数据库索引优化入门
一 前言
本篇文章主要讲述数据库索引的基本原理,及基本的数据库优化的知识。
二.基础知识
2.1 页
数据库文件存储是以页为存储单元的,一个页是8K(8192Byte),一个页就可以存放N行数据。我们常用的页类型就是数据页和索引页。一个页中除了存放基本数据之外还需要存放一些其他的数据,如页的信息、偏移量等,如下图所示。
虽然SQLServer是以页为单位存储数据,但是其分配空间是以一个盘区为单位的(8个页=64K),这样做的目的主要是为提高I/O的性能。

2.2 B树
B树即二叉搜索树,所有非叶子节点最低拥有两个子节点,基本信息如下图所示。都是小的元素放左边,大的元素放右边。比如说要查找某个元素,其时间复杂度就对应该元素的深度,如要查询9,从根节点开始,只要比较三次就找到他了,其查询效率是非常高的。
子节点:最多两个子节点(指针分别指向Left和Right)
阶数(节点子节点个数):2
深度:就是层数,各个叶子节点不一定一样,如节点21的深度为4,40的深度为3
2.2 B-树
B-树是一种多路搜索树,其阶数可以自定义(>2),是很多数据及文件系统应用的一种常用的索引结构,基本特征如:
1) 阶数(M)>2,即孩子数量大于2个
2) 每个结点存放至少M/2-1(取上整)和至多M-1个关键字,即[M/2-1,M-1](取上整)个关键字;(至少2个关键字)
3) 非叶子结点上的多个关键字是按照顺序排列的:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
4) 所有叶子节点都位于同一层,因此叶子节点的深度都是一样的
5) 非叶子结点的关键字个数=指向儿子的指针个数-1;
6) 非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
如下图是一个三阶的B-树,节点[18]有两个指针分别指向其2个子节点。

这时如果要插入一个值17,其处理步骤:
1) 从根节点进入,17小于22,进入左边的节点[18];
2) [18]不是叶子节点,继续向下搜索,17小于18,进入其左边的子节点[12,16];
3) [12,16]为叶子节点,插入到该节点;
4) 节点[12,16,17]元素大于2了(3阶树的节点关键字数量应>3/2-1,<3-1),因此该节点需要分裂,分裂中间的元素16到父节点18中去;
5) 12,17分裂成了两个子节点了;
分裂后的效果如下图

以上图片效果来自一个外国大学里面的的在线版B-树的测试,网站:http://www.cs.usfca.edu/~galles/visualization/BTree.html ,大家可以去这个网站测试,效果很直观,外国人就是牛。
2.3 B+树
B+树是B-树的变体,也是一种多路搜索树,一棵m阶的B+树和m阶的B-树的差异在于:
l) 非叶子节点的子节点和其关键字相同,即节点有三个元素(关键字),他就肯定有三个子节点;
2) 非叶子节点的子节点P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
3) 所有叶子节点增加一个链指针;
4) 所有关键字的数据都在叶子节点中;
如下图所示,图片来自网络(http://www.cnblogs.com/chjw8016/archive/2011/03/08/1976891.html)。

三 索引存储
B+树和B-树是数据库广发应用的索引存储结构,它可以极大的提高数据查找的效率。关于B-树、B+树的原理与应用的详细可以参考文档:http://blog.csdn.net/hguisu/article/details/7786014
前面2.1中我们讲了SQLServer中使用页为存储单元的,那么在建立索引时,其索引节点就是页了,然后树的键值就是存放到这些页(节点)中的。就是说表中的数据行就是存放到页上的,一个表有多个页构成,这些页以树的结构存放。
3.1 聚集索引
如下图为聚集索引的存储结构(图片来自网络)。其中可以看出页有两种:Index Rows(索引页)、data rows(数据页),所有非叶子节点都存放着索引项,数据行是存放在叶子节点中的,只有叶子节点才真实存放着表中的每一行数据,而其他非叶子节点的页都存放着聚集索引的键值。因此查询数据的时间复杂度都是一样的,就是该树的深度。
叶子节点存放表中的真实的数据,非叶子节点的页存放索引项。
在4.2中有说明,聚集索引决定了表数据的存储顺序,具体可以参考4.2。若表没有创建聚集索引,则表数据时一个无序的堆结构。

