MySQL笔记---视图,存储过程, 触发器的使用入门
大二学数据库的时候,只是隐约听到老师提起过视图啊,存储过程啊,触发器啊什么的,但只是淡淡的记住了名字,后来自己做些小项目,小程序,也没有用上过,都只是简单的建表,关联表之类的,导致我对这些东西的理解只能停留在名称的阶段.最近看完了一本薄薄的小书叫<MySQL必知必会>,记了不少笔记,也自己上手实践了一番,总算是了解了些皮毛.
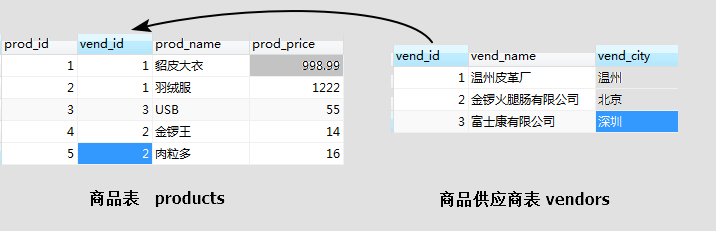
下面通过实例来具体了解这几个东西,首先我的样例表是这样的.
视图:
什么是视图?
视图是虚拟的表,本身并不包含数据,通过一个例子,来更好地理解视图:
假设上述表中,我需要查询指定供应商所提供的商品信息,那么SQL需要这么写:
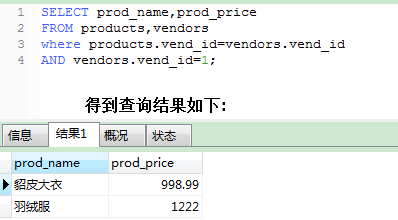
这只是一个简单的双表关联,如果我们实际需求中要出现大量类似这样但是更复杂一些的SQL,那么使用视图会是个很好的选择,如果我把整个查询包装成一个名为prodvend的虚拟表(视图),那么就可以轻松检索出相同的数据.
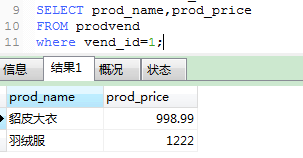
可以看出,我们可以像操作普通表一样对视图进行SELECT,过滤,等操作,而且视图仅仅是用来查看存储在别处的数据的一种设施,视图本身布包含数据,他们返回的数据是从其他表中检索出来的,在对这些表进行更改以后,视图也会同步的更新.
如何使用视图:
视图创建使用CREATE VIEW语句.
上面例子中视图prodvend的创建语句如下:
CREATE VIEW prodvend AS SELECT prod_name,prod_price FROM products,vendors where products.vend_id=vendors.vend_id;
视图的删除使用 DROP VIEW语句.
视图的一些规则:
- 与表名一样,视图名必须唯一
- 视图可以创建无限多个
- 创建视图,需要有用户具有CREATE VIEW权限.
- 视图可以和表一起使用,可以编写一条连接表和视图的SELECT语句.
- 视图可以嵌套,意思是你可以创建一个视图,这个视图中使用了另一个视图.
通过上面的例子,能看出视图最重要的作用就是简化复杂的联结.
视图的应用:
简化复杂的联结(最重要);
用视图重新格式化检索出来的数据:
如上表,假设我们的需要查询某个商品的信息,希望得到这样的格式"商品名(商品价格)".SELECT语句应该这样写:
SELECT CONCAT(prod_name,'(',prod_price,')') AS productInfo from products;
查询结果是这样的:
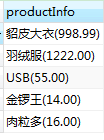
如果经常需要这种格式的结果,就可以创建一个视图,每次需要时使用即可.
CREATE VIEW prodInfo AS SELECT prod_id,CONCAT(prod_name,'(',prod_price,')') AS productInfo from products; --以后如果想查询这种格式的商品信息可以直接使用 SELECT * FROM prodInfo; --如果只想查询某个商品也可以 SELECT * FROM prodInfo WHERE prod_id=1;
使用视图简化计算字段:
同样的道理,如果你在查询中需要频繁使用计算计算,比如求订单表中数量和单价的乘积,也可以创建一个视图来保存这个操作,以后需要的时候可以直接查询视图,这里就不做演示了.
视图的更新问题:
视图一般都是用来检索数据的,即和SELECT一起使用,但是视图也是可以更新的,你可以对视图进行更新(delete,update,insert)操作.如果对视图进行增删改操作,实际上是对基表进行了增删改操作,但是这时有限制的,如果MySQL不能正确的确定需要被更新的基数据那么,则不允许更新.比如如果视图定义中有以下操作则不允许更新:
分组,联结,子查询,聚集函数(MIN(),SUM())等.实际上很多视图都是不可以更新的,但是我们要知道,视图本身就是用来查询的.一般没有更新视图的必要性.
存储过程:
什么是存储过程?
实际中,一个完整的需求通常需要操作多个SQL语句来完成,完成这个需求需要针对多个表的多条SQL语句,编写代码的时候,可以单独编写每一条语句,并根据结果有条件的执行另外的语句.这样做的一个缺点就是,每次需要这个处理时都必须完成这么多工作.这时候就可以通过创建存储过程来完成需求的封装和重用.
存储过程简单来说,就是为以后的使用而保存的一条或多条SQL语句的集合.可以将其视为批文件.
