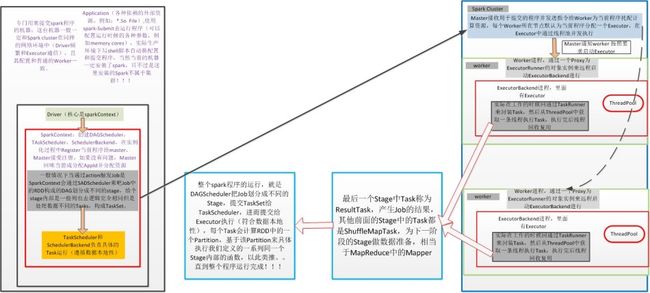
Spark内核架构
SparkContext创建:高层DAGScheduler, 底层TaskScheduler, SchedulerBackend
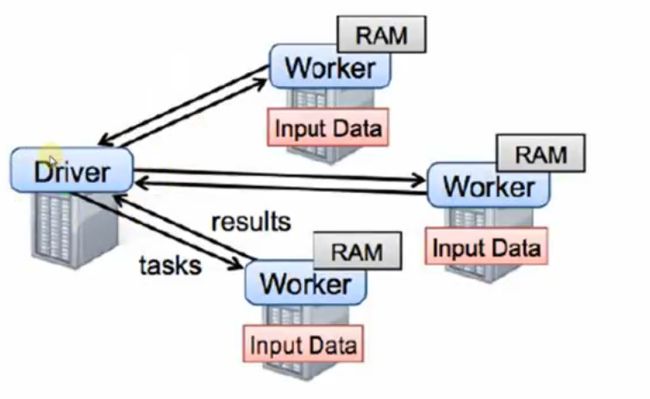
application=driver+executor
Spark的程序分成两个部分:driver和executor
driver驱动executor
Driver部分的源代码:SparkConf+SparkContext
executor具体执行
Executor部分的具体源代码:textFile flatMap map等等…
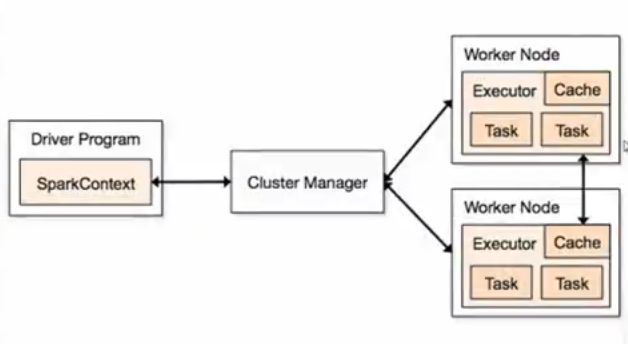
Cluster Manager
集群中获取外部资源的服务,资源分配器
spark application的运行不依赖于Cluster Manager,如果注册是成功的,已经通过clustermanager分配好了资源,运行中是不需要cluster manage(可插拔)r的参与,是粗粒度的资源分配方式
一个Application里面可以有多个Jobs
Worker(节点)不会运行代码,管理当前节点cpu使用状况,接收master分配资源(filter指令),通过ExecutorRunner具体跑进程,
Worker本身是一个进程,Worker上是不会运行程序的代码,worker是管理当前节点的内存、cpu等资源使用状况的,并接受mater的具体指令来分配具体的计算资源executor(在新的进程中分配),executor里线程并行的执行
Worker管理当前Node的资源,并接受Master的指令来分配具体的计算资源Executor(在新的进程中分配)
ExecutorRunner
在worker上,是一个Proxy,远程创建出线程
Worker本身不会向master报告当前节点的内存和cpu,worker和master的心跳中只有worker_id,没有资源信息在里面。
Master分配的时候会知道Worker的资源情况,再动态调整资源。
Executor 中Task从内存或磁盘读取数据
executor是运行在worker上,为当前应用程序执行的进程里的一个对象,executor通过线程池运行task,实现线程池并发和线程复用
一个worker默认为当前的一个程序执行一个executor。
不设置的情况下,core是全部独占,只要有个作业执行不完成,下一个任务就没有资源
注:(1)worker是工头,cluster manager是项目经理
(2)worker不会向master汇报资源,只有在故障时说资源发生故障
job由action触发
job->DAG->stage->task
Stage内部:计算逻辑完全一样,只是计算的数据不同罢了
job是包含了一系列task的并行计算,一般由action触发。一系列RDD的操作被action触发job作业按序执行。
一个Application里面可以有多个job,因为可以有不同的action,一般一个action对应一个job(因为checkpoint也会产生job)。runjob产生DAG,一个DAG包含多个stage,一个stage包含多个task,由shuffle划分stage
一个job默认在每个节点上有一个executor
Spark快并不是因为基于内存,而是因其调度,容错等特点
一般一个action就是一个job
两个tasks,两个executor
Spark程序的运行,有两种模式:Client和Cluster
默认为client模式,能看到日志信息,一般专门找一台节点来提交,必须和cluster在同一个网络环境中,且配置和worker一致。
生产环境中:因为driver要有频繁的网络交互且占用内存和cpu的资源,一般不建议在master上执行driver(spark集群环境不要在idea上提交运行),也就是提交sparkjob的机器不在master上提交
Spark程序的提交:
专门用来提交spark程序的机器:这台机器一般一定和Spark Cluster在同样的网络环境中(Driver频繁和Executors通信),且其配置和不同的Worker一致。