3.2 非聚集索引
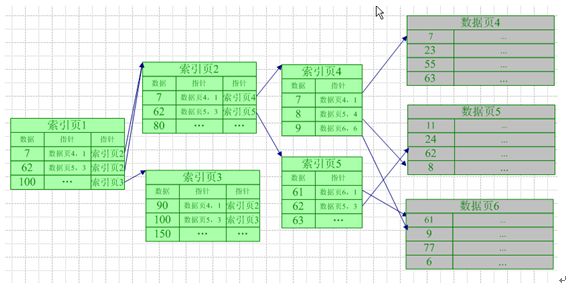
与聚集索引的存储结构唯一不一样的,就是非聚集索引中不存储真正的数据行,因为在聚集索引中已经存放了数据,非聚集索引只包含一个指向数据行的指针即可。如下图所示(图片来源:http://www.cnblogs.com/ashou706/archive/2010/06/08/1754164.html):
四 数据库优化
数据库优化的一个重要参数指标就是“逻辑读”(Logical Reads),可以使用命令SET STATISTICS IO ON来打开消息提示,如下图所示。
逻辑读(Logical Reads):我们在查询数据时,数据时从缓冲区(内存)中读取的,而不是直接从磁盘读取数据的。数据库会预先把数据读取到数据缓冲区中,存放到8K字节的页中。逻辑读就是从缓冲区中读取页的页数,这个才是真正反映查询效率的指标,一般情况下,一个查询的逻辑读越小,其效率越高、速度就越快。同时,同样的SQL查询同样数据集,每次的逻辑读是一样的。
物理读取(Physical Reads):真正的从磁盘读取数据到期缓冲区,在SQLServer执行查询前,会先检查其需要的数据是否在缓冲区中,若不在,就会从磁盘读取数据到缓冲区。这一块是数据库本身的职责,我们在做查询优化的时候不用太关注的,只要给数据库服务器提供足够的内存就OK了。
预读(Read-Ahead Reads):数据库为优化查询,预先读取一部分数据,这个值在优化中可以不用关注。由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
数据优化的一个主要手段就是查看SQL的执行计划,通过查看具体SQL执行过程,可以看出索引的使用是否正确,了解查询中性能问题在哪,从而解决问题。

4.1 T-SQL优化基本常识
1.在Where条件中尽量不要在=号左边进行函数、运算符、或表达式计算,如Where DATEDIFF(DD,StartTime,GetDate())=6 ;或Where Num/2=100;
2.在Where中尽量避免出现!=或<>操作符;
3.在Where中尽量避免对字段进行null值判定;
4.使用Like关键字进行模糊查找时,不要使用前置百分号,如Like ‘%123%’;
5.数据库字段的长度尽量的小(保证应用的前提下);
6.不要使用Selecte*,不要使用*号来查询数据;
7.尽量避免使用游标,游标的效率是很差的,可以使用While循环来代替;
8.尽量避免返回大量数据(查询数据(Select)优化,分页处理等);
9.使用Exists代替in和not in;
4.2 聚集索引
聚集索引决定了表数据的物理存储顺序,也就是说表的物理存储时根据聚集索引结构进行顺序存储的,因此一个表只能有一个聚集索引,SQLServer的聚集索引属性如下图。

该索引的的创建脚本:
/****** Object: Index [Index_KeyId] Script Date: 08/12/2013 15:25:59 ******/
CREATE UNIQUE CLUSTERED INDEX [Index_KeyId] ON [dbo].[User] ( [KeyId] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
因此我们可以得出一个个结论:根据聚集索引的查找效率是比较高的。若表没有建立聚集索引,则表的数据存储是乱的,数据就是一个堆,没有任何顺序可言,对表的查询经常会扫描全表,造成性能较低。一般我们在实际使用中,大多会对主键建立聚集索引,一般这么做就足够了,但实际应用应该尊从一个原则就是“频繁使用的、排序的字段上”,如果要深究的话,可以参见文章结尾的参考目录其他同学的文章。
对应与聚集索引,所有其他的索引可以统称为非聚集索引,非聚集索引的创建会单独创建索引文件来存储索引结构,因此在创建其他索引的时候也要注意硬盘空间。比如一个表的容量是2000w行,大概有800Mb,创建的一个非聚集索引可能数据立马增加好几个G。具体如下4.3、4.4所述。
4.3 覆盖索引
覆盖索引就是在原本索引的基础上,把Select中需要的字段放到索引包含列中,这样就不需要再到数据表中读取数据了,这个就叫做覆盖索引了。 比如,我们查询User表中的字段UserName、Age,其中UserName上创建了非聚集索引,查询语句及索引脚本如下:
Select UserName,Age from [User] where UserName ='Ryan'
--UserName的索引
CREATE UNIQUE NONCLUSTERED INDEX [Index_UserName] ON [dbo].[User] ( [UserName] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
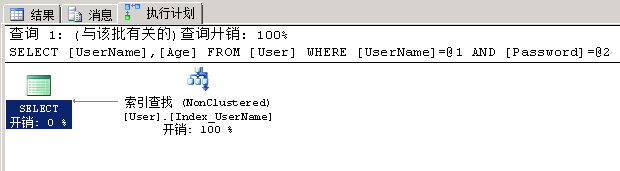
通过UserName条件查询到数据后,还需要Age字段的值,该非聚集索引没有她的数据,还要到数据页中取其Age数据(就是图中的键查找),这样会造成额外的开销,查询计划如下图。

