,所以这里直接理解ThreadPoolExexutor类即可。
当调用了execute()方法,线程池就开始处理任务了.

现在我们来看看线程池的处理逻辑:
路径1:
如果当前池子里的线程数量少于基本给定的基本线程大小参数,则新建线程处理当前提交到线程池的任务。这段代码也描述了,即使当前池子中有空闲线程,也会优先新建线程来处理当前提交的任务。
路径2:
进入到这一步,说明当前线程池中的线程数量已经超过设定的基本线程大小参数了,接下来的处理方式有两种,第一是将任务加入到队列缓存起来等待空闲出来的线程回头来抓取任务继续处理,第二是如果队列也满了,那么判断是否超过设定的最大线程数量(通过maximumpoolsize设定),如果没有超过则新开线程,如果超过了就调用饱和策略处理。回到代码中,if (isRunning(c) && workQueue.offer(command)) 描述如果线程池没有没shutdown(注意逻辑操作的短路功能),这个时候再判断能否成功将任务提交给队列,提交成功后进入if体内,做二次检查,如果这个时候线程池被shutdown(注意短路功能)并且任务被移除,那么调用饱和策略,否则再判断workerCountOf(recheck) ==0;
那么来看看workerCountOf的定义:
也就是当且仅当当前工作线程数量小于线程池容量时(用参数maximumPoolSize决定),才新开线程,注意,新开的线程并没指定要处理的任务,也就是说这个线程是直接去队列中抓取任务出来处理。
由此,我们也就可以解释为什么对于CachedThreadPool线程池而言,其会造成在任务提交速度高于线程处理任务的速度时,极端情况下不断新建线程直至耗尽服务器内存。
路径3:
进入这一步,说明线程池已经被shutdown,但更多时候是说明队列已满,已经无法再想队列中添加缓存任务了。我们先来看看addWorker的源码:
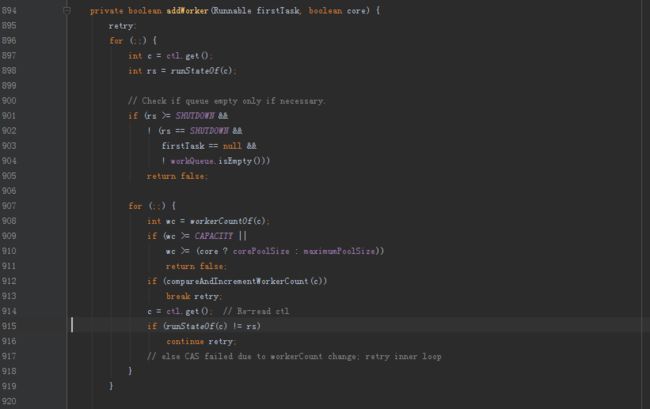
先描述一个内容,关于标签。
在《ThinkInJava》中有对标签的描述,其可以看做是goto语句的改良,将程序的跳转范围限定在了顺序体附近,其用法即为源码中的
retry:
for(;;)
{
for(;;)
{
//// Todo something
break retry;
}
}当执行到break retry,程序会跳转到标签retry处继续向下执行,当然这个功能也可以使用内置标志位来实现多层跳转。
另外在C/C++中是用goto语法的,但在java用C++实现时,是没有把goto语言释放出来让我们使用的,因此Java中没有goto的用法。
回到源代码中:
这段代码对当前池子中的线程数量是否超过了给定的最大线程数进行了判定,因此在路径3中,如果这段逻辑被判定为true,会调用饱和策略。
另外,当线程池中用于缓存任务的队列使用了无界队列时(不如用链表构造的队列),除非线程池在进入路径2前就被shutdown了,否则是永远不会进入路径3的,因为无界队列永远不会存在队列已满的情况。不会拒绝任务,为了处理这些任务对于CachedThreadPool而言由于其maximumPoolSize设定的是Integer.MAX_VALUE,其有权限一直创建线程,这也是造成CachedThreadPool线程池耗尽内存的一个诱因。
对于饱和策略:
其有4中实现方法。
AbortPolicy: 直接抛出异常
CallerRunsPolicy:由调用execute()方法的线程来执行
DiscardOldestPolicy:由于队列是FIFO,所以Oldest就表示当前队列中的下一个成员,丢弃当前队列下一个成员并把当前任务加入到队列。
DiscardPolicy:直接丢弃任务不做处理。
ThreadPoolExecutor的处理逻辑大致描述完全了,接下来就描述几种常用的线程池:


如果阅读了上面描述得线程池ThreadPoolExecutor的处理过程,那么这三种常用的线程池就比较好解决了。另外在newFixedPool和SingleThreadExecutor中空闲线程的超时时间都是设置为0,也就是说当工作线程处理完当前任务后,如果队列中可抓取回来处理的任务,那么这条空闲线程会被立即终止。