solr词库实时更新维护
1、solr导入到eclipse
下载solr-5.4.1-src.tgz,官网地址http://www.apache.org/dyn/closer.lua/lucene/solr/5.4.1
解压solr-5.4.1-src.tgz到D:\project\java\solr-5.4.1目录,在目录的命令行下输入ant eclipse,然后进入漫长的等待过程,中间需要从网上下载很多依赖包。
编译时,可能会报Ivy could not be found in you ant classpath,去ivy官网(http://ant.apache.org/ivy/download.cgi)下载ivy.jar即可。
直到出现BUILD SUCCESSFUL,使用eclipse导入。
打开org.apache.solr.client.solrj.StartSolrJetty,设置solr.solr.home
public class StartSolrJetty
{
public static void main( String[] args )
{
System.setProperty("solr.solr.home", "solr/example/solr");
Server server = new Server();
ServerConnector connector = new ServerConnector(server, new HttpConnectionFactory());
// Set some timeout options to make debugging easier.
connector.setIdleTimeout(1000 * 60 * 60);
connector.setSoLingerTime(-1);
connector.setPort(8983);
server.setConnectors(new Connector[] { connector });
WebAppContext bb = new WebAppContext();
bb.setServer(server);
bb.setContextPath("/solr");
bb.setWar("solr/webapp/web");
server.setHandler(bb);
try {
System.out.println(">>> STARTING EMBEDDED JETTY SERVER, PRESS ANY KEY TO STOP");
server.start();
while (System.in.available() == 0) {
Thread.sleep(5000);
}
server.stop();
server.join();
}
catch (Exception e) {
e.printStackTrace();
System.exit(100);
}
}
}
2、实时更新词库
本文使用Jcseg这个中文分词库,查看org.lionsoul.jcseg.analyzer.v5x.JcsegTokenizerFactory的源码,词库数据保存在ADictionary dic这个变量中,
public class JcsegTokenizerFactory extends TokenizerFactory
{
private int mode;
private JcsegTaskConfig config = null;
private ADictionary dic = null; // 词库变量
/**
* set the mode arguments in the schema.xml
* configuration file to change the segment mode for jcseg
*
*/
public JcsegTokenizerFactory(Map<String, String> args)
{
super(args);
String _mode = args.get("mode");
if ( _mode == null ) mode = JcsegTaskConfig.COMPLEX_MODE;
else
{
_mode = _mode.toLowerCase();
if ( "simple".equals(_mode) )
mode = JcsegTaskConfig.SIMPLE_MODE;
else if ( "detect".equals(_mode) )
mode = JcsegTaskConfig.DETECT_MODE;
else
mode = JcsegTaskConfig.COMPLEX_MODE;
}
//initialize the task config and the dictionary
config = new JcsegTaskConfig();
dic = DictionaryFactory.createDefaultDictionary(config);
}
public void setConfig( JcsegTaskConfig config )
{
this.config = config;
}
public void setDict( ADictionary dic )
{
this.dic = dic;
}
public JcsegTaskConfig getTaskConfig()
{
return config;
}
public ADictionary getDict()
{
return dic;
}
@Override
public Tokenizer create( AttributeFactory factory )
{
try {
return new JcsegTokenizer(mode, config, dic);
} catch (JcsegException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
继续查看org.apache.solr.handler.FieldAnalysisRequestHandler代码,知道可以通过SolrQueryRequest获取到TokenizerFactory
只需要取得JcsegTokenizerFactory对应实例,就能取得dic,通过add和remove方法实时更新词库。
dic.add(ILexicon.CJK_WORD, word, IWord.T_CJK_WORD);
dic.remove(ILexicon.CJK_WORD, word);
自定义实现request handler,在request handler里面通过SolrQueryRequest取得IndexSchema->IndexAnalyzer->TokenizerFactory,最终取得dic实例操作词库,内存中的词库更新后,也需要保存到本地词库文件中,避免重启后丢失词库。实现代码
package com.penngo.solr;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStreamWriter;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.util.TokenizerFactory;
import org.apache.solr.analysis.TokenizerChain;
import org.apache.solr.common.StringUtils;