若把Age放到该索引的包含列中,该索引就会包含Age的值,查询的时候就可以直接返回UserName、Age的值了,UserName、Age的覆盖索引脚本及SQLServer的管理视图如下:
CREATE UNIQUE NONCLUSTERED INDEX [Index_UserName] ON [dbo].[User] ( [UserName] ASC ) INCLUDE ( [Age]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO

创建了覆盖索引后的查询效率明显高了,执行计划如下图,其中就没有了循环键查找了:

关于覆盖索引更详细的文章,可以参考文章:SQL Server 查询性能优化——覆盖索引
4.4 复合索引
在上面的索引例子中都只是在一个键上建立索引,但实际情况中往往一个查询会有多个查询条件,如下的sql语句中,多了条件Password:
Select UserName,Age from [User] where UserName ='Ryan' and Password='123456'
该索引中是没有关于Password字段的任何信息,因此查询也会引发键查找,查询计划如下图

对于这种情况,复合索引的用途就来了,简单来所,复合索引就是在多个列上建立索引。Sql脚本及SqlServer的索引属性视图如下:
CREATE UNIQUE NONCLUSTERED INDEX [Index_UserName] ON [dbo].[User] ( [UserName] ASC, [Password] ASC ) INCLUDE ( [Age]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO

创建复合索引后再次执行刚的查询,观看查询计划,查询有明显的改善:
在使用复合索引时,应注意多个索引键的顺序问题,这个是会影响查询效率的,一般的原则是唯一性高的放前面,还有就是SQl语句中Where条件的顺序应该和索引顺序一致。
4.5 页填充因子
通过前面的了解我们知道数据时存放到树上的页中,当插入数据时,如果该页已经存储满了,就要进行页的拆分,频繁的拆分,会产生较多的索引碎片,影响修改和查询数据的效率。
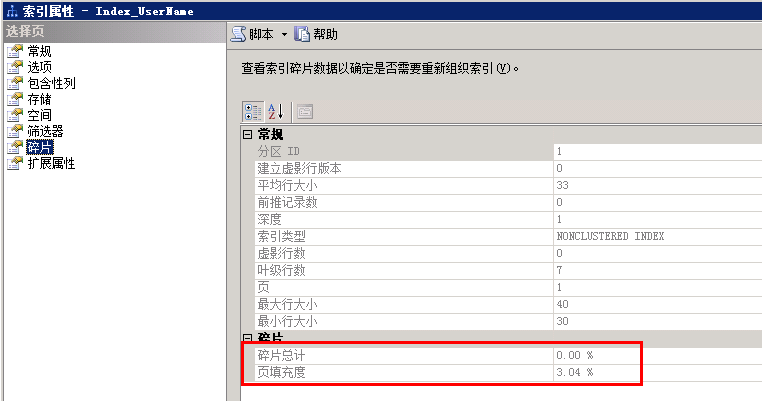
填充因子就是用来描述这种页中填充数据的一个比例,一般默认是100%填充的。如果我们修改填充因子为80%,那么页在存储数据时,就会剩余20%的剩余空间,这样在下次插入的时候就不会拆分页了。 那么是不是我们可以把填充因子设置第一点,留更多的剩余空间,不是很好嘛?当然也不好,填充因子设置的低,会需要分配更多的存储空间,叶子节点的深度会增加,这样是会影响查询效率的,因此,这是要根据实际情况而定的。那么一般我们是怎么设置填充因子的呢,主要根据表的读写比例而定的。如果读的多,填充因子可以设置高一点,如100%,读写各一半,可以80~90%;更改多可以设置50~70%。SQlServer的的索引属性中有一个设置填充因子的项,如下图。
更详细的信息可以参考:http://www.cnblogs.com/cxd4321/archive/2010/08/16/1800677.html

4.6 索引碎片
我们在前面了解到索引的结构就是B树,当树在增加、删除的时候,会触发页的拆分或合并,这种频繁的操作会产生索引碎片,造成索引不连续,当索引碎片曾多时,是会影响查询效率的。因此,访问使用的是随机的i/o,而不是有顺序的i/o,这样访问索引页会变得更慢。因此要定期的清理索引碎片,一般的方法就是重建索引。关于索引碎片的整理,可参考:http://www.cnblogs.com/mywebname/archive/2007/11/13/958463.html
4.7 索引优化注意事项
Ø 建立索引的字段尽量的小,最好是数值;
Ø 尽量在唯一性高的字段上创建索引,不要在性别这种唯一性很低的字段上创建索引;