Apache Lucene(全文检索引擎)—创建索引
目录
1. Apache Lucene(全文检索引擎)—创建索引:http://www.cnblogs.com/hanyinglong/p/5387816.html
2. Apache Lucene(全文检索引擎)—搜索:http://www.cnblogs.com/hanyinglong/p/5391269.html
3. Apache Lucene(全文检索引擎)—分词器:http://www.cnblogs.com/hanyinglong/p/5395600.html
本项目Demo已上传GitHub,欢迎大家fork下载学习:https://github.com/kencery/Lucene_Compass(项目内部有很详细的注释)
1. 发生在我们身边的搜索?
a. 当我们去淘宝或者京东买东西的时候经常会用到搜索功能,而他们海量的数据都是存储在数据库的,那么程序猿在实现这个搜索功能的时候,是如何实现的呢?使用数据库的like这时候就变得捉襟见肘,根本不能用了,因为查询速度会很慢,而用户不会为了查询一个东西等待几十秒或者几分钟(正常一个人愿意等待的时间大概为3-5秒),这时候该怎么实现这样的查询呢?
b. 而且它们的查询功能也基本都类似,都是查询的文本内容,都是相同的查询方式 ,即找出含有指定字符串的资源。

2. lucene是什么呢?
a. lucene一个成熟的、开源的、高性能,可伸缩的全文信息搜索库,它可以使你的引用程序添加索引和搜索能力
a.1 全文检索:计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时根据建立的索引查找,并将查找的结果反馈给用户的检索方式,在信息检索工具中,全文检索是最具通用性和实用性的。
b. lucenee的作者Doug Cutting将其贡献给Apache,成为Apache基金的一个子项目(http://jakarta.apache.org/lucene/)
c. 基于lucene开源搜索引擎出现了很多,例如(Apache Solr、Elastic Search、Index Tank、Katta、Bobo Search、Compass、Summa、Summa),它们都是使用lucene来实现的,让我们能够感受一下lucene的强大。
d. lucene只关注文本的索引和搜索,不处理语意,搜索时英文不区分大小写
e. 全文检索系统结构(从下图就可以领略到全文检索的精髓所在)。
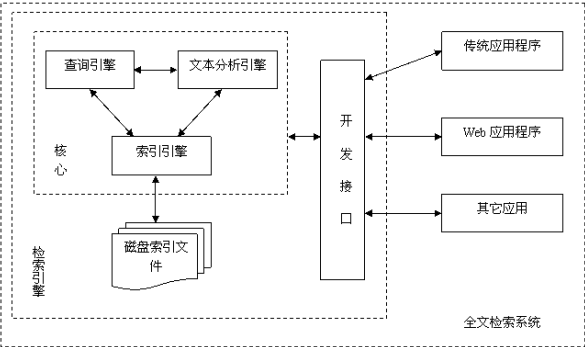
f. 关于lucene的Demo地址:https://github.com/kencery/Lucene_Compass(里面每个分支详细讲解了lucene的功能和实现)。
g. 博客中使用的图片大部分来源于网络,前辈们画的已经非常好,看图就能够理解了,自认为自己画的超不过前辈,故而拿来主义了。
3. 为什么使用lucene全文检索呢?