import org.apache.solr.common.params.SolrParams;
import org.apache.solr.handler.RequestHandlerBase;
import org.apache.solr.request.SolrQueryRequest;
import org.apache.solr.response.SolrQueryResponse;
import org.apache.solr.schema.FieldType;
import org.apache.solr.schema.IndexSchema;
import org.lionsoul.jcseg.analyzer.v5x.JcsegTokenizerFactory;
import org.lionsoul.jcseg.tokenizer.core.ADictionary;
import org.lionsoul.jcseg.tokenizer.core.ILexicon;
import org.lionsoul.jcseg.tokenizer.core.IWord;
import org.lionsoul.jcseg.tokenizer.core.JcsegTaskConfig;
import com.fasterxml.jackson.databind.ObjectMapper;
public class TestHandler extends RequestHandlerBase{
public void handleRequestBody(SolrQueryRequest req, SolrQueryResponse rsp) throws Exception {
SolrParams params = req.getParams();
System.out.println("params=======" + params);
JcsegTaskConfig config = new JcsegTaskConfig();
String addDatas = params.get("add");
Map<String,Object> dataResult = new HashMap<String,Object>();
ObjectMapper mapper = new ObjectMapper();
String lexiconPath = config.getLexiconPath()[0];
String fileLex = lexiconPath + "/lex-penngo.lex";
IndexSchema indexSchema = req.getSchema();
FieldType filetype = indexSchema.getFieldTypeByName("textComplex");
Analyzer analyzer = filetype.getIndexAnalyzer();
TokenizerChain tokenizerChain = (TokenizerChain) analyzer;
TokenizerFactory tfac = tokenizerChain.getTokenizerFactory();
if (tfac instanceof JcsegTokenizerFactory) {
JcsegTokenizerFactory jtf = (JcsegTokenizerFactory) tfac;
ADictionary dic = jtf.getDict();
if (dic != null) {
if (StringUtils.isEmpty(addDatas) == false) {
FileOutputStream fos = new FileOutputStream(new File(fileLex), true);
OutputStreamWriter osw = new OutputStreamWriter(fos, "UTF-8");
BufferedWriter bw = new BufferedWriter(osw);
ArrayList<List<String>> wordList = mapper.readValue(addDatas, ArrayList.class);
for(List<String> word: wordList){
String name = word.get(0);
String type = word.get(1);
String pinyin = word.get(2);
String syn = word.get(3);
IWord iword = dic.get(ILexicon.CJK_WORD, name);
// 如果不存在,则添加到词库
if (iword == null) {
dic.add(ILexicon.CJK_WORD, name, IWord.T_CJK_WORD);
iword = dic.get(ILexicon.CJK_WORD, name);
iword.addPartSpeech(type);
iword.setPinyin(pinyin);
String[] syns = syn.split(",");
for (String s : syns) {
iword.addSyn(s);
}
StringBuffer sff = new StringBuffer();
sff.append(name).append("/").append(type).append("/").append(pinyin).append("/").append(syn);
// 把分词添加到词库文件lex-penngo.lex中
bw.write(sff.toString());
bw.newLine();
}
}
bw.close();
osw.close();
fos.close();
}
dataResult.put("status", "ok");
}
}
rsp.add("response", dataResult);
}
public String getDescription() {
return null;
}
}
solrconfig.xml添加配置
<requestHandler name="/test" class="com.penngo.solr.TestHandler"> <lst name="defaults"> <str name="wt">json</str> <str name="indent">true</str> </lst> </requestHandler>
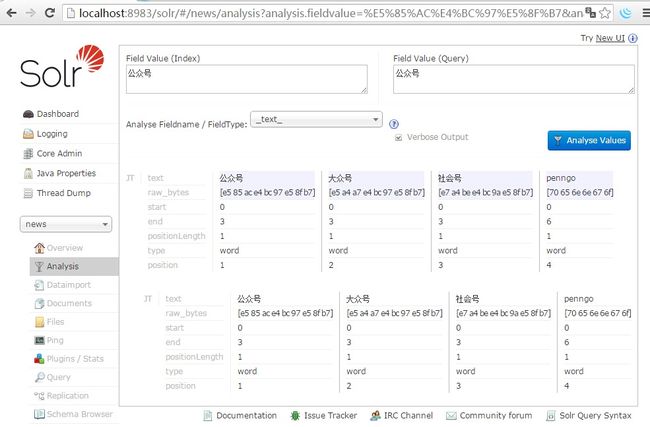
以"公众号"这个词来测试
jcseg自带词库分词结果
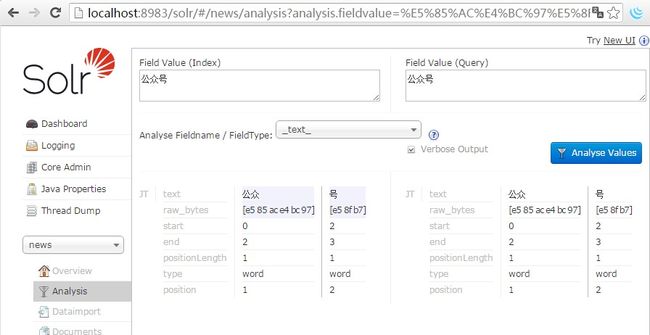
客户端通过接口添加分词后结果,php代码
<?php
$url = "http://localhost:8983/solr/news/test";
$data = array(
array("公众号", "n", "gong zhong hao", "大众号,社会号,penngo")
);
$url = $url . "?add=" . urlencode(json_encode($data));
echo $url . "\n";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
$result = curl_exec($ch);
curl_close($ch);
print_r($result);
?>