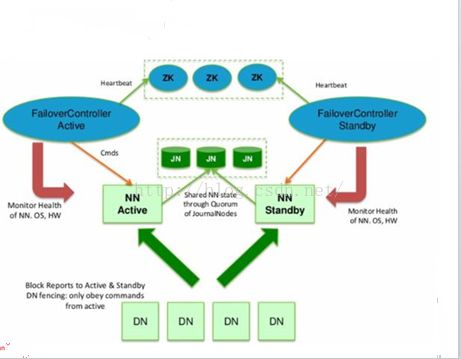
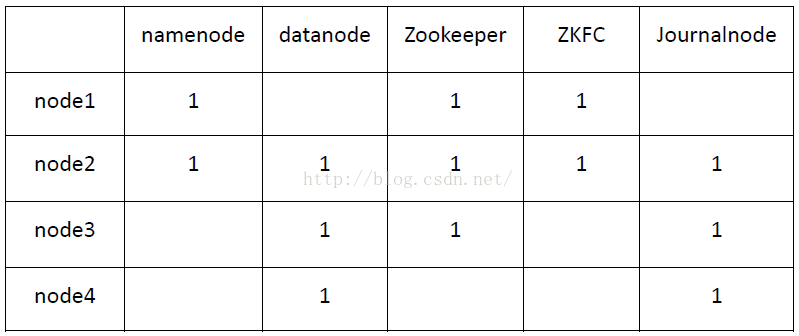
Hadoop完全分布式+HA配置
./hdfs dfs -put /cong/temp/hello.txt /cong/tmp
运行jar包
./hadoop jar /cong/temp/WordCount.jar cong.mr.JobRun /cong/tmp/hello.txt /cong/tmp/wcout
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
然后如做node1到node2的免密码登录则执行以下命令:
首先将node1的公钥文件拷贝至node2:
scp ~/.ssh/id_dsa.pub root@node2:/root/
cat /root/id_dsa.pub >> /root/.ssh/authorized_keys本人遇到过The authenticity of host *** can’t be established ,需要输出一个“yes”的交互,试过网上的方法不行,本
人修改了相应节点的IP地址解决了。
2、./hdfs zkfc -formatZK遇到错误如下:
16/05/08 21:01:39 INFO zookeeper.ClientCnxn: Opening socket connection to server node2/192.168.17.3:2181. Will not attempt to authenticate using SASL (unknown error)
16/05/08 21:01:40 INFO zookeeper.ClientCnxn: Socket connection established to node2/192.168.17.3:2181, initiating session
16/05/08 21:01:40 INFO zookeeper.ClientCnxn: Unable to read additional data from server sessionid 0x0, likely server has closed socket, closing socket connection and attempting reconnect
16/05/08 21:01:40 INFO zookeeper.ClientCnxn: Opening socket connection to server node3/192.168.17.4:2181. Will not attempt to authenticate using SASL (unknown error)
16/05/08 21:01:40 INFO zookeeper.ClientCnxn: Socket connection established to node3/192.168.17.4:2181, initiating session
16/05/08 21:01:40 INFO zookeeper.ClientCnxn: Unable to read additional data from server sessionid 0x0, likely server has closed socket, closing socket connection and attempting reconnect
16/05/08 21:01:41 INFO zookeeper.ClientCnxn: Opening socket connection to server node1/192.168.17.2:2181. Will not attempt to authenticate using SASL (unknown error)
16/05/08 21:01:41 INFO zookeeper.ClientCnxn: Socket connection established to node1/192.168.17.2:2181, initiating session
16/05/08 21:01:41 INFO zookeeper.ClientCnxn: Unable to read additional data from server sessionid 0x0, likely server has closed socket, closing socket connection and attempting reconnect
解决方法:
看看自己是不是在/etc/hosts设置文件里给127.0.0.1配置了像node2这样的主机名,去掉127.0.0.1额外配的主机名便好。当然还有些其他导致此错误的可能原因:比如zookeeper节点数目不是大于1的奇数(好像会有这种错误)
3、 datanode无法启动这个问题一般是由于两次或两次以上的格式化NameNode造成的,尝试删除将集群中每个datanode的/hdfs/data/current中的VERSION删掉,然后执行hadoop namenode -format重启集群。4、执行jar包时遇到如下错误:org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container原因:namenode,datanode时间同步问题;解决方法:若节点均已联网,在每台服务器上执行:ntpdate time.nist.gov (不行就是用国内速度比较快的nt服务器http://blog.csdn.net/huang_xw/article/details/8711037)vmware NET模式节点联网问题参照http://www.2cto.com/os/201109/103214.html 注意最后域名无法解析的部分!ntpdate 直接加ntp服务器的ip便可解决!(本人用的为:ntpdate 202.118.1.81)5、启动集群后两个namenode的状态全部都是standby解决方法:简单粗暴:强制切换namenode状态 ./hdfs haadmin -transitionToActive -forcemanual nn1nn1为配置时为namenode所起的服务名!