Application(各种依赖的外部资源,例如*.so File jar),使用spark-submit去运行程序(可以配置运行时候的各种参数,例如memory cores…),实际生产环境下写shell脚本自动化配置和提交程序,当然当前的机器一定安装了Spark,只不过是这里安装的spark不属于集群!!
spark任务的提交:
Driver(核心是SparkContext),先创建SparkConf,在此基础上创建SparkContext
akka和netty实现rpc
SparkContext:创建DAGScheduler, TaskScheduler, SchedulerBackend, 在实例化的过程中Register当前程序给Master,Master接受注册,如果没有问题,Master会为当前程序分配AppId并分配计算资源。
一般情况下当通过action触发Job时Spark Context会通过DAGScheduler来把Job中的RDD构成的DAG划分为不同的Stage,每个Stage内部是一系列业务逻辑完全相同但是处理数据不同的Tasks,构成了TaskSet。
TaskScheduler和SchedulerBackend负责具体的Task运行(遵循数据本地性)
- Spark Cluster
Master:接受用户提交的程序并发送指令给Worker为当前程序分配计算资源,每个Worker所在节点默认为当前程序分配一个Executor,在Executor中通过线程池并发执行
Spark运行在节点上占用的内存和cpu资源数量依赖于:
1,spark-env.sh和spark-defaults.sh
2,spark-submit提供的参数
3,程序中SparkConf配置的参数
冲突时,优先顺序:3>2>1
Worker Node
Worker进程,通过一个Proxy为ExecutorRunner的对象实例来远程启动ExecutorBackend进行
ExecutorBackend进程,里面有Executor,线程池ThreadPool
实际在工作的时候会通过TaskRunner来封装Task,然后从ThreadPool中获取一条线程执行Task,执行完后线程被回收复用
最后一个Stage中Task称为ResultTask,产生Job的结果,其他前面的Stage中的Task都是ShuffleMapTask,为下一个阶段的Stage做数据准备,相当于MapReduce中的Mapper。
整个Spark程序的运行,就是DAGScheduler把Job划分成不同的Stage,提交TaskSet给TaskScheduler,进而提交给Executor执行(符合数据本地性),每个Task会计算RDD中的一个Partition,基于该Partition来具体之心给我们定义的一系列同一个Stage内部的函数,以此类推…直到整个程序运行完成。
总结:
运行节点 -> spark-submit ->driver -> SparkContext ->DAGScheduler&TaskScheduler&SchedulerBackend ->DAGScheduler将job划分Stage -> Stage内部划分Task组成TaskSet ->TaskSheduler和SchedulerBackend负责执行TaskSet -> register job tomaster -> master 接受之后,分配appId和计算资源 ->master将用户提交的程序发送指令给Worker分配计算资源 -> worker默认启动一个executor给一个程序-> worker进程通过proxy为executorRunner对象实例远程启动executorBackend-> executorBackend里面有Executor ->executor通过TaskRunner封装Task -> executor从ThreadPool线程池获取一条线程执行Task-> 每个Task计算RDD中的一个Partition -> 执行完成后线程回收复用 -> 下一个Task,循环直到整个程序运行完成 ->最后一个Stage中的Task称为ResultTask(前面Stage中的Task都是ShuffleMapTask,为下一个Stage做数据准备),生成job的结果