a. 假如信息检索系统在用户发出了检索请求后在去数据库中查找结果,根本无法再有限的时间内返回结果,所有要先把需要检索的资源放到本地,并且使用某种特定的数据结构存储,称为索引,这个索引的集合称之为索引库,由于索引库的结构是按照专门为快速查询设计的,所以查询的速度非常快,我们每次搜索都是在本地的索引库中进行,那么这时候就出现了数据集合和索引库的一致性,故而对于全文检索功能的开发,需要做的有两个方面:索引库管理(维护索引库中的数据)、在索引库中进行搜索,而Lucene就是操作索引库的工具。
b. lucene作为一个全文检索引擎,其具有以下优点:
b.1 索引文件独立于应用平台。lucene定义了一套以8位字节为基础的索引文件格式,使得兼容应用系统和不同平台都能够共享建立的索引文件。
b.2 在传统全文检索引擎倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度,然后通过和原来索引的合并,达到优化的目的。
b.3 优秀的面向对象的系统架构,使得对于lucene扩展的学习难度降低,方便扩展新的功能。
b.4 设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
b.5 已经默认实现了一套强大的查询引擎,用户无需自己编写代码即能够使系统获得强大的查询能力,Lucene查询实现中默认实现了关键字查询、范围查询、查询所有、通配符查询、模糊查询、短语查询、布尔查询。
c. 开源,可扩展能力强,有各种语言版本
4. Lucene系统结构以及包结构
a. 系统结构
a.1 lucene的系统由基础结构封装,索引核心,对外接口三大部分组成,其中直接操作索引文件的索引核心是整个lucene系统中的重中之重。

b. 包结构
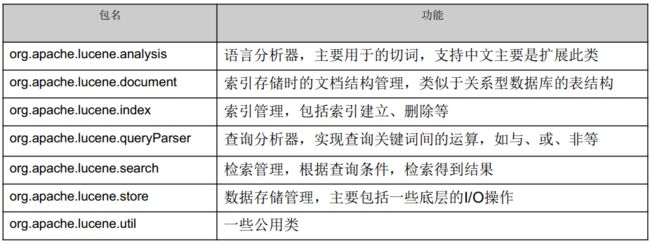
c. Lucene功能强大,但是从根本上来说,还是主要包含两块,一是文本内容经切词后索引入库,二是根据查询条件返回结果。
d. 搭建Lucene的开发环境需要加入Lucene的jar包,在项目开发中要加入的jar包至少要有一下几个:
lucene-core-5.5.0.jar、lucene-analyzers-common-5.5.0.jar、lucene-highlighter-5.5.0.jar、lucene-memory-5.5.0.jar、lucene-queryparser-5.5.0.jar
e. 对索引库的操作可以分为两种:管理和查询,管理索引库使用IndexWriter,从索引库中查询使用IndexSearcher。
5. 理解核心索引类
a. public abstract class org.apache.lucene.store.Directory
Directory类代表lucene索引的位置,它是一个抽象类,其中含有两个实现,第一个是FSDirectory,它表示一个存储在文件系统中的索引的位置,第二个是RAMDirectory,它表示一个存储在内存当中的索引的位置。
b. public abstract class org.apache.lucene.analysis.Analyzer
b.1 在一个文档被索引之前,首先需要对文档内容进行分词处理,并且剔除一些冗余的词句(例如:a,the,they等),这份工作就是有Analyzer来做的。
b.2 Analyzer类是一个抽象类,它有很多实现,请同时按住Ctrl+T查看。
b.3 针对不同的语言和应用需要选择适合的Analyzer,Analyzer把分词后的内容交给IndexWriter来建立索引。
c. public final class org.apache.lucene.index.IndexWriterConfig
在lucene3.X以上版本中,与前几个版本不同的地方包括了IndexWriter实例的初始化,其中需要用到IndexWriterConfig类,另外从Lucene的API中可以看到目前IndexWriter类最新的构造函数需要用到IndexWriterConfig类。
d. public final class org.apache.lucene.document.Document
d.1 Document文档类似数据库中的一条记录,可以由好几个字段(Field)组成,并且字段可以套用不同的类型
d.2 一个Field代表与这个文档相关的元数据,元数据如:作者,标题,主题,修改日期等等,分别作为文档的字段索引和存储。
d.3 Document的方法
(1) void add(IndexableField field) 添加一个字段(Field)到Document中
(2) String get(String name) 从文档中获得一个字段对应的文本。
e. public final class org.apache.lucene.document.TextField
e.1 TextField 对象使用来描述一个文档的某个属性的,比如一篇文章的作者和标题,可以用两TextField对象分别描述。
