Hadoop 词频统计(续)
上一篇文章(http://blog.csdn.net/zythy/article/details/17852579)提到,词频统计的结果不是我们理想的结构,不够直观。这一篇文章我们继续优化统计结果。
上一篇程序运行的最终结果如下,单词字符数相同的词频统计结果放在一个单独的文件中,比如长度为5的单词统计结果:
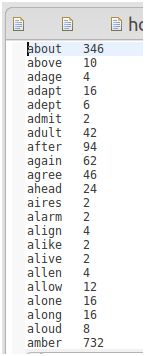
如上图所示,统计结果仅仅是按照Key排序,Value值没有顺序。而我们最终希望的是:
1) 统计结果在一个最终文件中,而不是分散到很多文件中。
2) 统计结果按Value值,及单词出现的频率排序。
应该有很多方法可以实现以上的要求,我们以比较简单的方式来完成这个需求。我们将充分利用Hadoop的shuffle功能。
本质问题是,Map传递给Reduce的键值对是由Hadoop排过序的,而Reduce的输出结果本身不会进行排序。虽然我们看到的每一个Reduce的输出结果是按Key排序的,但是这种有序结果不是Reduce处理而来的,而是因为传递给Reduce的输入是有序的。(可参考Hadoop的Shuffle功能介绍)。
回到主题,如果我们能将上图的统计结果的Key和Value互换,变成以下形式:
346 about
10 above
4 adage
16 adapt
6 adept
2 admit
42 adult
然后经由Map处理(及时Map什么都不做),则Map后的输出将会按照Key排序,变成如下形式:
2 admit
4 adage
6 adept
10 above
16 adapt
42 adult
346 about
这个不正是我们所需要的吗? 正是!
但是此时另一个问题将会出现,有可能多个单词出现的频率一样,比如 is 和 are均出现100此,则Map的输入文件中将会有:
is 100
are 100
而Map处理后的输出中将只会有are而没有is:
100 are
道理很简单,key值是唯一的。
此时我们可以将key和value组合成一个新的复合key,比如:
0000100is is
0000100are are
新的key值包含词频数据和单词本身,这样我们就能保证Map的输入中的每一个键值对都可以得到保留。而且,Map的输出文件按照新的Key排序后,本身词频也变成有序的了。
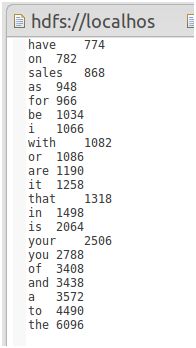
下一步就要交给Reduce来处理了,Reduce重新将键值对翻转,但是在处理Reduce的Value,即词频数值时,需要从输入的key中做截取。(我们可以采用前补零的方式将词频数值统一处理成10位长度,外加单词本身作为Key)。
最终结果如下图:
源代码下载
完整源代码下载地址:
http://download.csdn.net/detail/zythy/6811871
如果你通过Hadoop提交作业,输入的命令行如下:
其中file:///home/user/Desktop/Downloads是数据文件的存放路径
后两个参数分别为作业1和作业2的输出文件地址。
注:我们采用了两个作业来处理这个需求。