使用存储过程:
创建存储过程:
以上面的表为例,假设我们现在需要知道商品表中最贵的商品,最便宜的商品,以及商品的平均价格(虽然这并没有什么啥意义).我们当然可以写一个SELECT语句,或者三个这样的语句分别查询.使用存储过程应该这样写:
CREATE PROCEDURE productsPrice( --接受三个参数分别为p1,p2,p3参数的类型为DECIMAL(8,2). --OUT关键字用来返回给调用者 OUT p1 DECIMAL(8,2), OUT p2 DECIMAL(8,2), OUT p3 DECIMAL(8,2) ) BEGIN SELECT MIN(prod_price) INTO p1 FROM products; SELECT Max(prod_price) INTO p2 FROM products; SELECT AVG(prod_price) INTO p3 FROM products; END;
执行存储过程:
为了调用上面创建好的存储过程,必须指定三个变量名(MySQL的变量都必须以@开头),如下:
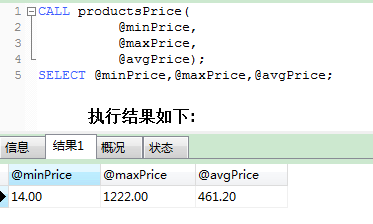
注意:在调用存储过程时,这条语句并不显示数据,它返回可以显示的变量,所以可以直接使用SELECT语句查询变量名即可.
可以把存储过程看过一个函数,函数有返回值,当然也可以传入参数,下面说一个既有参数,又有返回值的存储过程,他可以接收一个商品id,返回该商品的供应商所在的城市:
CREATE PROCEDURE findCityById( --传入参数, 商品id IN prodID INT, --返回变量 商品供应商的city out vendCity VARCHAR(80)) BEGIN SELECT v.vend_city FROM products p,vendors v WHERE p.vend_id=v.vend_id AND p.prod_id=prodID INTO vendCity; END;
使用该存储过程必须给findCityById传递两个参数,第一个参数是商品id,第二个参数是一个用来接收供应商city的变量名,如下:
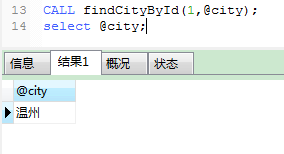
其实以上所写的存储过程都只是简单的封装SQL语句,这么简单的需求使用存储过程只会事情变得更复杂,只有在存储过程中包含复杂的业务规划,和智能处理时它的威力才能显示出来.
删除存储过程:
使用 drop procedure+名称 即可.
存储过程的好处(作用):
通过把处理封装在容易使用的单元中,简化复杂的操作.
由于不要求反复建立一系列处理步骤,可以防止错误,因为需要的执行步骤越多,出错误的可能性就越大,通过使用存储过程可以保证数据的完整性和一致性.
简化了对变动的管理,如果表名,列名,或业务逻辑改变了,只需要更改存储过程中的代码即可,使用存储过程的人员甚至不需要知道这些变动.
触发器:
什么是触发器?
不论是SQL语句还是存储过程,都是在你需要时被执行的,而触发器,顾名思义它是在出发了某个事件时自动执行的.比如下面这些例子:
每当订购了一个产品时,需要在库存数量中减去订购商品的数量.
实际中,无论何时删除一行记录,都需要在某个存档表中保存删除行记录的一个副本.
当插入一个英文名称的列时,确保英文总是大写,不管(insert或update中给出的名称是大写还是小写).
以上的例子有一个共同点就是需要在表发生改动时自动处理某个逻辑.其实这就是触发器.触发器只能在表改动时执行,即只作用于delete,update,insert语句.
创建触发器:
创建触发器,需要给出3条信息:
1.唯一的触发器名(保持每个数据库下的触发器名唯一).
2.触发器所关联的表
3.触发器应该相应的活动(delete,update还是insert),以及何时执行(之前还是之后).
我现在要创建一个简单的触发器,当在商品表products中插入一条商品记录时,显示一句话"insert success!";
注意:在触发器的触发事件中,不能只能写select 'insert success',因为触发器不允许返回一个结果集.
CREATE TRIGGER newProd AFTER INSERT ON products for EACH ROW BEGIN SELECT 'insert success' INTO @info; END;
注意:只有表才支持触发器,视图是不支持的,一个表中最多支持6个触发器,发生在insert/delete/update之前或之后.
-
INSERT触发器中,你可以引用一个名为NEW的虚拟表,访问被插入的行.
-
DELETE触发器中,你可以引用一个名为OLD的虚拟表,访问要被删除的行.
-
UPDATE触发器中,既有NEW又有OLD,保存更新之前和更新之后的记录.
下面演示一个例子,使用OLD将要删除的行存入一个名为backup的备份表中:
CREATE TRIGGER deleteProd BEFORE DELETE ON products for EACH ROW BEGIN INSERT INTO back_up(prod_id,vend_id,prod_name,prod_price) values(OLD.prod_id,OLD.vend_id,OLD.prod_name,OLD.prod_price); END;
执行删除一条主键为1的商品,DELETE FROM products WHERE prod_id=1;会发现在back_up表中多了一条记录,正是被删除的那个商品.
删除触发器:
使用drop trigger +名 删除.
以上都能看懂就算是入门了这三个数据库中比较重要的知识,这也是我现在所处的阶段,我对于书上每个例子都自己实现了一遍,但不保证都正确,我还需要在以后的工作中深入学习~~~