e.2 Field.Store—>表示Field的存储方式
(1) NO—>原文不存储在索引文件中,搜索结果命中后,在根据其他附加属性如文件的Path,数据库的主键等,重新链接打开原文,适合原文内容较大的情况。
(2) YES—>索引文件本来只存储索引数据,此设计将原文内容直接也存储在索引文件中,如文章的标题,内容。
f. public class org.apache.lucene.index.IndexWriter
f.1 IndexWriter是在索引过程中的中心组件
f.2 IndexWriter 这个类创建一个新的索引并且添加文档到一个已有的索引中,你可以把IndexWriter想象成让你可以对索引进行写操作的对象,但是不能让你读取或搜索。
f.3 IndexWriter不是唯一的用来修改索引的类。
6. 创建一个索引的大致实现
a. 代码以在github上开源,地址:https://github.com/kencery/Lucene_Compass
b. 在建立索引时,先要把文档存到索引库中,还要更新词汇表。
1 /** 2 3 * 为文章建立索引 4 5 * @throws IOException 6 7 */ 8 9 @Test 10 11 public void testCreateIndex() throws Exception { 12 13 //1 将需要添加的实体构造成实体对象 14 15 Article article=new Article(1, "Lucene是全文检索框架", 16 17 "全文检索(Full-Text Retrieval)是指以文本作为检索对象,找出含有指定词汇的文本。" + 18 19 "全面、准确和快速是衡量全文检索系统的关键指标。"); 20 21 //2 保存到数据库(此步骤暂时省略) 22 23 //3 建立索引(lucene) 24 25 Directory directory=FSDirectory.open(Paths.get("./indexDir/")); //索引库目录 26 27 Analyzer analyzer=new IKAnalyzer(); //分词器 28 29 IndexWriterConfig iwc= new IndexWriterConfig(analyzer); 30 31 // >>3.1 将Article转为Document 32 33 /** Store参数说明 34 35 No 本字段的原始值不存储 36 37 YES 本字段的原始值会存在出在数据库区中 38 39 如果不存在,则搜索出来的结果中这个字段的值为null */ 40 41 /** 42 43 * 自Lucene4开始 创建field对象使用不同的类型 只需要指定是否需要保存源数据 不需指定分词类别 44 45 * 之前版本的写法如下 46 47 * doc.Add(new Field("id", article.id.ToString(), Field.Store.YES, Field.Index.ANALYZED)); 48 49 */ 50 51 Document doc=new Document(); 52 53 doc.add(new TextField("id", article.getId().toString(), Store.YES)); 54 55 doc.add(new TextField("title", article.getTitle(), Store.YES)); 56 57 doc.add(new TextField("content", article.getContent(), Store.YES)); 58 59 // >>3.2 保存到索引库中 60 61 IndexWriter indexWriter=new IndexWriter(directory,iwc); 62 63 indexWriter.addDocument(doc); 64 65 indexWriter.close(); //释放资源 66 67 }
c. 索引设置建议
c.1 尽量减少不必要的存储(不需要的字段就不要存储在索引库中)
c.2 不需要检索的内容建议不要建立索引
c.3 非文本格式需要提前转化
7. FSDirectory和RAMDirectory的区别
a.Lucene的索引存储位置使用的是一个接口(抽象类),也就可以实现各种各样的实际存储方式(实现类,子类),比如存放在文件系统中,存放在内容中,存放在数据库中等,Lucene提供了两个子类:FSDirectory和RAMDirectory
a.1 FSDirectory 存放在文件系统中,是真实的文件夹和文件。
a.2 RAMDirectory 存放在内存中,是模拟的文件夹和文件,与FSDirectory相比含有一下差异(1.因为没有IO曹邹,所以速度快,2.因为在内存中存放,所以在程序退出后索引库数据就不存在了)。
希望大家能从中间学到东西,如有疑问,请留言或者去GitHub上看LuceneDemo或者添加我的QQ,我们共同探讨。