大数据之Hadoop平台(二)Centos6.5(64bit)Hadoop2.5.1伪分布式安装记录,wordcount运行测试
注意:以下安装步骤在Centos6.5操作系统中进行,安装步骤同样适于其他操作系统,如有同学使用Ubuntu等其他Linux操作系统,只需注意个别命令略有不同。
注意一下不同用户权限的操作,比如关闭防火墙,需要用root权限。
单节点的hadoop安装出现的问题会在如下几个方面:JDK环境的配置、防火墙是否关闭、root用户和hadoop用户的不同操作等。
在搭建的过程中细心一点,按照下面的步骤做,基本不会有什么问题的。
一、准备工作(root用户)
1.关闭防火墙
关闭防火墙:service iptables stop 关闭开机启动:chkconfig iptables off
2.创建用户
创建hadoop用户:useradd hadoop 密码:passwd hadoop 加入sudoers:vim /etc/sudoers ,在root下一行写入hadoop ALL=(ALL) ALL
3.修改hosts文件
在/etc/hosts文件最后一行加入:
127.0.0.1 hadoop
二、安装JDK1.8(root用户)
1.查看已装JDK
rpm -qa |grep java rpm -qa |grep jdk

2.卸载上一步显示的程序
rpm -e --nodeps 程序名 (如:rpm -e --nodeps tzdata-java-2013g-1.el6.noarch rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64 rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64)
3.安装JDK1.8
rpm -ivh jdk-8-linux-x64.rpm (在安装文件所在的目录下执行该指令,安装前可将.rpm文件放置在任意目录,左后jdk默认安装在/usr/java/jdk1.8.0 中)
4.修改环境变量
修改 /etc/profile文件,在文件末尾加入以下几行:
export JAVA_HOME=/usr/java/jdk1.8.0 export JRE_HOME=/usr/java/jdk1.8.0/jre export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
5.使刚修改的环境变量生效
source /etc/profile
6.验证JDK是否安装成功
java -version echo $JAVA_HOME

三、SSH无密码登录(hadoop用户)
1.生成密钥
ssh-keygen -t dsa (然后一直按回车即可,会自动生成.ssh文件夹,内有两个文件)

2.生成authorized_keys
进入/home/hadoop/.ssh目录
cat id_dsa.pub >> authorized_keys
3.给authorized_keys赋予执行权限
chmod 600 authorized_keys
4.测试是否能够无密码登录本地
ssh localhost
如果不用再次输入密码,说明成功
四、安装hadoop(hadoop用户)
1.解压到指定目录(以在/home/hadoop目录为例)
tar -zxvf hadoop-2.5.1.tar.gz
2.配置文件
配置文件在/home/hadoop/hadoop-2.5.1/etc/hadoop/目录下
2.1.core-site.xml文件
在<configuration>和</configuration>之间加入如下内容
<property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/hadoop-2.5.1/tmp</value> </property>
2.2.hdfs-site.xml文件
<property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/hadoop-2.5.1/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/hadoop-2.5.1/data</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property>
注意:/home/hadoop/hadoop-2.5.1/data和/home/hadoop/hadoop-2.5.1/name这两个目录应该是存在的。
2.3.mapred-site.xml文件
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
2.4.mapred-env.sh文件
export JAVA_HOME=/usr/java/jdk1.8.0 export HADOOP_MAPRED_PID_DIR=/home/hadoop/hadoop-2.5.1/tmp
2.5.hadoop-env.sh文件
export JAVA_HOME=/usr/java/jdk1.8.0 export HADOOP_PID_DIR=/home/hadoop/hadoop-2.5.1/tmp export HADOOP_SECURE_DN_PID_DIR=/home/hadoop/hadoop-2.5.1/tmp
2.6.yarn-site.xml文件
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
2.将hadoop加入环境变量
sudo vim /etc/profile 加入如下两行 export HADOOP_HOME=/home/hadoop/hadoop-2.5.1 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
五、启动(hadoop用户)
1.格式化namenode
hdfs namenode -format

如果成功,此时,在/home/hadoop/hadoop-2.5.1/name/中会生成current文件夹

2.启动namenode和datanode
hadoop-daemon.sh start namenode hadoop-daemon.sh start datanode
通过jps能够验证是否启动成功
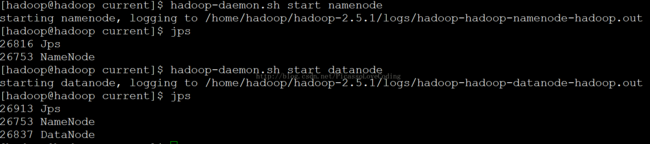
3.启动yarn
start-yarn.sh
输入jps验证

4.在网页端查看
输入IP:50070(例如:http://192.168.56.103:50070/)

六、运行wordcount例子(hadoop用户)
Wordcount例子在/home/hadoop/hadoop-2.5.1/share/hadoop/mapreduce中的hadoop-mapreduce-examples-2.5.1.jar
1.上传本地文件至hdfs
hadoop fs -put 文件 /test (如:hadoop fs -put 1 /test是将本地的文件1上传至hdfs中的/test目录下)
2.运行
hadoop jar hadoop-mapreduce-examples-2.5.1.jar wordcount /test/1 /test/output/1
注意:/test/output/1必须是不存在的目录

3.查看结果
hadoop fs -cat /test/output/1/part-r-00000