基于相似性预测用户答题正确率
基本思路
我们的基本思路是以被审核用户的用户正确率,以及用户之间的答案相似程度为基础,采用加权平均策略来生成预测正确率。
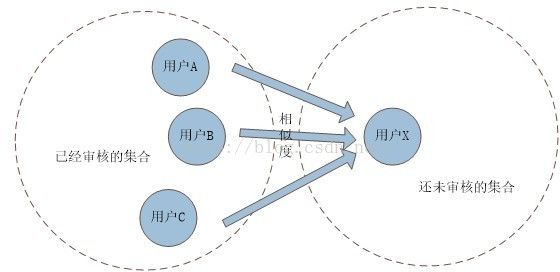
我们将所有用户划分为两个集合:已经被审核的用户集合以及还未被审核的用户集合。通过上述的基本思路,只要已经被审核的用户集合足够,且未审核集合中不存在“孤岛”(这些用户没有和其他用户一起回答过题目),那么经过数轮迭代,所有用户都可以获得各自的正确率。
测试数据
表中列出了所有假设的题目的标准答案和每个用户的答案。其中,产品线仅审核题目1-3,而用户A和B被定为已被产品线审核的用户。C和D虽然也有审核正确率,但是仅作为最终预测正确率的参考。由于设计时间较短,这里数据较少,也没有覆盖所有情况,最终的效果希望直接使用用户的答案进行测试和验证。
|
|
题目1 |
题目2 |
题目3 |
题目4 |
题目5 |
产品线审核正确率 |
实际正确率 |
| 正确答案 |
A |
A |
A |
A |
A |
- |
- |
| 用户A答案 |
A |
A |
A |
A |
A |
100% |
100 |
| 用户B答案 |
A |
B |
B |
B |
A |
33% |
40% |
| 用户C答案 |
A |
C |
A |
A |
A |
66% |
80% |
| 用户D答案 |
B |
C |
A |
B |
B |
33% |
20% |
为了推测C和D的正确率,需要分析一下用户C和D和其他用户的相似度,结果如下表:
|
|
用户A |
用户B |
| 用户C |
80% |
40% |
| 用户D |
20% |
20% |
使用用户相似度传递正确率
一个最简单的加权方案是使用用户的相似度来传递正确率,公式为:
根据我们的假设,根据该公式计算结果为:
用户C的正确率为(100*0.8+33*0.4)/(0.8+0.4) = 77.7%。
用户D的正确率为(100*0.2 + 33*0.2)/(0.2 + 0.2) = 66.5%。
这种算法存在的问题是当被审核的用户正确率都很高时,通过相似度传递的正确率也会很高,那么答题非常差的用户是难以被直接筛选出来的。例子中,用户D的答题实际非常差,但是直接根据相似度传递的正确率却达到了66%,偏离实际正确率非常多。
对于这种bad case,我们只要分析其相似度即可筛选出这些低质量用户。一般这类答题较差用户和其他用户的相似度较低,如果某个用户的相似度一直非常低,那么这个用户本身就是非常可疑的。
直接用相似度分析正确率
前一种方式对于低正确率用户难以正确评价,因此我们换一个角度,即把相似度作为基准正确率,而将用户原本的正确率作为权重系数。这样做的依据是:如果某个用户正确率很高,那么与他相似度越高的用户正确率也不会低,同时高正确率用户的权重也应该高于其他一般用户。
这种思路下的公式转化为:
![]()
基于上述策略计算的答案如下:
用户C的正确率为(80*1+40*0.33)/(1+0.33)= 70%。
用户D的正确率为(20*1+ 20*0.3)/(1+ 0.3) = 20%。
这种方式可以瞬间发现用户D是在乱答,但是对于用户C的评价偏离较多。这是因为我们例子中答题正确和答题错误的用户比例为1:1,导致答题错误的正确率影响过高。正常情况下,我们的用户都纯洁善良,因此我们可以假设有10个A一样的用户和1个B一样的用户,这样用户C的正确率为(80*1*10+40*0.33)/(1*10+0.33)= 78.7%,和实际值非常接近。
优化的一些讨论
实装算法前,我们需要进一步考虑的参数包括:审核题目数的有效下限,以及已审核正确率权值。
所谓审核题目数的有效下限,指的是当产品线审核该用户超过某个阈值时,该正确率才会被正常使用。设定这个值的道理很简单,如果一个用户仅被产品线审核了3道题,其中他只答对了1道题,而其他没有审核的题目实际上他都答对了,那么用这三题来评判这个人是相当不理智的。所以设定这个下限是必要而科学的。
考虑到有效下限的问题,此时有一部分产品线已经审核产生的正确率因为不满足下限要求而不能加入到迭代过程中,这将浪费这些为数不少的极具参考价值的数据。因此对于这些审核正确率,可以考虑使用一定的权值混入到我们的正确率预测公式中,例如修正公式为:
对于审核题数,我们只需要考虑较小情况,该公式的表现(较大情况中,审核正确率可以直接体现用户正确率,不需要预测啊喂!)。
如果用户答题较多,但是被审核较少,那么用户基于其他用户预测的影响就会较大,那么加权作用并不会起到决定性影响。这种作用正好解决了“审核题目数的有效下限”中讨论的以偏概全问题,因为群众的眼睛是雪亮的。。。
如果用户答题较少,那么和其他用户的相似性数据也较少,此时已审核正确率会主导用户预测正确率。这种情况下,已被审核题目在用户所有答题中占比不低,具有一定代表性。退一步讲,用户答题较少,正确率评价依据过少,同时预测准确的必要性也不强。所以这种情况下,公式也挺好的。
结语
不论是“使用用户相似度传递正确率”还是“直接用相似度分析正确率”,以及加权修正公式,都是比较粗糙但是具备一定依据的预测方式。更多的优化方案还是需要结合已有数据进行测试和调优的,不是瞎BB能够解决的。
由于水平和时间有限,这里给出的主要是设计和思路,希望大家能够指出不足,多提意见。