字符编码问题
字符与编码的发展
阶段一 ASCII码
计算机刚开始只支持英语,其它语言不能够在计算机上存储和显示。ASCII码一共规定了128个字符的编码,这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
阶段二 ANSI编码(本地编码)
为使计算机支持更多语言,通常使用0x80~0xFF范围的2个字节来表示1个字符。比如:汉字'中'在中文操作系统中,使用[0xD6,0xD0]这两个字节存储。不同的国家和地区制定了不同的标准,由此产生了GB2312,BIG5,JIS等各自的编码标准。这些使用2个字节来代表一个字符的各种文字延伸编码方式,称为ANSI编码。在简体中文系统下,ANSI编码代表GB2312编码,在日文操作系统下,ANSI编码代表JIS编码。不同ANSI编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段ANSI编码的文本中。
阶段三 UNICODE(国际编码)
为了使国际间信息交流更加方便,国际组织制定了UNICODE字符集,为各种语言中的每一个字符设定了统一并且唯一的数字编号,以满足跨语言、跨平台进行文本转换、处理的要求。unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字“严”。需要注意的是,unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
unicode的一种实现——UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
编码规则如下表,字母x表示可用编码的位。
| 字节数 |
二进制表示 |
有效二进制位数目 |
可表示的最大编码 |
编码范围(16进制) |
| 1 |
0xxxxxxx |
7 |
0x7F |
0000 0000-0000 007F |
| 2 |
110xxxxx 10xxxxxx |
11 |
0x7FF |
0000 0080-0000 07FF |
| 3 |
1110xxxx 10xxxxxx 10xxxxxx |
16 |
0xFFFF |
0000 0800-0000 FFFF |
| 4 |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
21 |
0x1FFFFF |
0001 0000-0010 FFFF |
0011 0000-001F FFFF之间的编码暂时不用。
下面,还是以汉字“查”为例,演示如何实现UTF-8编码。
查的unicode是U+67E5(0110 0111 1110 0101),根据上表,可以发现0x67E5处于第三行的范围内,因此“查”的utf-8编码需要3个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。从“查”的Unicode最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。就得到了“查”的utf-8编码:11100110 10011111 10100101,转换为16进制0xE69FA5。
Windows记事本程序可选的编码方式
有:ANSI,Unicode,Unicode big endian和UTF-8。
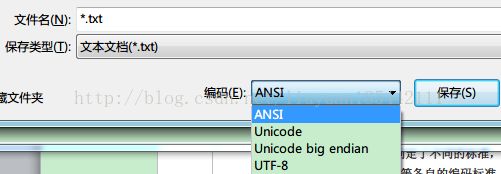
1)ANSI是默认的编码方式。对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对Windows简体中文版,如果是繁体中文版会采用Big5码)。
2)Unicode编码指的是UCS-2编码方式,即直接用两个字节存入字符的unicode码(对于大于2个字节的字符无法存储。UTF-16扩充了unicode,包括了一些稀有字符,想我们国家的满文,藏文等等,两者基本上等价)。这个选项用的little endian格式。
3)Unicode big endian编码与上一个选项相对应。
4)UTF-8编码,也就是上面谈到的编码方法。
Little endian和Big endian
Unicode码可以采用UCS-2格式直接存储。以汉字”严“为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式。
自动检测编码方式——BOM
Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做“零宽度非换行空格”(ZERO WIDTH NO-BREAK SPACE),用FE FF表示。这正好是两个字节,而且FF比FE大1。如果一个文本文件的头两个字节是FEFF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。
在windows中Unicode编码中表示字节排列顺序的这个个文件头,也叫做BOM(byte-order mark),FFFE和FEFF就是不同的BOM。
例如:
1)Unicode:FF FE 表明是小头方式存储。
2)Unicode big endian:FE FF 表明是大头方式存储。
3)UTF-8:EF BB BF 表示这是UTF-8编码。
软件对文本编码的判断
当一个软件打开一个文本时,它要做的第一件事是决定这个文本究竟是使用哪种字符集的哪种编码保存的。软件有三种途径来决定文本的字符集和编码:
最标准的途径是检测文本最开头的几个字节,如下表:
| 开头字节 |
Charset/encoding |
| EF BB BF |
UTF-8 |
| FF FE |
UTF-16/UCS-2, little endian |
| FE FF |
UTF-16/UCS-2, big endian |
| FF FE 00 00 |
UTF-32/UCS-4, little endian. |
| 00 00 FE FF |
UTF-32/UCS-4, big-endian. |
但是某些文本没有这些位于开头的字符集标记,比如centos下的gedit保存文本时就不会添加这些标记。因此,软件不能依赖于这种途径。这时,软件可以采取一种比较安全的方式来决定字符集及其编码,那就是弹出一个对话框来请示用户,例如用MicrosoftWord打开这种文本,Word就会弹出一个对话框让你选择编码。
如果软件不想麻烦用户,或者它不方便向用户请示,那它只能采取自己“猜”的方法,软件可以根据整个文本的特征来猜测它可能属于哪个charset,这就很可能不准了。Windows下的记事本和Linux下的文本编辑器都是这样做的,但是用它们打开或另存为的时候可以选择编码方式。
参考文献
字符编码总结
http://www.cnblogs.com/P_Chou/archive/2010/09/03/1811742.html
记事本编码格式浅析
http://blog.csdn.net/liyangbing315/article/details/5616643